近年来,大语言模型(LLM)在人工智能领域取得了显著进展,尤其是在多模态融合方面。华中科技大学、字节跳动与香港大学的联合团队最近提出了一种新型的多模态生成框架 ——Liquid,旨在解决当前主流多模态模型在视觉处理上的局限性。
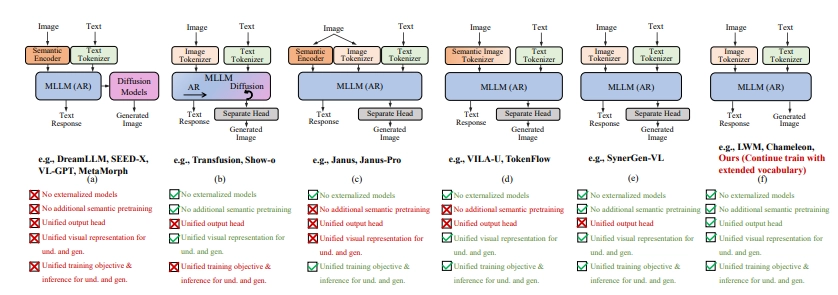
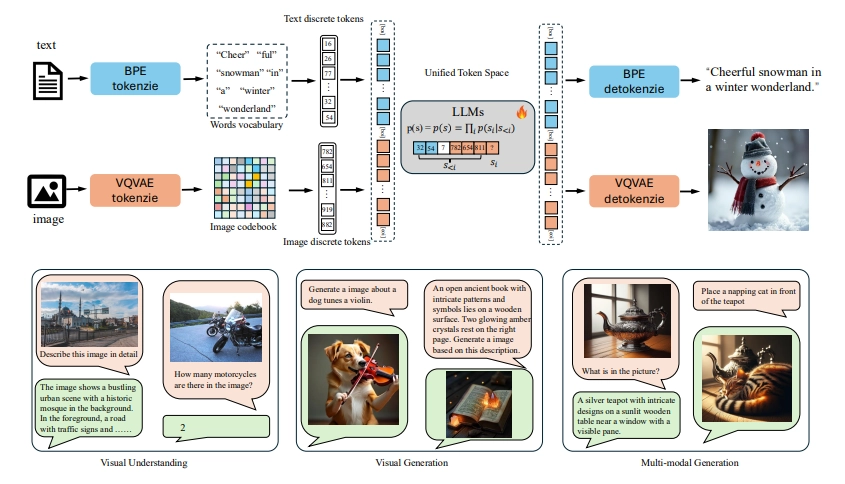
传统的多模态大模型依赖复杂的外部视觉模块,这不仅增加了系统的复杂性,还限制了其扩展性。Liquid 的创新之处在于,它采用 VQGAN 作为图像分词器,摒弃了对外部视觉组件的依赖,通过将图像编码为离散的视觉 token,使得模型可以直接与文本 token 共享词表,从而实现 “原生” 的视觉理解与生成能力。
研究发现,Liquid 不仅能够降低训练成本,还揭示了多模态能力与 LLM 的尺度规律。团队在不同规模(从0.5B 到32B)的 LLM 上进行了实验,结果显示,随着模型规模的扩大,其视觉生成任务的性能和生成质量均遵循与语言任务一致的缩放规律。更令人振奋的是,视觉理解与生成任务之间存在双向促进的关系,即两者可以通过共享的表示空间实现联合优化。
Liquid 的设计充分体现了极简主义,它将图像与文本一视同仁,采用统一的处理框架。在构建过程中,研究团队利用30M 的文本数据和30M 的图文对数据,为模型的多模态训练奠定了基础。最终的实验结果表明,Liquid 在多模态理解、图像生成及纯文本任务中都表现出了优越的性能,其生成的图像与文本之间的语义一致性显著高于其他自回归模型。
Liquid 的提出为通用多模态智能的架构设计提供了新思路,预示着人工智能在多模态融合的未来可能会迎来更加高效和灵活的进化。
论文链接:https://arxiv.org/pdf/2412.04332