Manus 的护城河在哪里?
这两天国内 AI 圈最火的非 Manus 莫属了,很惭愧我没有邀请码,也没直接试用过,但也看了好几个别人分享的回放,通过回放以及其他人分享的使用视频,再结合我自己使用同类产品的经验,基本上可以还原它的技术实现和产品设计了。
如果让我一句话总结,那么就是:交互上有非常大的创新,但受限于模型与数据,目前没有护城河。
优点:
- Manus 在产品交互上有非常大的创新,可以说相当惊艳。可以很容易的上手,整个过程对用户透明不需要干预,结果也很直观。
- 采用模拟人类浏览网页的方式让它更具有通用性,可以适用于通用任务而不是特定任务类型,未来有更大想象空间,就好比类人的机器人可以做更多的通用型任务。
- 可以对获取到的数据进行分析生成漂亮的图表。
- 生成的代码直接可以在虚拟机运行看到效果
不足:
- 通过 ToDo List 规划的方式,虽然可以让 AI 探索的路径不至于太发散,但是会让结果趋于平庸,毕竟稍微复杂一点的任务是需要根据获得的信息做动态调整的。
- 受限于模型的能力和上下文窗口长度,在资料的筛选,和最终资料的合并整理上,会有比较大损耗,最终生成结果和质量大部分时候是比较平庸的。
- 使用目前模拟浏览器搜索、点击、滚动,再用视觉识别文字图表的方式,时间成本和资源成本都不低,通过 OCR 获取屏幕内容也可能会导致信息缺失。
技术实现
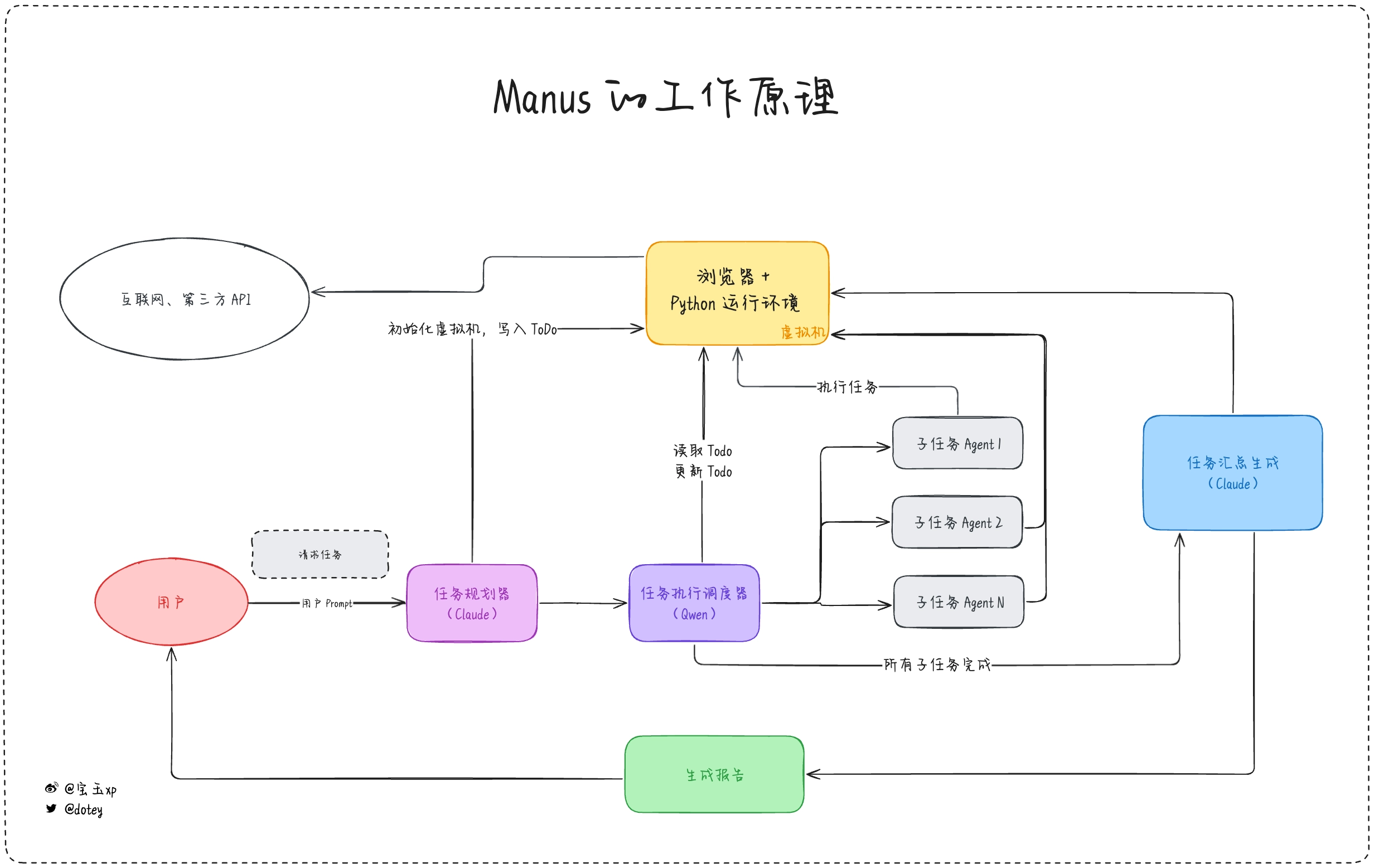 一图胜千言,这里我大致画了一下 Manus 的架构图(不代表真实实现,仅作示意参考),主要有几个模块:
一图胜千言,这里我大致画了一下 Manus 的架构图(不代表真实实现,仅作示意参考),主要有几个模块:
- 虚拟机:一个 Linux 系统的虚拟机,安装有Chrome 浏览器,用来访问网页Python 运行环境,可以执行脚本分析数据,可以启动一个网页运行环境
- 任务规划器:根据用户输入的任务请求,拆分成 ToDo List,我推测是 Claude 模型,因为这一步至关重要,必须要求模型有很强的推理能力,目前来说 Claude 3.7 Sonnet 应该是很经济实惠的选择
- 任务执行调度器:根据 ToDo List 的任务清单,逐一执行,根据任务去选择最合适的 Agent。由于这一步重点是在 Agent 的选择,所以不需要能力太强的模型,可以用开源模型比如 Qwen 稍微微调一下就可以用了。
- 各种执行不同类型任务的 Agents:Manus 内置了很多 Agent,比如最复杂的应该是类似于 OpenAI Operator 的网页浏览 Agent,比如根据特定 API 检索特定数据的 Agent,每个 Agent 在完成任务后都会把任务结果写到虚拟机。
- 任务汇总生成器:当每个子任务执行完成后,任务执行调度器就会通知任务汇总生成器,任务汇总生成器就会去虚拟机读取 ToDo List 以及各个子任务的生成结果,把这些结果汇总整理生成最终结果,根据任务要求,可能是一份调研报告,可能是网页程序。由于这一步要求有极强的推理能力和语言能力,所以必然要求一个很强的模型,所以我猜这里也应该是 Claude 3.7 Sonnet。
这基本上就是它的主要工作原理,所以你也可以看得出,真正制约它能力的还是在于模型的能力和 Agent 的能力,而 Agent 也是受制于模型的能力。
Manus 的护城河在哪里?
如果连我这样一个伪专业人士也能大致分析出它的技术实现,那么是不是其他团队也可以去马上山寨一个出来?Manus 的护城河在哪里呢?
对于现在的 AI 产品来说,护城河主要就几个点:
- 模型 + 算力
- 数据
- 用户体验
比如说 OpenAI 的 Deep Research,虽然开源或者商业的竞品很多,但是效果比它好的还没有第二家,因为它用来规划任务、选择工具、汇总的模型是他们家最强的推理 o3 模型,可能也是业界最强的推理模型,无论是推理能力还是上下文长度都超过了公开的 Claude 3.7 Sonnet 模型,同时他们还基于 o3 针对 Deep Research 做了大量的强化学习训练,让模型在执行任务和生成内容都可以取得很好的效果,模型能力就是 OpenAI 的护城河。
比如说 Google,虽然模型不一定有 OpenAI 的强,但是它们家的数据搜索能力是最强的,可以获取到优质的数据源,所以效果也不错,数据搜索就是 Google 的护城河。
比如说经常被比作是“套壳”的 AI 产品 Perplexity,模型比不过 OpenAI,数据搜索比不上 Google,但是依然在 AI 搜索中占有很重要的地位,它依赖的是独特的用户体验,更懂用户,更好的提供了用户想要的搜索结果。
但这里的用户体验,不是传统意义上的用户界面交互层面的体验,而是基于大量用户使用数据而个性化优化后的优化体验,很懂用户想要什么。
类似的例子还有 AI 编辑器 Cursor,它也是靠的用户体验来吸引用户,虽然它的 Composer 功能很快就被竞争对手学习借鉴过去了,但是它的自动补全功能却一直没被竞争对手超越,作为一个重度使用者感觉特别明显,就是 Cursor 真的很懂我想要做什么,每次修改一点,它就能自动给我建议要完成的下一步操作,而大部分时候,它的建议都是我想要的。正是这个原因,即使我同时还用其他家的 AI 编辑器,Cursor 的订阅也一直留着。
Perplexity 和 Cursor 这类 AI “套壳”产品的护城河,就在于它有大量用户数据沉淀后的用户体验。
所以未来对于 Manus 或者这类产品来说,想形成自己的护城河,不仅仅是要在用户产品体验上的创新,还需要有用户数据上的沉淀,把这种数据变成一种飞轮效应:基于用户的数据做出更懂用户的体验,更懂用户的体验吸引更多的用户使用。
除了上面我说的用户体验外,哥飞也提到了一个有趣的观点叫“卡生态位”:
从昨晚开始,我们群友 Monica 团队的新产品 Manus 就在刷屏了。 很多人在求邀请码,也有一些人拿到了内测权限,发出了自己的体验文章。 有人觉得惊艳,有人觉得不就那样,有人觉得没有达到自己期待的样子。 这一切都因为目前AI还处于很早期,不是 Manus 做得不够好,而是受限于目前AI的能力,只能做到这样。 但即使是目前这样,其实已经让很多人觉得惊艳了。 我们不能因为暂时实现不完美,就不推出产品。 有些人开发产品的心态是,我不打磨到100分,我就不推出来。 然而,其实产品永远有值得改进的点,难到那就一直改进,一直不推出吗? 要有一个生态占位思路,先推出产品,先占住这个生态位,然后不断迭代,不断提升能力,就能够做得越来越好。 相似的例子是Cursor,他们最开始发布的产品,效果也没有那么好,没有那么惊艳,但是他们等到了 claude sonnet 3.5 这个模型的出现,于是全球各地开发者都在自来水推荐 Cursor 。 试想一下,如果 Cursor 等到了 claude sonnet 3.5 发布之后,才去开始动手做,那么机会还会是 Cursor 的吗? 哥飞很有道理,吸引来用户,留住用户,形成口碑,把这些用户数据沉淀下来进一步提升用户体验,以后随着模型能力的升级一起更新迭代,就能真正形成自己的护城河,再难被其他竞品超越。
Manus 开了个好头,但挑战还是不小的,开源的实现、商业上的山寨版本应该很快就要出来了,用户的热度也会消散的很快,一旦有新的热点马上就会去追逐新的热点了,就像你还记得 OpenAI 家的 Operator 吗?