近日,小米大模型团队在音频推理领域的研究中取得了突破性进展,成功应用强化学习算法于多模态音频理解任务,准确率达到了64.5%,这一成就使其在国际权威的 MMAU 音频理解评测中夺得了第一名。这一成果的背后,离不开团队对 DeepSeek-R1的启发。
MMAU(Massive Multi-Task Audio Understanding and Reasoning)评测集是衡量音频推理能力的重要标准,通过对包含语音、环境声和音乐的多种音频样本进行分析,测试模型在复杂推理任务中的表现。人类专家的准确率为82.23%,而当前榜单上表现最好的模型是 OpenAI 的 GPT-4o,准确率为57.3%。在这样的背景下,小米团队的成绩尤为引人注目。
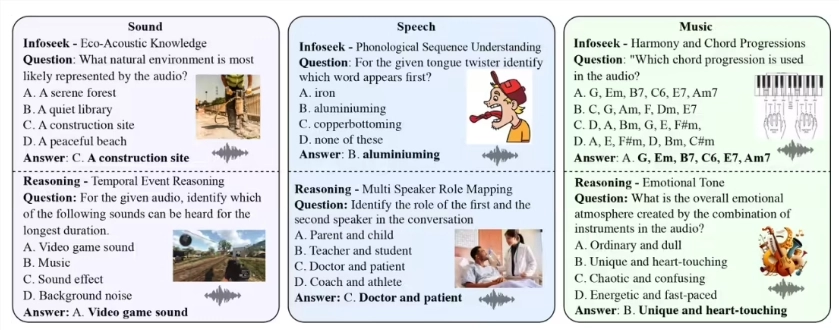
在团队的实验中,他们采用了 DeepSeek-R1的 Group Relative Policy Optimization(GRPO)方法,该方法通过 “试错 - 奖励” 的机制,使得模型能自主演化,展现出类似于人类的反思和推理能力。值得注意的是,在强化学习的支持下,即便只使用了3.8万条训练样本,小米团队的模型仍然能够在 MMAU 评测集上取得64.5% 的准确率,比当前的第一名高出近10个百分点。
此外,实验还发现,传统的显式思维链输出方式反而会导致模型准确率下降,显示出隐式推理在训练中的优势。尽管取得了显著的成绩,但小米团队仍然意识到,距离人类专家的水平还有一段距离。团队表示将继续优化强化学习策略,以期实现更好的推理能力。
这项研究的成功,不仅展示了强化学习在音频理解领域的潜力,也为未来的智能听觉时代铺平了道路。随着机器不仅能 “听见” 声音,还能 “听懂” 其背后的因果逻辑,智能音频技术将迎来新的发展机遇。小米团队还将开源训练代码和模型参数,以便于学术界和产业界的进一步研究与交流。
训练代码:https://github.com/xiaomi-research/r1-aqa
模型参数:https://huggingface.co/mispeech/r1-aqa
技术报告:https://arxiv.org/abs/2503.11197
交互 Demo:https://120.48.108.147:7860/