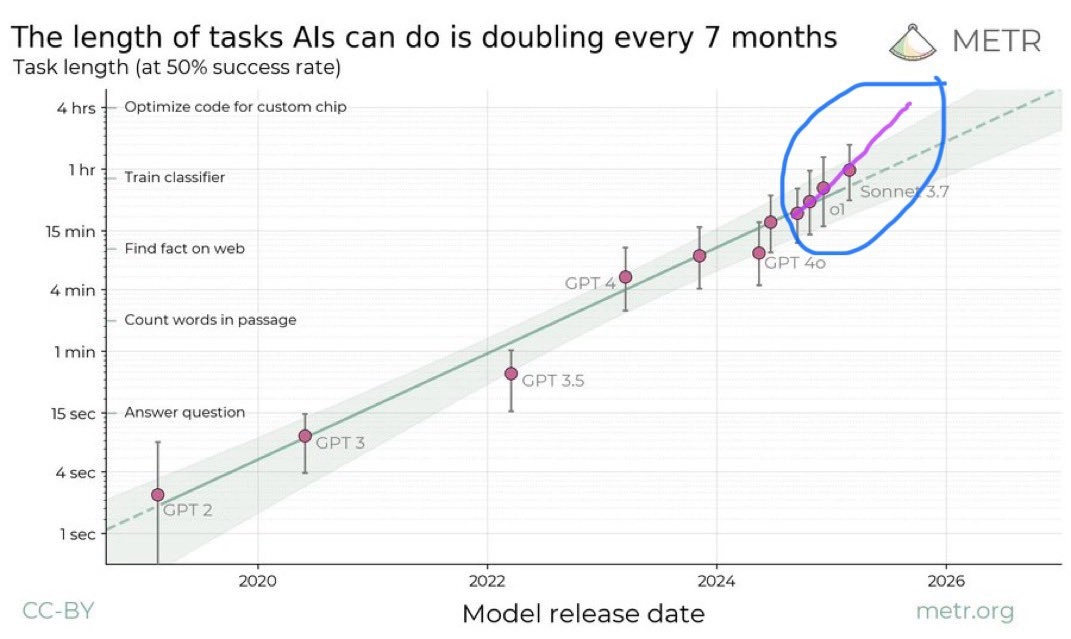
METR 的研究人员刚刚发布的最新研究显示,自 2019 年以来,人工智能代理能够自主完成的任务的长度大约每 7 个月翻一番,揭示了人工智能能力的“摩尔定律”。
以 AI 可以独立完成的任务长度(由人类完成同样任务所需时间衡量)作为评估标准。研究发现,在过去 6 年中,该指标呈现稳定的指数增长,翻倍时间约为 7 个月。如果这一趋势持续,预计 在未来 2-4年内,AI 代理将能够独立完成当前人类需要数天甚至数周完成的任务。
该研究跟踪了人类和 AI 在 170 项软件任务 上的表现,这些任务涵盖了 从 2 秒决策到 8 小时工程挑战 的广泛范围。
- 顶级模型(如 Claude 3.7 Sonnet)的“时间跨度”为 59 分钟,即它能够以 至少 50% 的成功率 完成需要熟练人类 59 分钟 才能完成的任务。
- 较旧的模型(如 GPT-4)可以完成 需要人类 8-15 分钟 的任务,而 2019 年的 AI 系统 只能处理 几秒钟 级别的任务。
- 如果指数增长趋势持续,预计 到 2030 年,AI 将能够 以合理的可靠性 独立完成 需要人类一个月时间的任务。
Moore 定律的类比
摩尔定律(Moore's Law)预测 计算能力大约每两年翻倍,这解释了为什么计算设备的速度越来越快,成本越来越低。
为什么重要
- 发现 AI 能力增长的 可预测模式 为行业提供了 重要的前瞻性预测工具。
- 未来 AI 能够独立完成数月级别的任务,将 彻底改变全球企业对 AI 和自动化的应用方式。
研究发现
AI 能完成的任务长度呈指数增长
- 过去 6 年里,AI 在 50% 可靠性下能完成的任务长度大约每 7 个月翻倍。
如果这一趋势持续:
- 未来 2-4 年内,AI 可能能独立完成需要 1 周时间的人类任务。
- 到 2030 年左右,AI 可能能独立完成需要 1 个月时间的人类任务。
该增长趋势在多个数据集上得到了验证
研究人员在不同的任务数据集上复现了这一趋势:
- HCAST、RE-Bench(不同长度和复杂度的任务集)。
- SWE-Bench Verified(基于真实软件开发任务),其中翻倍时间甚至更短,为 3 个月。
预测 AI 达到更高能力的时间点
研究人员进行了不确定性分析,发现即使数据误差达到 10 倍,也仅会影响最终 AI 达成目标的时间点约 2 年。
各方反应
来自前 OpenAI 研究员、优秀预测者 Daniel Kokotajlo 的评论:
原推
Daniel Kokotajlo(@DKokotajlo67142) - 3月19日
这可能是目前关于 AGI 时间表最重要的单一证据。干得好!我认为这个趋势应该是超指数级的,例如,每次翻倍所需的日历时间平均减少 10%。@eli_lifland 和我昨天做了一些计算,结果表明 AGI 可能会在 2028 年出现。我们很快会进行更严谨的调查。
来自 Epoch AI Research 的 Jaime Sevilla 的评论:
原推
Jaime Sevilla(@Jsevillamol) - 3月19日
这是 AI 时间表方面我最近遇到的最重大更新。几乎无可争议的证据表明,AI 能力在十年内有望达到 1 个月的任务时间跨度。
来自 ARIA Research 的 davidad 的评论:
原推
davidad 🎇(@davidad) - 3月19日
我的看法:
- 我认为,合成数据自我改进(例如在可验证奖励的 CoT 强化学习)正在引发新的增长模式(见图)。
50% 的成功率大致对应于 pass@2。在无法作弊的奖励机制下,pass@k 变成了一个成本问题;pass@8 可能是值得的。
Miles Brundage 发表了一条很棒的推文,提出了一些关键分歧
原推
Miles Brundage(@Miles_Brundage) - 3月19日
🚨 🚨 重要论文预警 🚨 🚨这是近年来关于 AI 进展最有趣的分析之一,至少看看 METR 的推文吧,如果有时间的话,也可以阅读博客文章和论文。
下面是我在阅读后的一些额外想法 🧵
我的一些观点:
1️⃣ 长期趋势可能低估了当前和未来的进展,主要原因是推理时的计算资源问题。他们在论文中有所讨论,但我想强调这一点。2024-2025 年的预测可能是最接近现实的,但进展可能会更快。
2️⃣ 论文中关于代码能力与其他评估指标之间的历史相关性并不令人信服。我确实认为其他领域的进展会很快,但可能不会像代码和数学那样快,至少基于这项研究无法得出这样的结论。因此,这应该被理解为针对代码的趋势,而不是 AI 整体进展的趋势。
3️⃣ 我对论文关注“一个月任务时长”的观点持保留态度。@RichardMCNgo 的 t-AGI 文章提供了一个有用的框架和灵感,但其论述尚不够成熟,无法作为可靠依据。在某些情况下(例如多智能体系统架构),模型级别的任务时长小于一个月是可以接受的,反之亦然。
4️⃣ 尽管有这些限制,这项研究仍然非常有价值。
- 就论文的核心内容(代码能力)而言,与更广泛的泛化能力相比,研究结果是可靠的。
- 我很期待看到这种方法推广到更多评估领域,例如不同的计算资源条件、任务类型等。
5️⃣ 关于推理计算资源的重要性,我预测 GPT-5 在高推理计算资源设定下(例如类似工程师市场价位的提示优化、思维链推理长度等),其表现将超出论文中的趋势预测。
全文翻译
摘要: 我们提出以任务的 长度 来衡量 AI 代理的性能。我们的研究表明,在过去 6 年里,该指标一直在稳定地指数增长,翻倍时间约为 7 个月。按照这一趋势预测,在不到五年的时间内,我们将看到 AI 代理能够独立完成当前需要人类数天或数周的许多软件任务。
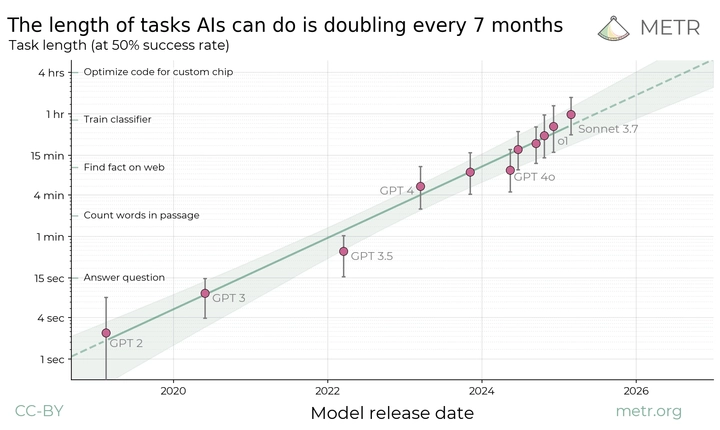
一般化前沿模型代理能够以 50% 的可靠性自主完成的任务长度(以人类专业人士完成这些任务所需时间衡量)在过去 6 年里大约每 7 个月翻倍一次。阴影区域表示基于层次自助采样(hierarchical bootstrap)计算的 95% 置信区间,该计算涵盖了任务类别、具体任务以及任务尝试。
我们认为,预测未来 AI 系统的能力对于理解和应对强大 AI 的影响至关重要。然而,预测能力趋势并不容易,即使是理解当今模型的能力也充满挑战。
当前的前沿 AI 在文本预测和知识任务方面远超人类,在大多数考试型问题上以极低的成本击败专家。通过针对特定任务的适应性调整,它们也能在许多应用场景中作为有用的工具。然而,目前最先进的 AI 代理仍然无法独立执行复杂项目或直接替代人类劳动。即便是在较低技能要求的计算机辅助工作(如远程行政助理)中,它们的表现也不够可靠。这表明 AI 能力在某些方面增长迅速,但如何将其转化为实际影响仍然不清楚。
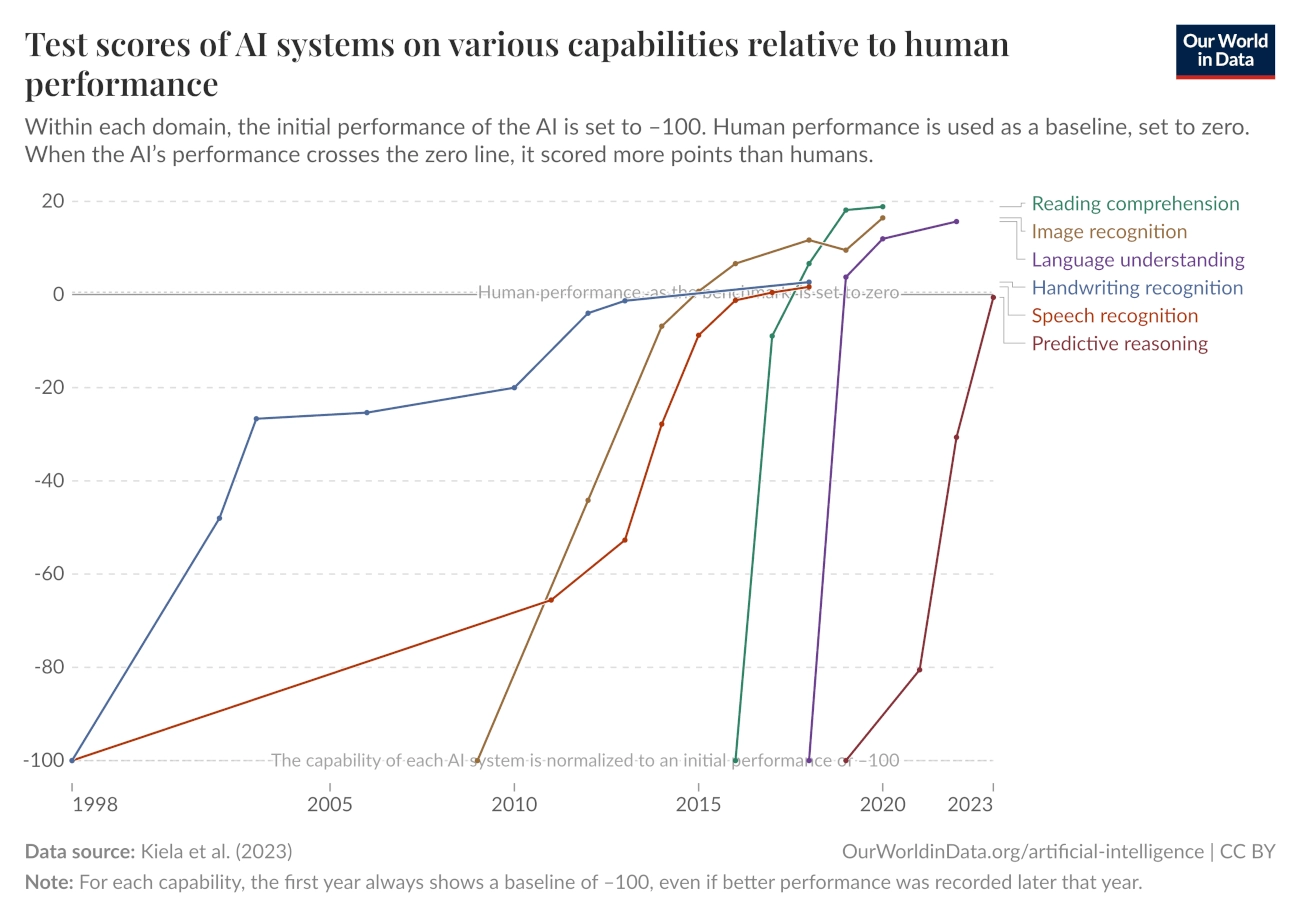
AI 在许多不同领域的基准测试中表现迅速提升。然而,将这种表现的增长转化为 AI 在现实世界中的实际用途预测仍然具有挑战性。
我们发现,测量模型可以完成的任务长度是理解当前 AI 能力的一个有用视角。这很合理:AI 代理在执行更长的操作序列时往往遇到困难,而不是缺乏解决单个步骤所需的技能或知识。
在一组多步骤的软件和推理任务上,我们记录了人类专家完成这些任务所需的时间。我们发现,人类专家完成任务所需的时间与 AI 成功率之间存在强相关性:当前模型在需要人类不到 4 分钟的任务上几乎 100% 成功,而在需要人类超过 4 小时的任务上,成功率低于 10%。这使我们能够用 “模型能以 x% 的概率成功完成的任务长度(以人类完成这些任务所需时间衡量)” 来表征 AI 的能力。
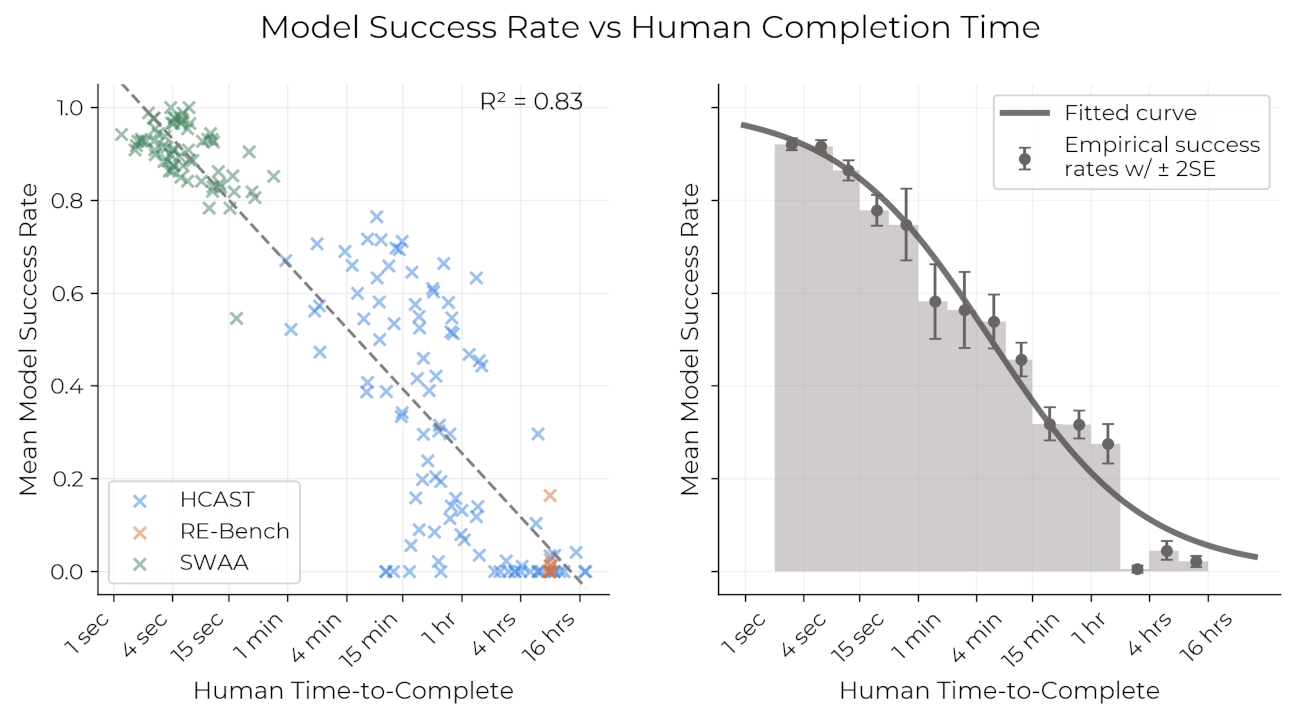
对于每个模型,我们可以拟合一个逻辑曲线来预测模型的成功概率与任务长度的关系。在固定成功概率后,我们可以将每个模型的预测成功曲线转换为时间跨度,即查看该曲线与目标成功率交叉的任务长度。例如,以下是几个模型的拟合成功曲线,以及我们预测其 50% 成功率对应的任务长度:
该图展示了计算时间跨度的过程。例如,Claude 3.7 Sonnet(最右侧、最深绿色的模型)的时间跨度约为 1 小时,即其拟合逻辑曲线与 50% 成功概率交叉的位置。
这些结果有助于解释当前 AI 在许多基准测试上表现超越人类,但在现实世界中仍无法稳定地自动完成大部分日常任务的矛盾现象。当前最先进的模型(如 Claude 3.7 Sonnet)可以完成部分需要专家数小时的任务,但只能可靠地完成几分钟以内的任务。
尽管如此,从历史数据来看,最先进模型能够完成的任务长度(以 50% 概率)在过去 6 年内已大幅增长。
如果我们将数据绘制在对数刻度上,可以看到任务长度的增长趋势符合指数规律,其翻倍时间约为 7 个月。
我们估计 AI 代理能够完成的任务长度取决于具体的方法选择,例如使用的任务集和测量的人类基线。然而,我们对整体趋势的准确性相当有信心,其翻倍速率约为每年 1 到 4 次。如果过去 6 年的趋势在未来 2 到 4 年内持续,那么通用自主代理将能够执行为期一周的大量任务。
这一趋势的陡峭程度意味着,即使测量误差较大或模型与人类的对比存在误差,对 AI 未来能力到达时间点的预测仍然相对稳健。例如,如果我们的测量值存在 10 倍误差,仍然只会影响最终预测的时间点约 2 年。
我们在完整论文中讨论了这些结果的局限性,并详细介绍了各种稳健性检查和敏感性分析。简而言之,我们发现类似的趋势也适用于:
各种不同类型的任务数据集(例如,超短软件任务、HCAST、多样化任务 RE-Bench 以及基于任务长度或“混乱程度”筛选的子集)。
一个基于真实任务的独立数据集(SWE-Bench Verified),其中人类完成时间基于独立估算而非实验基线数据。该数据集显示 AI 的翻倍时间甚至更短,不到 3 个月。2
结论
我们认为这项研究对 AI 基准测试、预测和风险管理具有重要意义。
首先,我们的研究提出了一种改进基准测试的方法:通过测量 AI 可以完成的任务长度(以人类完成该任务所需时间衡量),我们可以衡量模型能力在广泛的任务和领域中的进步,同时提供清晰的现实世界解释。
其次,我们发现 AI 在这一重要指标上的能力增长呈现稳健的指数趋势。如果这一趋势持续到本世纪末,前沿 AI 系统将能够自主完成为期一个月的项目,这将带来巨大的潜在收益和风险。4
原文:https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks