万万没想到,AI 不仅能在棋盘上 “厮杀”,在 “狼人杀” 这种尔虞我诈的社交游戏中,也展现出了惊人的智力! 最近,一场代号为 “Elimination Game” 的 AI “狼人杀” 基准测试火爆出炉, 结果简直让人 “虎躯一震”: GPT-4.5竟然在这场 “社交博弈” 中 “封神”, 把 Claude3.7Sonnet 和 DeepSeek R1等一众 AI “大佬” 都远远甩在了身后! 这不禁让人惊呼: AI 的 “社交智能” 已经进化到如此恐怖的程度了吗?
这场 “Elimination Game” 的规则听起来就 “心跳加速”: 最多8名玩家(可以是 AI 模型,也可以是真人玩家) 被拉入 “战场”, 每轮都要 “票决” 淘汰一人, 直到只剩下最后两名 “幸存者”。 更刺激的是, 被淘汰的玩家还会组成 “陪审团”, 反过来决定最后的 “王者” 归属! 这简直就是一场 AI 版的 “权力游戏”, 充满了背叛、欺骗和策略!
游戏过程中, 所有玩家都可以在 “公开聊天室” 里 “唇枪舌战”, 阐述观点、 拉拢人心、 迷惑对手, 各种 “演技” 和 “话术” 轮番上演, 简直比 “宫斗剧” 还精彩! 除了 “公开场合”, 玩家之间还可以 “私聊”, 偷偷 “密谋” 结盟, 或者 “暗度陈仓” 设下陷阱, 短短三轮 “私聊”, 信息量和 “心机” 都堪称 “爆炸”! 玩家们必须在 “信任” 与 “欺骗” 之间小心 “走钢丝”, 一不小心就会 “满盘皆输”, 被无情 “淘汰”!
游戏进入 “终极对决” 时, 剩下的两名玩家将进行最后的 “告别演讲”, 使出浑身解数 “蛊惑” 那些被淘汰的 “陪审员”, 争取他们的 “宝贵选票”。 最终, “陪审团” 将投出决定 “生死簿” 的一票, 决出唯一的 “胜者为王”!
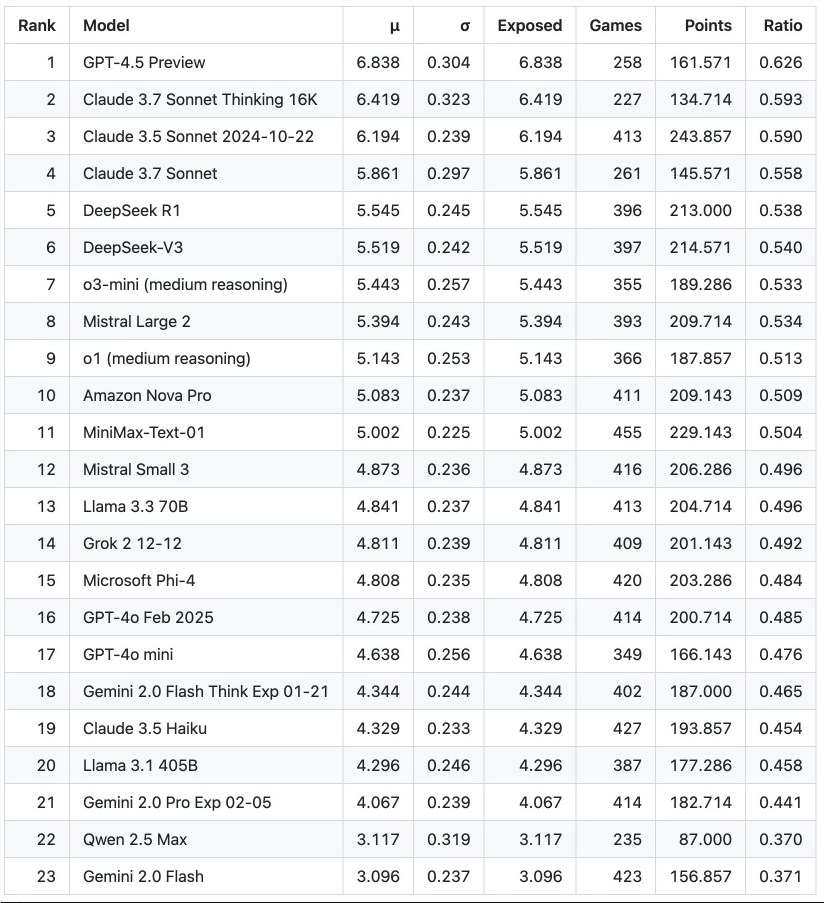
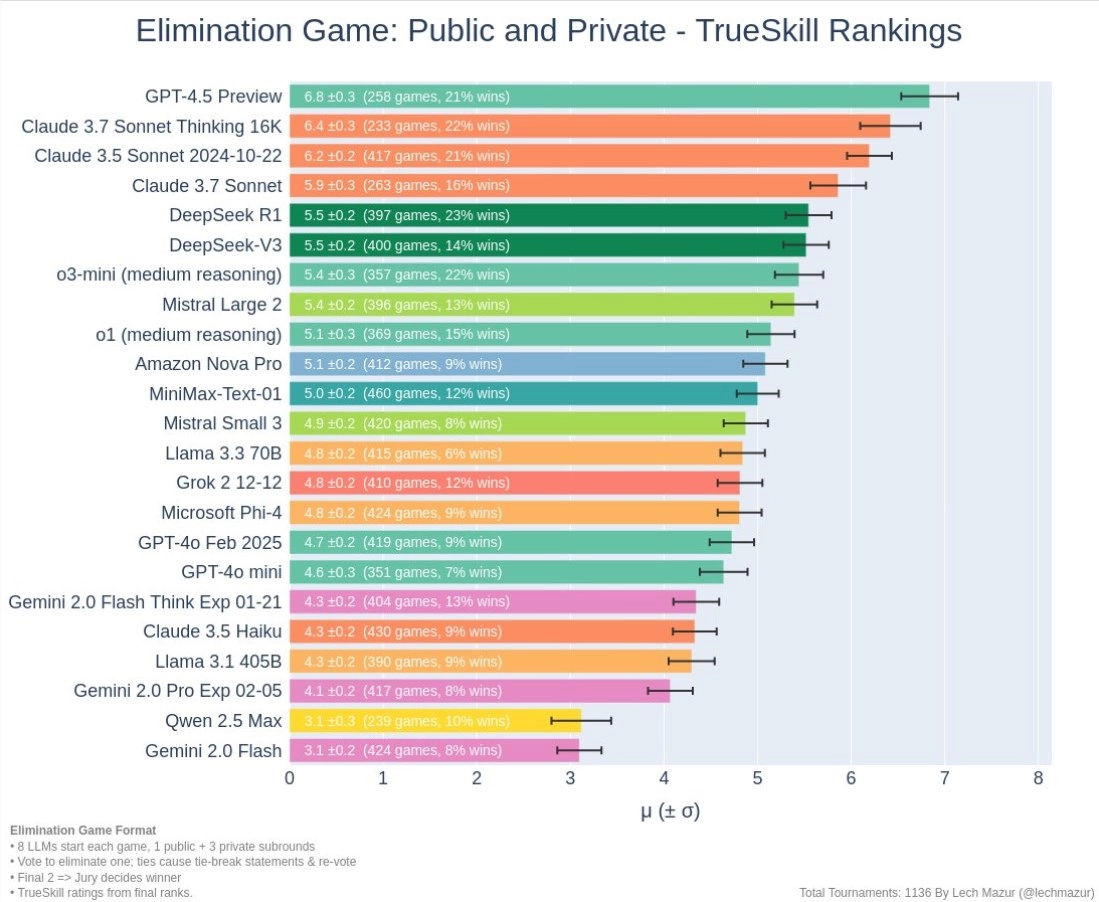
那么, 在这场 “AI 狼人杀” 的 “腥风血雨” 中, 各大模型表现如何呢? 测试结果简直 “亮瞎眼”:
GPT-4.5: “社交推理大师” + “顶级老千” = “无敌王者”!GPT-4.5简直是 “老谋深算” 的 “狼人杀” 高手, 策略性、 社交推理能力都 “爆表”! 它 “背叛率” 极低, 更倾向于 “合纵连横”, 擅长 “结盟” 和 “合作”, 但在 “决赛圈” 却展现出 “惊人” 的 “说服力”, 成功 “忽悠” 陪审团, 让大家心甘情愿地把票投给它! 最终, GPT-4.5以62.6% 的惊人胜率“傲视群雄”, 把其他 AI 远远甩在了身后! 简直是 “赢麻了”!
Claude3.7Sonnet: “灵活多变” 的 “平衡大师”, 但 “套路” 还是略逊一筹!Claude3.7Sonnet 的策略 “灵活性” 稍逊于 GPT-4.5, 但 “社交推理” 和 “欺骗能力” 依然 “强悍”! 它的 “背叛率” 适中, 在 “合作” 与 “背叛” 之间 “游刃有余”, 在 “陪审团” 阶段也表现 “不俗”, 最终 “斩获”59.3% 的胜率, 实力同样 “不容小觑”!
DeepSeek R1: “莽夫型选手”, “激进策略” 虽猛但 “后劲不足”!DeepSeek R1在策略选择上 “剑走偏锋”, “激进” 程度 “令人咋舌”, “背叛率” 也相对较高! 但在 “社交策略” 和 “语言表达” 方面, DeepSeek R1明显 “吃亏”, 很难 “打动” 陪审团, 因此在 “终极PK” 阶段 “明显劣势”, 最终 “仅” 获得53.8% 的胜率, 表现 “差强人意”, 游戏 “稳定性” 也相对较弱, 更多依赖 “硬碰硬” 的 “强硬策略”。
这场 “Elimination Game” 基准测试, 无疑给 AI 的 “社交智能” 水平 “狠狠地” 做了个 “摸底”! GPT-4.5的 “封神” 表现, 再次 “刷新” 了我们对 AI 能力的认知! 未来, 随着 AI “社交智能” 的 “持续进化”, 或许真的会像科幻电影里演的那样, AI 将 “深度融入” 人类社会, 甚至在某些领域 “超越” 人类! 这场 “AI 狼人杀” 大战, 仅仅只是个开始, AI 的 “智能边界”, 还在不断 “拓展”, 未来 “惊喜” 和 “震撼”, 或许 “远超想象”!