近日,阿里巴巴通义实验室宣布开源其最新研发成果——ViDoRAG,这是一款专为视觉文档理解设计的检索增强生成(RAG)系统。ViDoRAG在GPT-4o模型上的测试显示,其准确率达到了令人瞩目的79.4%,相较传统RAG系统提升了10%以上。这一突破标志着视觉文档处理领域迈出了重要一步,为人工智能在复杂文档理解上的应用提供了新的可能性。
多智能体框架赋能视觉文档理解
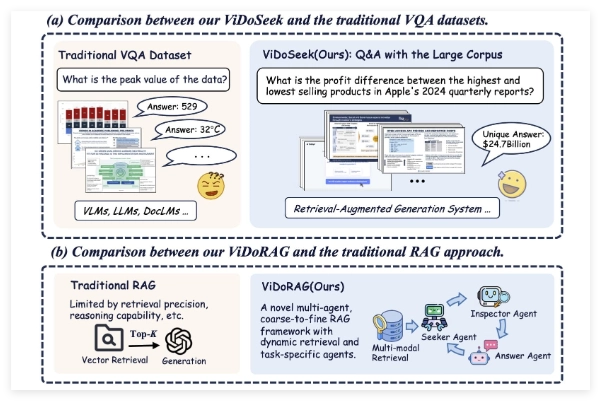
ViDoRAG并非传统的单一模型,而是采用了创新的多智能体框架设计。据介绍,该系统结合了动态迭代推理代理(Dynamic Iterative Reasoning Agents)和基于GMM(高斯混合模型)的混合检索技术。这种方法使得ViDoRAG能够在处理包含图像和文本的视觉文档时,更加精准地提取和推理关键信息。相比传统RAG系统仅依赖文本检索的局限性,ViDoRAG通过多模态数据融合显著提升了性能。
通义实验室在发布的论文和代码仓库中详细描述了ViDoRAG的工作原理。其核心在于通过多个智能体协作,动态调整检索和生成的过程,从而在复杂场景下减少“幻觉”现象(即模型生成不准确或凭空捏造的内容),并提高回答的可靠性和上下文相关性。
性能突破:准确率提升10%以上
该系统在GPT-4o上的准确率达到79.4%,这一数字不仅展示了其优异性能,还将其与传统RAG系统进行了对比。传统RAG系统虽然在文本生成任务中表现出色,但在处理视觉文档时往往受限于单一模态的检索能力,准确率通常徘徊在较低水平。而ViDoRAG通过引入视觉信息与文本信息的深度整合,将准确率提升了超过10个百分点。这一进步对于需要高精度文档理解的场景,如法律文件分析、医疗报告解读和企业数据处理,具有重要意义。
阿里巴巴通义实验室将ViDoRAG开源的举措也在Twitter上引发了热议。用户认为,这一系统的公开不仅体现了阿里在AI领域的技术实力,也为全球开发者和研究人员提供了一个宝贵的资源。通过公开论文和代码(相关链接已在Twitter帖子中分享),ViDoRAG有望加速视觉文档RAG技术的研究与应用,推动多模态AI系统的进一步发展。
ViDoRAG的发布和开源无疑为RAG技术开辟了新的方向,随着视觉文档处理需求的不断增长,ViDoRAG的出现或许只是一个开始,未来我们可能会看到更多类似的创新系统涌现。
项目:https://github.com/Alibaba-NLP/ViDoRAG