在人工智能(AI)技术快速发展的今天,DeepSeek 团队推出了其全新的 DeepSeek-V3/R1推理系统。这一系统旨在通过更高的吞吐量和更低的延迟,推动 AGI(通用人工智能)的高效发展。为了实现这一目标,DeepSeek 采用了跨节点专家并行(Expert Parallelism,EP)技术,显著提高了 GPU 的计算效率,并在降低延迟的同时,扩展了批处理规模。
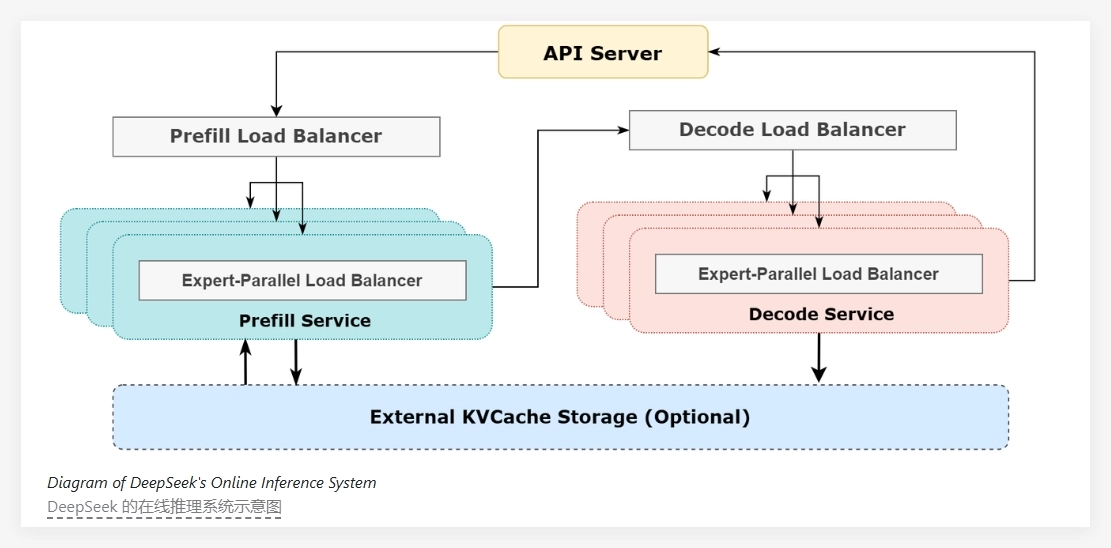
DeepSeek-V3/R1的核心在于其极高的稀疏性,模型中每层仅激活256个专家中的8个,因此需要非常大的批处理大小,以确保每个专家都有足够的处理能力。该系统的架构采用了预填充解码解聚(prefill-decode disaggregation)的方法,在预填充和解码阶段采用不同程度的并行化策略。
在预填充阶段,系统通过双批次重叠策略来隐藏通信成本,这意味着在处理一批请求时,另一批的通信成本可以被计算过程所掩盖,从而提升了整体吞吐量。而在解码阶段,针对不同执行阶段的时间不平衡问题,DeepSeek 采用了五级流水线的方式,实现了无缝的通信与计算重叠。
为了应对大规模并行性所带来的负载不均问题,DeepSeek 团队设立了多个负载均衡器。这些负载均衡器致力于在所有 GPU 之间平衡计算和通信负载,避免某一单一 GPU 因超负荷运算而成为性能瓶颈,确保资源的高效利用。
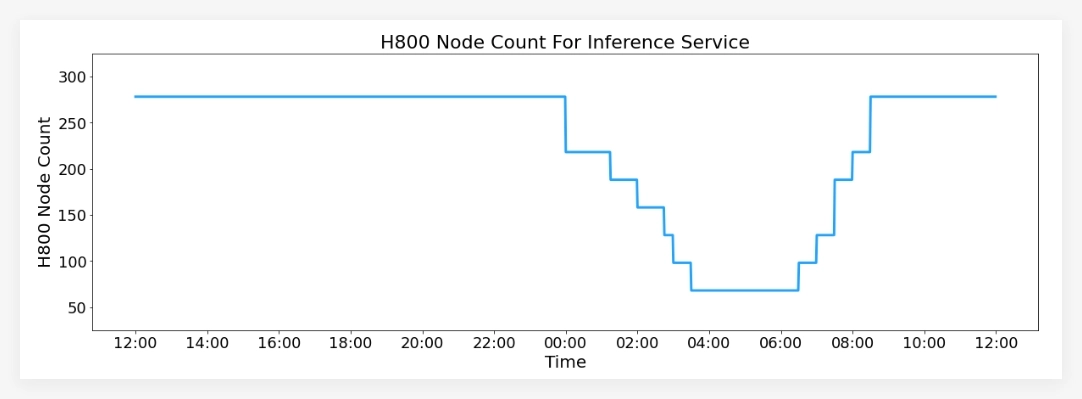
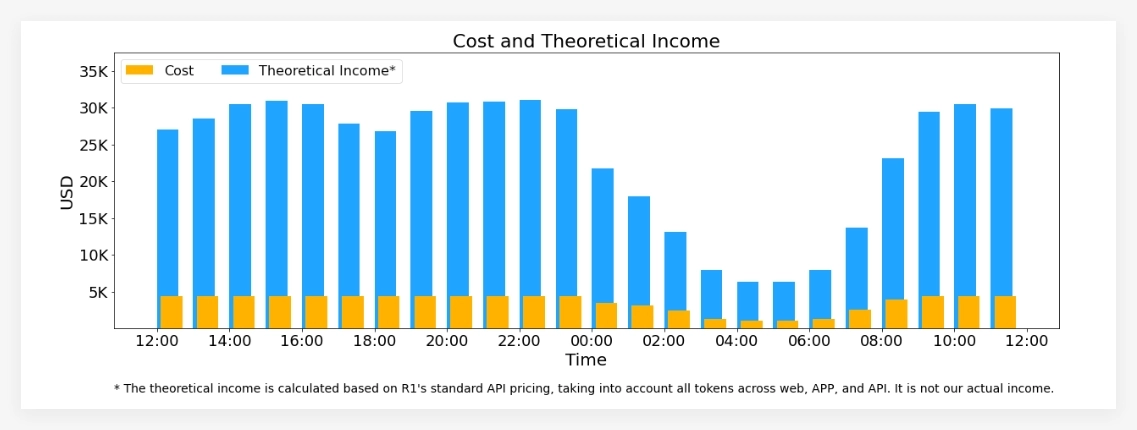
在服务性能方面,DeepSeek-V3/R1推理服务在 H800GPU 上运行,使用的矩阵乘法和传输格式与训练过程保持一致。根据最新的统计数据,系统在过去24小时内处理了6080亿个输入令牌,最高节点占用率达278,日均占用率为226.75,整体服务表现良好。
DeepSeek-V3/R1推理系统通过高效的架构设计和智能的负载管理,不仅提升了人工智能模型的推理性能,也为未来的 AGI 研究与应用提供了强有力的基础设施支持。
项目:https://github.com/deepseek-ai/open-infra-index/blob/main/202502OpenSourceWeek/day6onemorethingdeepseekV3R1inferencesystemoverview.md
划重点:
🌟 DeepSeek-V3/R1推理系统通过跨节点专家并行技术,实现更高的吞吐量和更低的延迟。
📊 采用双批次重叠策略与五级流水线,提升计算效率并优化通信过程。
🔄 设立多种负载均衡器,确保 GPU 间的资源高效利用,避免性能瓶颈。