腾讯推出 图像到视频(I2V)生成模型 HunyuanVideo-I2V,基于其 HunyuanVideo 框架,能够将静态图像转换为高质量视频,并支持 LoRA 微调 来创建定制特效。
✅ 单张图片生成视频,输入一张图片,生成与其风格匹配的动态视频。
✅ 多模态理解,结合 文本描述 和 图像信息,让生成的视频更符合用户需求
✅ 高一致性:确保 视频首帧 与输入图片高度一致,避免失真或风格变化。
✅自然动态过渡:生成流畅的视频运动,支持人物、风景、物体的动态演绎。
✅ 支持 LoRA 训练,可微调个性化特效
✅ 多 GPU 加速推理,最高支持 720P 视频
主要功能特点
图像转视频(I2V)
- 高质量视频生成:输入单张图片,生成具有流畅动态效果的短视频。
- 保持视觉一致性:融合图像信息,确保视频中物体形状、风格与原始图像一致。
强化多模态理解
- 使用预训练的大型多模态语言模型(MLLM)作为文本编码器,增强对输入图像的理解。
- 结合图像和文本信息,在生成过程中确保内容语义一致。
LoRA 微调(Customizable LoRA Effects)
支持 LoRA 训练,可用于定制特殊视频特效,如:
- 头发生长效果
- 物体变形
- 角色动态增强
- 降低计算成本:LoRA 方法相比完整训练更轻量,适合个性化调整。
高效推理
- 支持多 GPU 并行推理,加速高分辨率视频生成(最高可达 720P)。
- 优化的 Transformer 架构,提升采样效率,减少生成时间。
运行要求
- 最低 GPU 内存:60GB(720p 推理)
- 推荐配置:80GB GPU
- 操作系统:Linux
- 支持 FP8 量化,减少显存占用
HunyuanVideo-I2V 的架构设计
HunyuanVideo-I2V 采用了 基于 Transformer 的扩展架构,在原始 HunyuanVideo T2V 结构的基础上,增加了 语义图像注入模块(Semantic Image Injection),增强模型对输入图像的理解能力。
HunyuanVideo-I2V 的核心架构
- 主要基于 Diffusion Transformer(DiT),但增加了图像处理模块,使得输入图像能在整个生成过程中被保留和利用。
- 采用 语义图像注入(Semantic Image Injection) 机制,提升输入图像的特征融合能力。
- 采用 双流到单流(Dual-Stream to Single-Stream) 训练策略,使得文本、图像和视频信息能更好地融合。
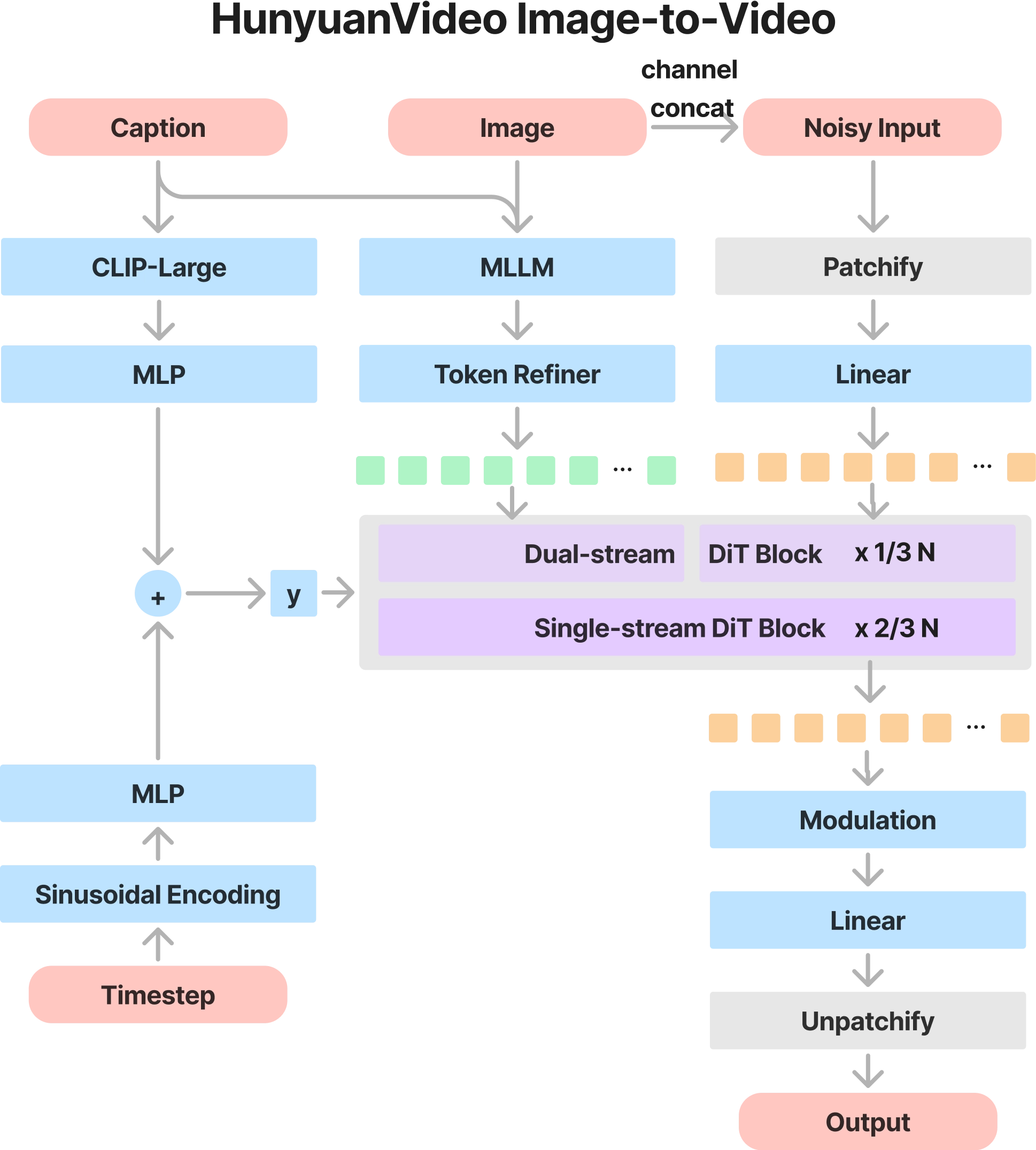
语义图像注入(Semantic Image Injection)
HunyuanVideo-I2V 的关键点是如何有效地将输入图像的特征融入到整个视频生成过程中,而不会破坏生成的视频动态性和自然性。
语义特征提取
- 使用 MLLM(多模态大模型)提取语义信息:MLLM 处理输入图像并提取语义特征,以便在 Transformer 计算过程中使用。
- 引入语义 token 机制:提取的语义特征被转换成 token,并与视频生成 Transformer 的 token 一起计算,从而提高生成结果的语义一致性。
视觉信息注入
HunyuanVideo-I2V 采用了 两种图像特征注入方式:
像素级特征注入(Pixel-wise Injection):
- 通过 VAE(变分自编码器)将输入图像转换为潜在空间表示(latent representation)。
- 将图像的特征作为 第一帧 的基础,使其与视频生成过程紧密结合。
高层语义注入(Semantic Injection):
- 采用 MLLM 提取高层特征,并通过 Transformer 层进行融合。
- 这种方法确保输入图像的风格、语境信息能够影响整个视频序列。
I2V 模型的输入格式
HunyuanVideo-I2V 采用了特殊的数据输入格式,以适应 I2V 任务的需求:
- 输入图像:作为 第一帧,并经过 VAE 进行潜在空间映射。
- 输入文本:作为 视频生成条件,影响视频的动态性和内容。
- 输入 mask:标记哪些区域需要进行运动生成,哪些区域应保持不变。
这三者共同作用,使得模型能够生成与输入图像视觉一致、并符合文本描述的视频内容。
训练方法
HunyuanVideo-I2V 采用 两阶段训练策略,逐步提升模型对 I2V 任务的适应能力。
第一阶段:图像-视频联合训练
- 使用大规模数据进行预训练,包括静态图像和相应的视频对。
- 采用 混合尺度训练(Mix-scale Training),支持 不同分辨率和长宽比的视频生成。
- 通过 图像与视频联合学习,增强模型对图像细节的理解能力,使其能更自然地生成视频。
第二阶段:高质量微调
- 使用 200 万张高质量人像数据进行微调,提高 人脸、动作和表情生成的细节。
采用渐进式冻结策略(Progressive Unfreezing):
- 逐步解冻模型的不同层,使其在特定领域(如人像生成)上优化,同时保留泛化能力。
增加数据增强策略:
- 随机丢弃文本提示,增强模型对单图像的适应能力。
- 采用多样性增强(Diversity Enhancement),避免模式坍塌(Mode Collapse)。
GitHub:https://github.com/Tencent/HunyuanVideo-I2V
技术报告:https://arxiv.org/pdf/2412.03603