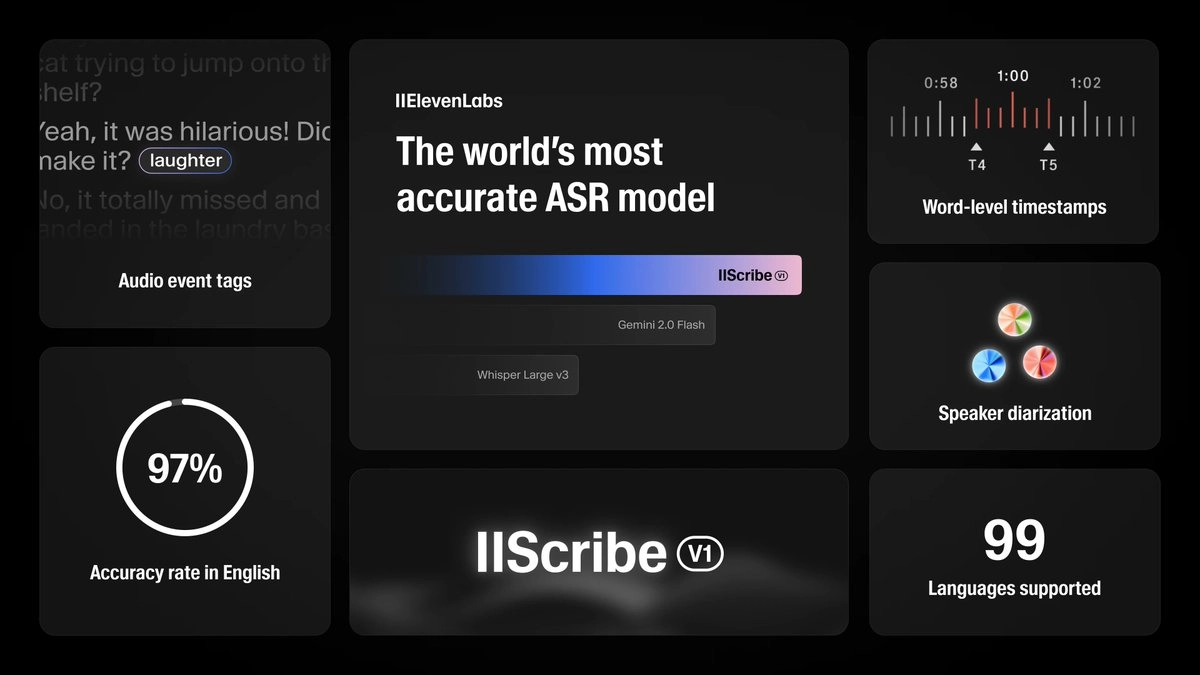
ElevenLabs 推出的自动语音识别(ASR,Automatic Speech Recognition)模型:Scribe,被称为全球最精准的语音转文字(Speech-to-Text)模型。它在基准测试中具有最高的准确性,超越了之前的顶尖模型,如 Gemini 2.0 和 OpenAI Whisper v3。
它能够处理 99 种语言的语音转录,并适用于各种真实世界的音频场景,如 会议记录、电影字幕、歌曲歌词转录等。
Scribe 的主要功能
- 多语言支持:能够精准转录 99 种语言 的语音内容,并减少对低资源语言(如塞尔维亚语、粤语和马拉雅拉姆语)的识别误差。
高精准度语音转文字:
- 在多个行业基准测试(FLEURS & Common Voice)中表现优异。
- 意大利语识别准确率达 98.7%,英语达 96.7%。
高级语音处理能力:
- 逐字时间戳(Word-level Timestamps):提供单词级时间戳,便于字幕同步或音频编辑。
- 说话人分离(Speaker Diarization):可识别并区分同一音频中最多 32 个不同的说话者。
- 音频事件标注(Audio-event Tagging):能够标记笑声、鼓掌、背景噪音等非语言元素,丰富转录内容。
API 支持 & 易集成:
- 提供 结构化 JSON 输出,开发者可轻松集成到自己的应用或平台。
目前只能处理预录制的音频和视频文件,未来将推出 低延迟实时转录版本,支持直播、会议等实时转录需求。
优势
行业领先的准确性:
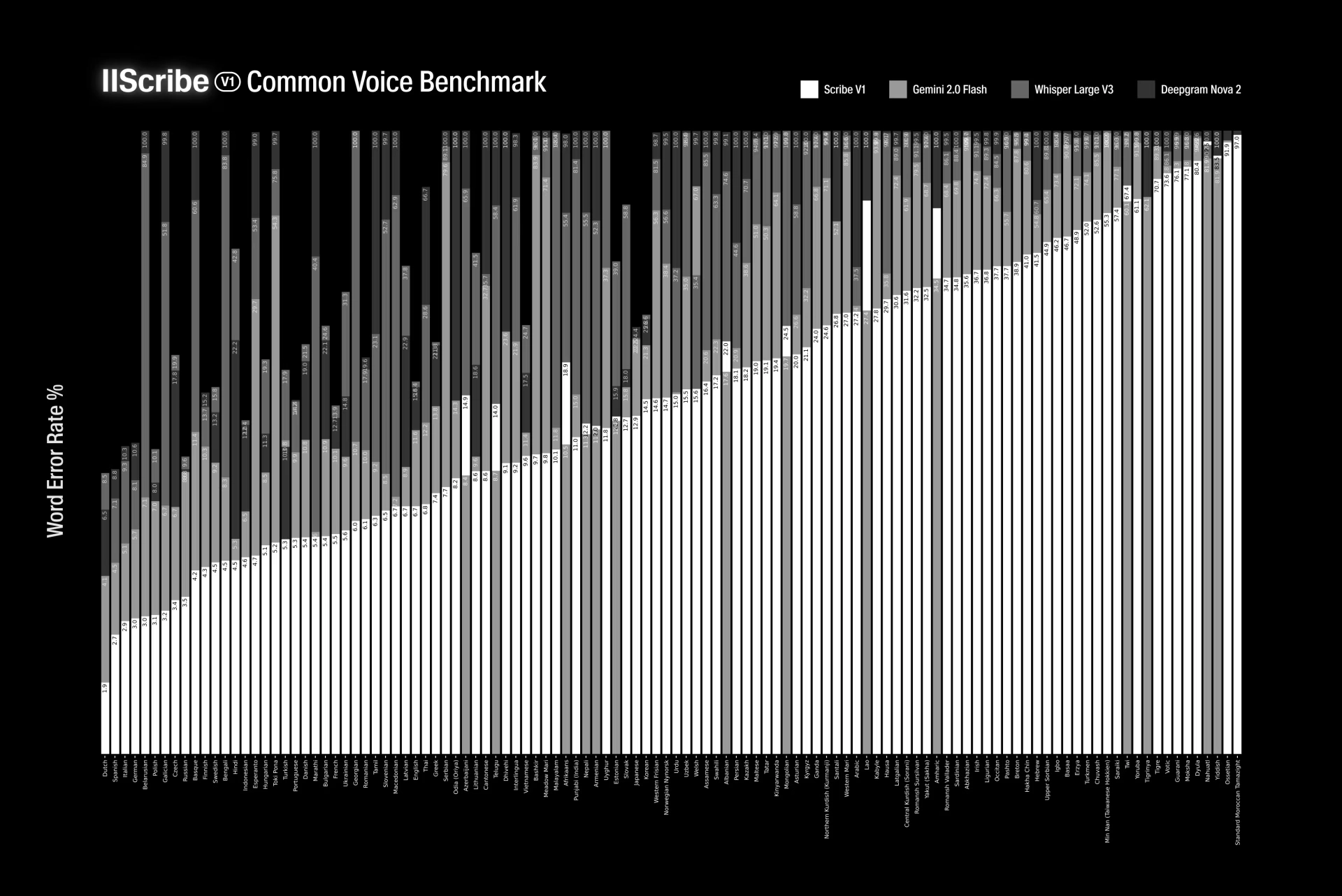
Scribe 在几乎所有语言的关键 ASR 基准测试中表现优于顶级模型,如 Gemini 2、Whisper Large v3 和 Deepgram。
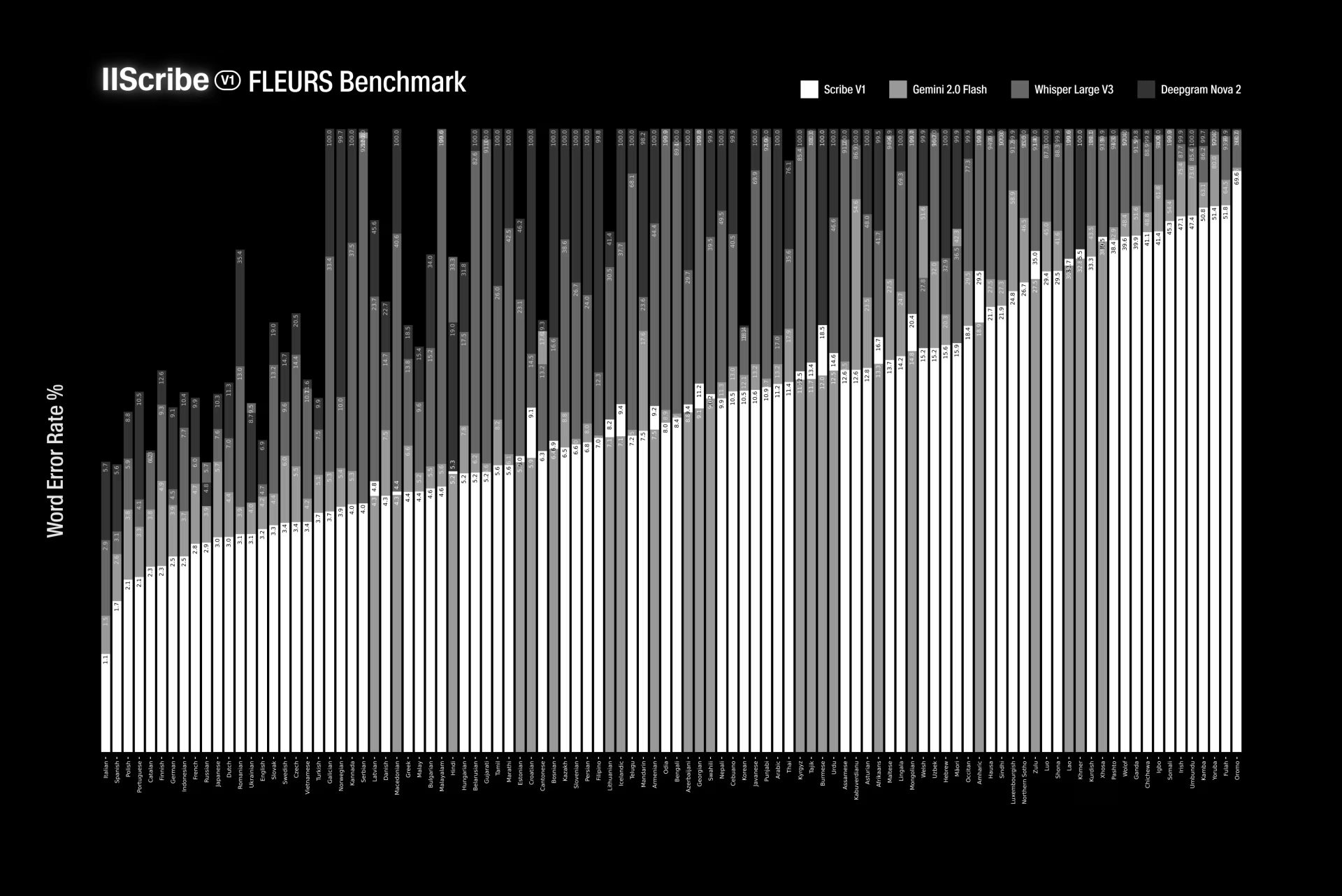
- 在 FLEURS & Common Voice 测试中,Scribe 在 102 种语言 上实现了 最低的单词错误率。
Scribe 的单词错误率(WER)低于谷歌 Gemini 2.0 Flash、OpenAI Whisper v3 和 Deepgram Nova-3,尤其在意大利语(WER 1.3%)、英语(WER 3.3%)等语言上表现突出。
低资源语言优化:
- 对传统模型表现较差的语言(如塞尔维亚语、马拉雅拉姆语)实现了显著改进,WER 大幅降低。
复杂场景适应性:
- • 在嘈杂环境或多说话者场景中仍能保持高精度,适合现实世界的多样化需求。
功能丰富:
- 提供话者分割、时间戳和非语音事件检测,超越了许多竞争对手的基础转录功能。
定价竞争力:
- 每小时音频 0.40 美元,发布后六周内折扣至 0.20 美元/小时,相较于市场上类似服务具有吸引力。
易于集成:
- 通过仪表板上传文件或 API 调用即可使用,满足不同用户需求。
API文档:API Documentation