模型即产品(The Model is the Product)
过去几年,人们一直在讨论下一个AI发展周期可能是什么:智能体(Agents)?推理系统(Reasoners)?还是彻底的多模态?
现在是时候下结论了:下一个周期,就是“模型本身即产品”。
目前,无论是科研界还是产业界的变化,都在推动这种转型:
- 通用模型扩展遇到了瓶颈。OpenAI发布GPT-4.5时透露了一个重要信息:模型能力呈现线性增长,但算力成本却指数级飙升。尽管过去两年训练效率不断提高,但成本太高,以至于OpenAI无法以合理的价格广泛部署最新的大模型。
- 特定任务的强化训练效果远超预期。结合强化学习与推理能力训练,模型开始真正地“学习任务”,出现了一种新东西:既非传统机器学习,也不是基础模型,而是一种神秘的第三种类型。小模型突然展现出极强的数学能力;代码模型不仅会写代码,甚至能自己管理整个代码库;Claude甚至能在信息极少的情况下玩宝可梦游戏,并且做得很好。
- 推理成本大幅下降。以DeepSeek为例,新的优化技术已经让全球所有现有GPU的总算力,足以每天给地球上的每个人提供1万个顶级模型生成的token。这意味着,单纯卖token(模型调用次数)的经济模式已经难以持续,模型提供商不得不去做更高附加值的事情。
这种趋势让许多人感到不舒服。投资者们原本押注在应用层,但下一个阶段,最可能被AI取代的恰恰就是应用层。
下一代模型的形态
过去几周,我们看到了新一代“模型即产品”的典型案例,比如OpenAI的DeepResearch和Anthropic的Claude Sonnet 3.7。
许多人误解了DeepResearch,尤其市面上出现了大量山寨版本,让情况更加混乱。事实上,OpenAI并不是简单地在GPT基础上增加了外部搜索功能。他们训练了一个全新的模型,能够完全在内部完成搜索任务:
模型学习了基础的浏览能力(搜索、点击、滚动、文件解析),以及如何通过强化学习来整合大量网页信息,生成结构清晰、来源可靠的研究报告。 因此,DeepResearch并不是普通的聊天模型,而是一种专门设计用于搜索和研究的新型语言模型。相比之下,谷歌的Gemini和Perplexity的类似功能,只是在普通模型基础上的表面优化:
Gemini和Perplexity也提供了所谓“深度研究”功能,但他们并未公开任何优化模型方法或实质性评估,这表明他们并未进行深入训练。 Anthropic也在明确他们的发展方向。他们在去年底给出了智能体(Agent)明确的定义:真正的智能体必须能够自主决定任务的具体实现过程和工具使用,而非被人为设计好的工作流程所限制。
目前市面上许多号称“智能体”的公司,实际上只是在设计自动化工作流程(workflows),即人为定义好的代码路径串联模型和工具。虽然这种工作流程也有一定价值,但未来真正有效的智能体一定会通过重新训练模型本身来实现。
举个具体例子:最近发布的Claude 3.7模型,专门针对复杂的代码开发任务进行强化训练,这让所有与代码相关的应用都出现了性能显著提升。
我所在的Pleias团队也做了类似尝试:我们设计了两个专门的模型,一个用于数据准备,一个专门用于搜索和报告生成,通过设计全新的合成数据和奖励机制进行训练,让部署阶段更简单,最终使得复杂性在训练阶段就被解决。
具体表现为将这种复杂结构:
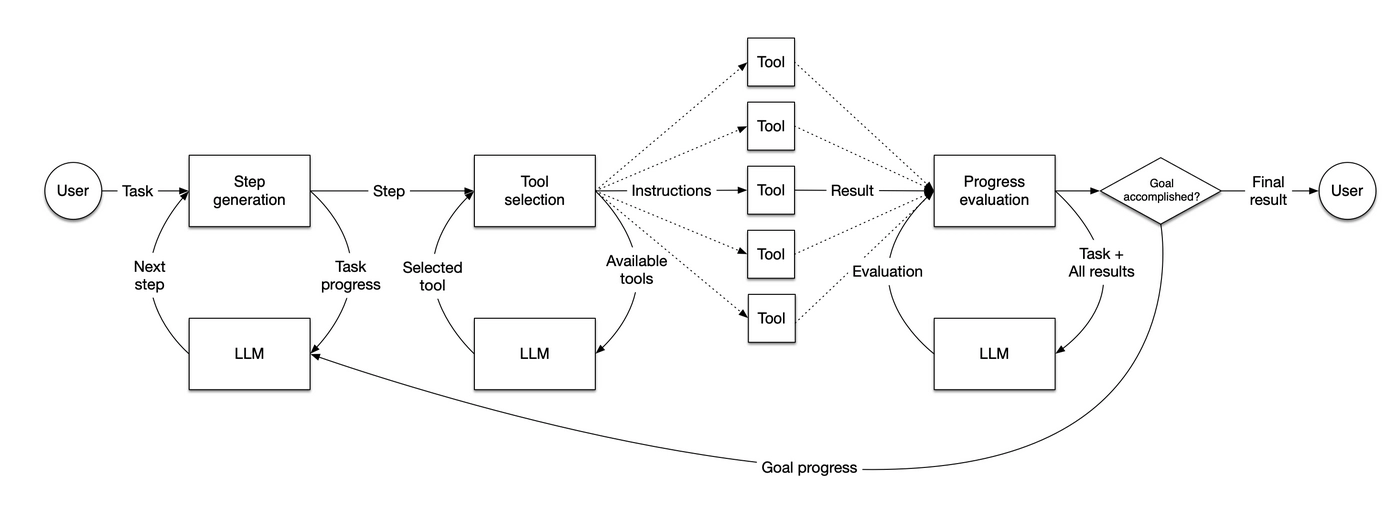 转变为如下更简洁的模式:
转变为如下更简洁的模式:
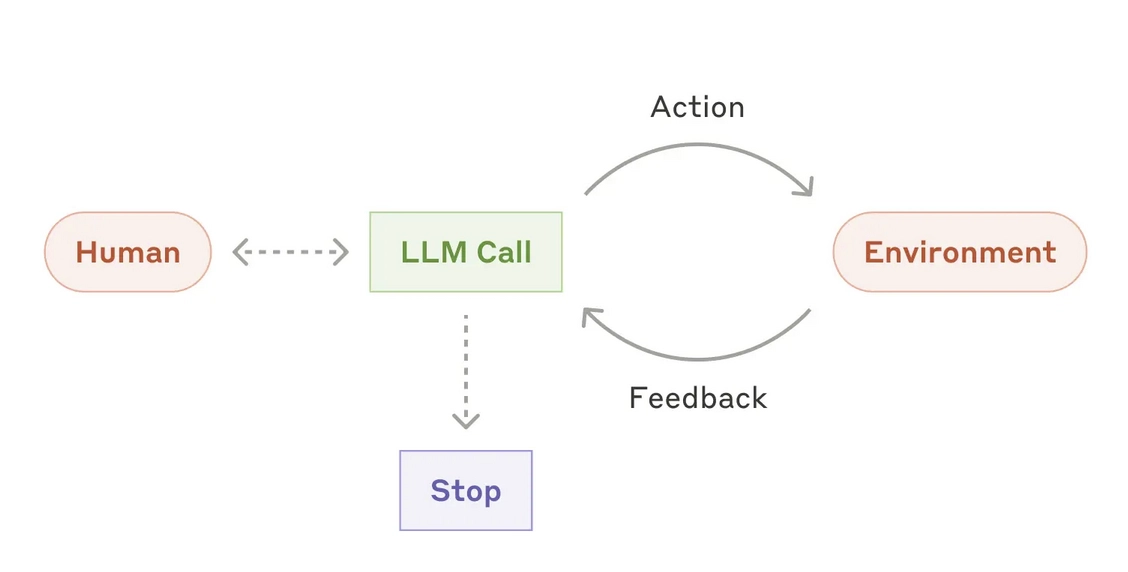
要么自己训练,要么被别人训练。
可以明确的是,各大实验室都在向这个方向前进:他们会逐步停止开放API,转向自己训练并直接提供完整模型服务。著名AI公司Databricks的投资人Naveen Rao很清晰地指出:
在未来2-3年内,所有闭源AI提供商将停止提供API服务,只有开源模型才会继续提供API。闭源公司会建立更加独特、非商品化的能力。 近期的迹象也佐证了这个趋势:
- OpenAI发布的DeepSearch只用于高级订阅用户,根本没有提供API服务。
- Claude Code的模型训练针对代码应用场景优化后,反而导致Cursor这样的第三方工具使用效果不佳。
- 一些曾经的“包装商”(wrapper公司,比如Cursor、WindSurf、Perplexity)也开始秘密训练自己的小型模型,以增强自己的竞争力。
小公司可能不会马上感受到这种冲击,但他们会越来越依赖独立的推理服务提供商。现在的竞争格局就像免费为大公司做市场调研和数据生成,最终结果可能是被训练公司吞并。
强化学习的价值被严重低估。
目前所有AI投资都存在同质化现象,投资机构普遍认为:
- 真正的价值只存在于与模型无关的应用层;
- 所有形式的训练,包括强化学习,都没有投资价值。
但现实情况是,强化学习(RL)的进步已经彻底改变了这种情况。现在的市场情况更像是风险投资出现了集体错误定价,忽视了强化学习最新的技术突破带来的巨大价值。
实际上,真正的新机会反而是那些专注于模型训练的公司,但他们却很难拿到融资。Prime Intellect公司虽然训练出了第一个去中心化的大模型,但融资规模甚至不如一般的应用层公司。
OpenAI最近也开始表达对这一现象的不满,希望硅谷创业公司多关注“垂直领域强化学习”,未来YC孵化器可能会做出调整:模型实验室不再只是向客户开放API,而是会和参与模型早期训练阶段的公司形成深度合作。
技术的爆炸,而非应用的爆炸。
相较之下,中国 DeepSeek 创始人梁文峰则更加直接地指出了这一点:
当前的AI发展,是一场技术创新的爆炸,而非应用创新的爆炸……如果上下游生态体系还不完整,直接去押注应用并没有意义。 很多西方公司甚至还没有意识到这场技术战争已经结束了,他们还在用上一次战争的思维去打下一次战争,已经远远落后。
以上,就是目前AI发展的大势所趋:
模型本身已经成为产品本身,谁掌握模型训练,谁就掌握未来。