Google 推出了一个新的实验性文本嵌入模型“gemini-embedding-exp-03-07”,现已通过 Gemini API 提供给开发者使用。
这一模型在语言理解和语义捕捉方面表现出色,超越了之前的顶级模型,并在多语言嵌入基准测试中名列前茅。
✅ 适用于文本搜索、推荐、分类等场景
✅ 支持 100+ 语言,超越所有现有多语言嵌入模型
✅ 在 Massive Text Embedding Benchmark(MTEB)中排名第一
✅ 相比以往模型,输入 token 量提升至 8K,向量维度提升至 3K
✅ 适用于搜索引擎、AI 推荐系统、问答系统、知识图谱等
什么是 Gemini Embedding?
Gemini Embedding 是 Google 最新的文本嵌入(Embedding)模型,用于 将文本转换为数值向量,让 AI 更好地理解语义和上下文。
💡 主要用途:
- 提高搜索、推荐系统、文本分类、文本相似度计算的效果
- 替代传统关键词匹配方法,增强语义理解能力
- 提高 AI 模型的效率和准确度,降低计算成本
🔍 文本嵌入的主要应用:

📌 例如: 🔹 传统方法:搜索“苹果”,可能得到“苹果公司”和“苹果水果”的混合结果
🔹 Embedding 方法:能理解“苹果公司” ≠ “苹果水果”,从而提供更精准的搜索
应用场景:
- 高效检索:在大型数据库中查找相关文档,例如法律文档检索或企业搜索。
- 检索增强生成 (RAG):通过检索相关上下文提升生成文本的质量和相关性。
- 聚类与分类:将相似文本分组,用于趋势识别或主题分类。
- 文本相似性:检测重复内容,支持网页去重或抄袭检测。
Gemini Embedding 模型的特点
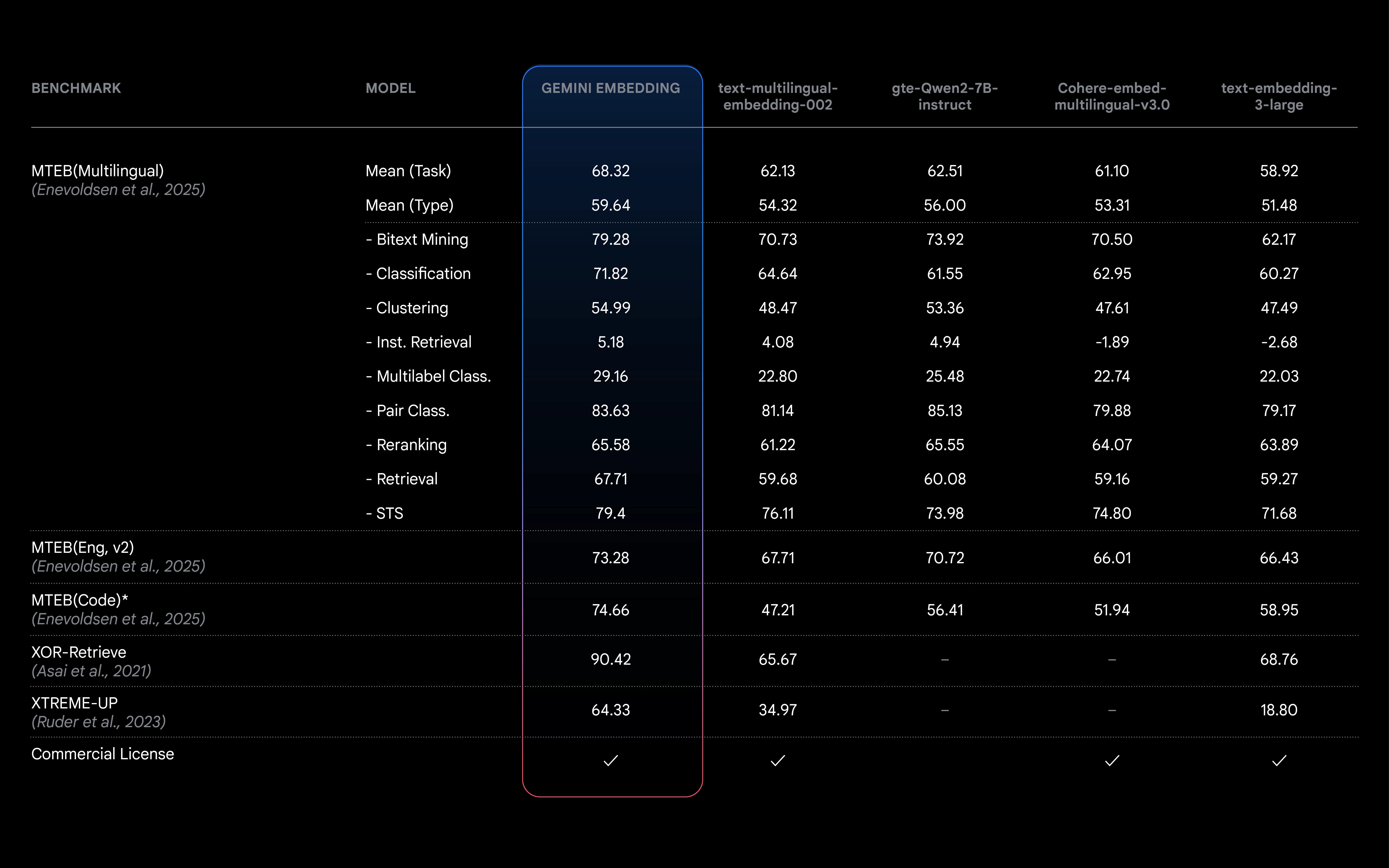
1️⃣ 超高性能:在 MTEB 多语言排行榜上排名第一
- 该模型在 MTEB 评测中 平均得分 68.32,比下一名高 +5.81 分
- 支持多种任务,包括检索(Retrieval)、分类(Classification)等
2️⃣ 语义理解更强
- 直接继承 Gemini 大模型 的语言理解能力
- 无需微调(Fine-tuning)即可适用于不同领域(金融、法律、医学、科学等)
3️⃣ 输入/输出增强
📌 输入支持 8K tokens(比之前的模型大幅提升)
📌 输出维度 3K(比之前的嵌入模型多 4 倍)
📌 支持 Matryoshka Representation Learning(MRL):
- 允许动态调整向量维度,节省存储成本
- 可选择3K、2K、1K、512 维度,灵活适应不同需求
4️⃣ 更强的多语言支持 🌍
- 现在支持 100+ 语言(之前的模型只支持部分多语言任务)
- 比单一语言模型(如英文专用嵌入)效果更好
与之前的模型对比

📌 提升点:
- 支持更长文本(8K tokens),适用于长文档分析 📄
- 更高的向量维度(3K),使得语义表示更加精准 🎯
- 双倍语言支持(100+),适用于全球化业务 🌍
如何使用 Gemini Embedding?
开发者可以直接通过 Gemini API 访问 Gemini Embedding,兼容现有 embed_content 端点。
📌 代码示例
``` from google import genai
client = genai.Client(apikey="YOURGEMINIAPIKEY")
result = client.models.embed_content( model="gemini-embedding-exp-03-07", contents="How does AlphaFold work?", )
print(result.embeddings)
```
📂 输入:文本内容(如“AlphaFold 是如何工作的?”)
📄 输出:文本对应的向量嵌入值(用于计算语义相似度)
💡 可以直接用于搜索、推荐、文本分类等任务!
官方介绍:https://developers.googleblog.com/en/gemini-embedding-text-model-now-available-gemini-api/
模型地址:text-embedding-004