加州大学伯克利分校研究团队近日发布了其最新的研究成果——TULIP (Towards Unified Language-Image Pretraining)模型。该模型旨在提升视觉语言预训练的性能,特别是在需要高保真理解的视觉中心任务中,克服了现有对比学习模型(如CLIP)的局限性。
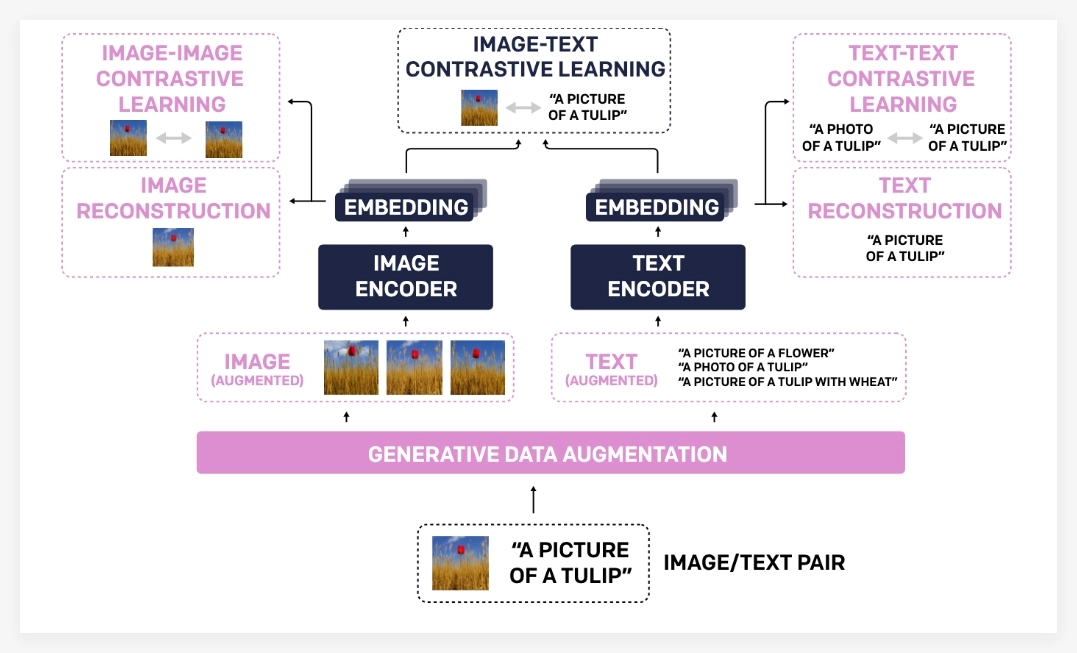
TULIP通过集成生成式数据增强、增强的对比学习以及重构正则化等创新技术,显著提升了视觉和语言之间的对齐能力。实验结果表明,TULIP在多个基准测试中均取得了最先进的性能,为零样本分类和视觉语言推理树立了新的标杆。
TULIP模型之所以能够取得如此显著的进步,主要归功于其独特的技术组合:
通过这三大核心技术的协同作用,TULIP模型在理解图像内容的同时,也保持了强大的语言理解能力,实现了更鲁棒的视觉语言对齐。
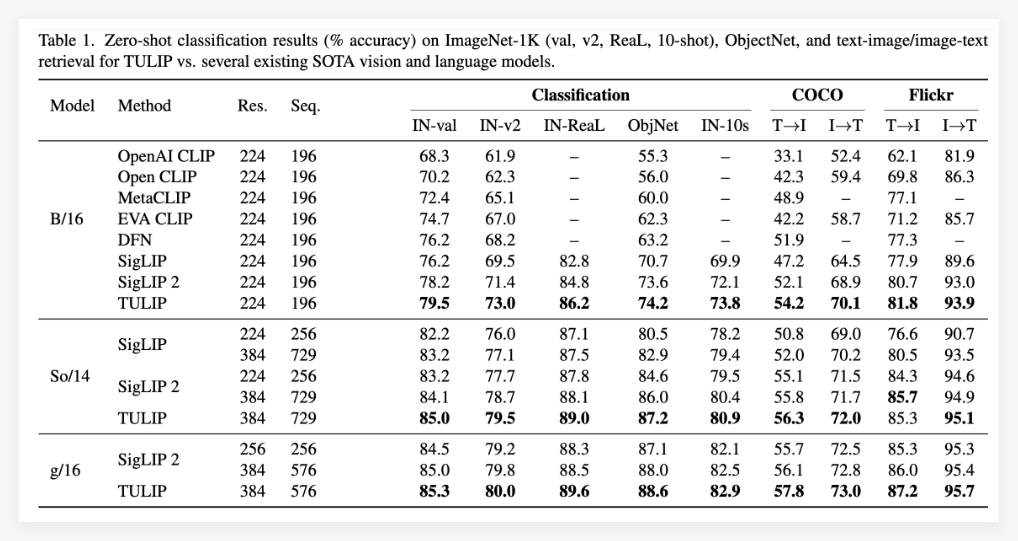
实验结果充分证明了TULIP模型的优越性。据报道,TULIP在多个重要的视觉和视觉语言基准测试中均达到了当前最优水平 (state-of-the-art)。具体表现包括:
尤其值得一提的是,TULIP相较于现有方法,在MMVP基准测试中取得了高达3倍的性能提升,并且在微调的视觉任务上也实现了2倍的性能提升。这些数据充分表明了TULIP在提升模型性能方面的巨大潜力。
项目:https://tulip-berkeley.github.io/