在计算机视觉领域,多视角3D 重建一直是一项重要且具挑战性的任务,尤其是在需要精确且可扩展的表示时。现有的主流方法,例如 DUSt3R,主要采用成对处理的方式,这种方法在进行多视角重建时需要复杂的全局对齐程序,既耗时又耗力。为了解决这一问题,研究团队提出了 Fast3R,这是一种创新的多视角重建技术,它可以在一次前向传播中处理多达1500张图片,大幅提升了重建速度。
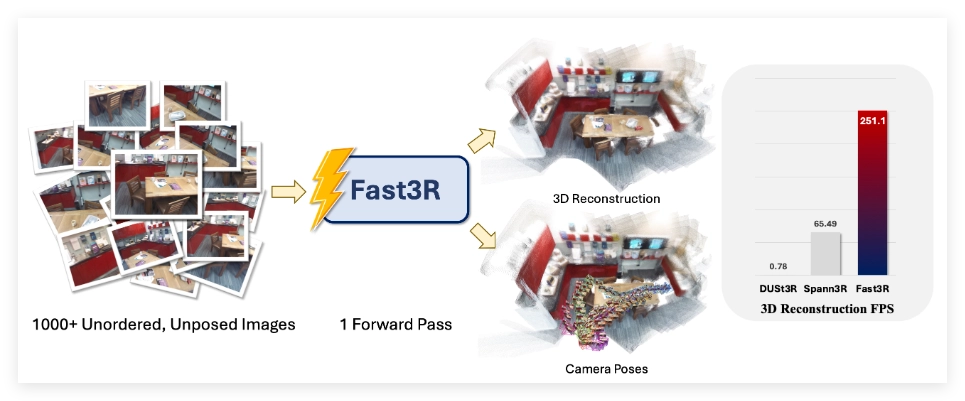
Fast3R 的核心是一个基于 Transformer 的架构,能够并行处理多张视图信息,从而省去迭代对齐的过程。这一新方法通过广泛的实验验证了其在相机位姿估计和3D 重建任务中的出色表现,显著提高了推理速度,并减少了误差积累,使 Fast3R 成为多视角应用中一种强有力的替代方案。

在 Fast3R 的实现中,研究者运用了一系列大规模模型训练和推理技术,确保了高效且可扩展的处理能力。这些技术包括 FlashAttention2.0(用于内存高效的注意力计算)、DeepSpeed ZeRO-2(用于分布式训练优化)、位置嵌入插值(便于短期训练和长期测试)以及张量并行(加速多 GPU 推理)。
在计算效率方面,Fast3R 在单张 A100GPU 上表现优异,显示出相比 DUSt3R 的显著优势。例如,当处理32张分辨率为512×384的图像时,Fast3R 仅需0.509秒,而 DUSt3R 则需要129秒,且在处理48张图像时便面临内存溢出的问题。Fast3R 不仅在时间和内存消耗上表现突出,也在模型和数据规模方面展现出良好的扩展性,预示着其在大规模3D 重建中的广阔前景。
项目入口:https://fast3r-3d.github.io/
划重点:
🌟 Fast3R 技术可以在一次前向传播中处理多达1500张图片,大幅提高3D 重建速度。
⚡ Fast3R 的 Transformer 架构支持并行处理,省去传统方法的复杂对齐过程。
🚀 与 DUSt3R 相比,Fast3R 在时间和内存使用上展现出显著优势,适用于大规模3D 重建应用。