今日,豆包大模型团队正式发布文生图技术报告,首次公开Seedream2.0图像生成模型的技术细节,涵盖数据构建、预训练框架、后训练RLHF全流程,在文生图领域投下一颗“重磅炸弹”。
Seedream2.0自2024年12月初在豆包APP和即梦上线后,已服务上亿C端用户,深受专业设计师青睐。与Ideogram2.0、Midjourney V6.1等主流模型相比,它解决了文本渲染不佳、对中国文化理解不足等问题,在中英文双语理解、美感和指令遵循等方面实现全面提升。


通过Bench-240评测基准测试,其英文提示词生成内容的结构合理性、文本理解准确性更胜一筹;中文生成与渲染文字可用率达78%,完美响应率为63%,远超业界其他模型。

在技术实现上,团队进行了多方面创新。数据预处理环节,构建以“知识融合”为核心的框架。四维数据架构平衡数据质量与知识多样性,智能标注引擎实现三级认知进化,提升模型理解和识别能力,工程化重构则大幅提高数据处理效率。
预训练阶段,团队聚焦双语理解与文字渲染。原生双语对齐方案,通过微调LLM和构建专用数据集,打破语言视觉次元壁;双模态编码融合系统让模型兼顾文本语义和字体字形;三重升级DiT架构,引入QK-Norm和Scaling ROPE技术,提升训练稳定性,实现多分辨率图像生成。
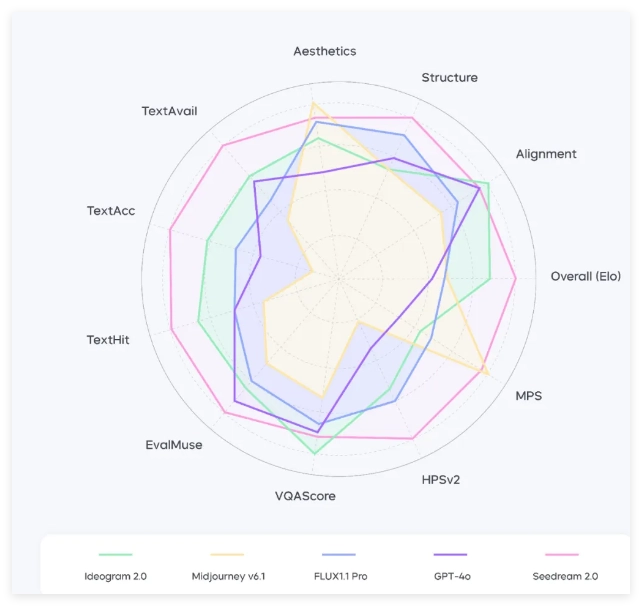
注:面向英文提示词,Seedream2.0在不同维度上的表现。本图各维度数据以最佳指标为参照系,已进行归一化调整。
后训练RLHF过程中,团队开发优化系统,从多维度偏好数据体系、三个不同奖励模型、反复学习驱动模型进化三方面发力,有效提升模型性能,不同奖励模型的表现分数值在迭代中稳步上升。
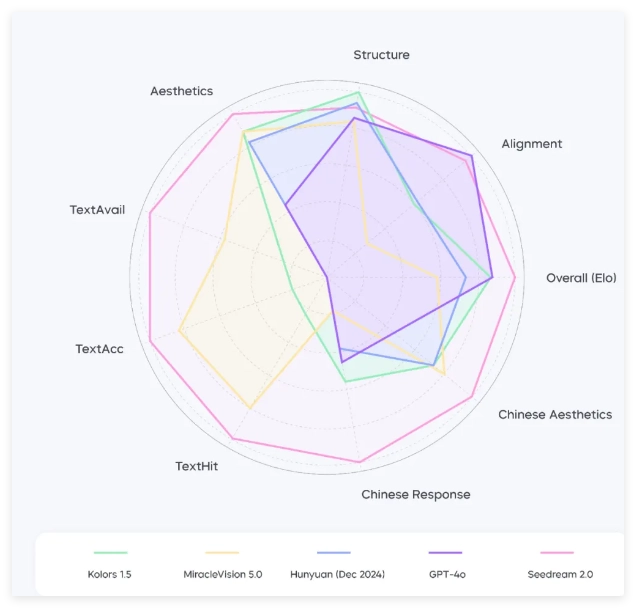
注:面向中文提示词,Seedream2.0在不同维度上的表现。本图各维度数据以最佳指标为参照系,已进行归一化调整。
此次技术报告的发布,彰显了豆包大模型团队推动图像生成技术发展的决心。未来,团队将继续探索创新技术,提升模型性能边界,深入研究强化学习优化机制,持续分享技术经验,助力行业蓬勃发展。
技术展示页:https://team.doubao.com/tech/seedream
技术报告:https://arxiv.org/pdf/2503.07703