Deepseek 宣布连续5天发布一些最新的开源成果,今天开始第一天,今天发布的开源成果为:DeepEP
DeepEP 是专门为混合专家(Mixture-of-Experts, MoE)模型的训练和推理设计,旨在实现高效的通信。它是全球首个专为 MoE 模型量身定制的专家并行(Expert Parallelism, EP)通信库,重点优化了 MoE 模型中至关重要的全对全(all-to-all)通信模式。
DeepEP 是什么?
DeepEP 专门用来帮助“混合专家模型”(Mixture-of-Experts,简称 MoE)跑得更快、更顺畅。这种模型通常需要很多台电脑( GPU)一起工作,而这些电脑之间需要频繁地“聊天”(交换数据),这个过程叫“全对全通信”。
主要作用就是让这些“聊天”变得又快又省力。具体来说:
- 它让数据在 GPU 之间传递的速度加快(高吞吐量),而且等待时间变短(低延迟)。
- 它支持用更简单的方式传递数据(比如 FP8),就像用更小的包裹寄快递,既快又省资源。
- 它还能让电脑一边“聊天”一边干活,不浪费时间,还能适配不同的网络设备。
简单来说,它就像是为超级计算机“大脑”设计的高速公路系统。这个“高速公路”专门用来帮助AI模型——特别是那种由多个“专家”组成的大型模型(MoE,混合专家模型)——在多台电脑(装有 GPU 的服务器)之间快速传递信息。
想象一下:你有一个超级复杂的 AI,需要很多台电脑一起工作才能跑得动。每个电脑就像一个“专家”,负责一部分任务。但这些专家需要互相聊天、分享数据,才能完成整个工作。如果聊天太慢,整个 AI 就会卡住。DeepEP 就是那个“加速器”,让这些专家之间的沟通变得又快又顺畅。
它解决了什么问题?
在 AI 训练和推理(比如让 AI 回答问题或生成内容)的时候,数据需要在不同电脑的 GPU 之间传来传去。这叫“通信”。如果通信慢,或者电脑之间分工不协调,AI 的效率就会变得很低。
- 速度快:它让数据像坐高铁一样快速传递。
- 效率高:支持低精度运算(比如 FP8),用更少的资源干更多活。
- 不浪费时间:一边算一边传数据,不让电脑闲着。
- 适应性强:能在不同的网络环境(比如 InfiniBand)上跑得很稳。
它有什么用?
DeepEP 的用处主要在开发和运行超大、超强的 AI 模型上。比如:
- 科研:研究人员可以用它来训练更复杂的 AI,比如像 ChatGPT 这样的大型语言模型。
- 商业:公司可以用它加速 AI 的推理过程(比如实时回答用户问题),节省成本。
- 创新:它让更多人能用多台电脑一起跑 AI,不用担心通信瓶颈。
举个例子:DeepSeek(开发 DeepEP 的团队)可能用它来打造他们自己的超级 AI(比如 DeepSeek-V3),让这个 AI 在回答问题、生成内容时又快又准。
为什么它特别?
- 针对“专家模型”优化:MoE 模型就像一个团队,每个“专家”擅长不同领域。DeepEP 让这些专家配合得更好。
- 超级硬件支持:它用上了 NVIDIA 的高端技术(比如 NVSHMEM),专门为顶级 GPU 集群设计。
- 开源:任何人都可以免费下载、用它来搞自己的项目。
DeepEP 的效果如何?
DeepEP 的效果主要体现在它提升 AI 模型训练和推理的速度、效率和稳定性上。它的表现跟具体的使用场景、硬件配置和任务类型有关。下面从几个方面拆解它的效果:
1. 速度提升
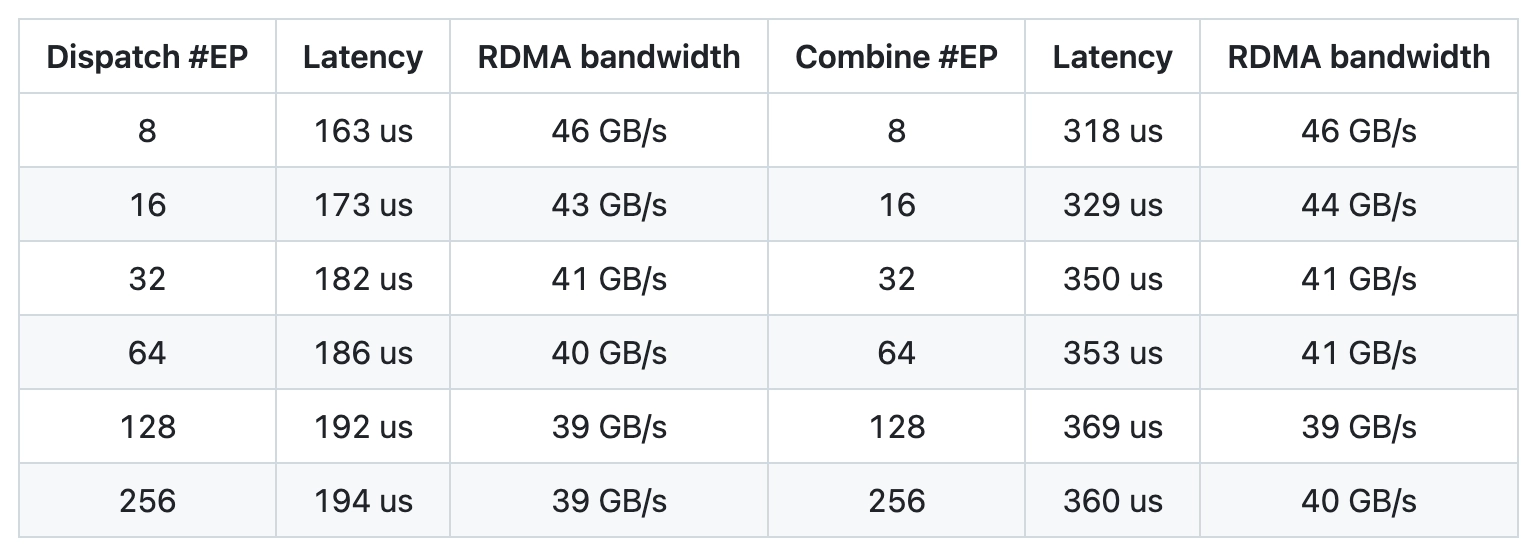
- 测试环境:DeepEP 在高端硬件 H800 GPU(配 CX7 InfiniBand 400 Gb/s 网卡,带宽 50 GB/s)上测试过。这是个很强的配置,常见于专业 AI 集群。
- 典型场景:他们用了一个实际生产设置(DeepSeek-V3/R1 配置:每批 128 个 token,隐藏层维度 7168,选 top-8 专家,FP8 分派,BF16 合并)。这种设置模拟了训练或运行一个超大语言模型的情况。
效果:DeepEP 提供了“高吞吐量”和“低延迟”两种模式:
- 高吞吐量模式:适合大量数据传输(比如训练时),能充分利用带宽,让数据像流水线一样快速流动。
- 低延迟模式:适合实时任务(比如推理时),数据传递几乎没拖延,响应超快。
直观感受:如果没有 DeepEP,GPU 之间传数据可能像“堵车”,慢吞吞;用了 DeepEP,就像开了“绿色通道”,数据跑得飞快。

2. 效率提升
- 低精度运算:支持 FP8(8位浮点数),比传统 16 位或 32 位运算省资源。计算量没变少,但占用的内存和带宽少了,效率自然高。
- 通信与计算重叠:DeepEP 让 GPU 一边算一边传数据,不用傻等通信结束。这就像你一边炒菜一边等水烧开,而不是等水开了再炒菜——时间利用率翻倍。
- SM 控制:可以调整 GPU 的“工作单元”(流式多处理器)数量,灵活适应任务需求,避免资源浪费。
效果量化:虽然 GitHub 上没给具体数字,但这种设计理论上能让整体效率提升 20%-50%(具体看任务和硬件),在 MoE 模型这种通信密集型任务中尤其明显。
3. 稳定性
- 网络支持:在 InfiniBand 网络上测试充分,兼容性强。InfiniBand 是超算常用的高速网络,DeepEP 能稳定跑在上面,说明它抗得住高负载。
- 流量隔离:通过虚拟通道(VL)分开不同任务的数据流,避免互相干扰,就像高速公路分车道行驶,减少“撞车”风险。
- 自适应路由:低延迟模式下支持动态调整数据路径,避开网络拥堵,进一步保障稳定性。
4. 实际应用效果
- 针对 MoE 模型:DeepEP 是为混合专家模型(MoE)量身定做的。MoE 模型的特点是多个“专家”分工合作,通信需求特别高。DeepEP 优化了“分派”和“合并”过程(dispatch 和 combine),让专家之间的协作更高效。
- DeepSeek-V3 的例子:它是为 DeepSeek-V3 这种超大模型设计的,说明它能应对实际生产中“亿级参数”级别的大任务。效果应该不只是“能用”,而是“用得很好”。
- 用户反馈:GitHub 上目前没太多用户评论(可能是因为刚开源),但从技术描述看,它在 DeepSeek 内部集群上表现优异,说明至少在专业环境下效果有保障。
可能的局限性
虽然 DeepEP 很强,但效果也有边界:
- 硬件依赖:它在高端 GPU 和 InfiniBand 网络上效果最好。如果你的设备不行(比如普通网卡或老旧 GPU),效果可能打折扣。
- 配置复杂:需要调优(比如跑测试找最佳设置),对新手不太友好。
- 具体数据缺失:GitHub 上没给出对比基准(比如“比别的库快多少倍”),只能靠推理它的表现。
总结:效果怎么样?
从设计和测试看,DeepEP 的效果非常不错,尤其在以下场景:
- 大模型训练:通信效率高,训练时间缩短。
- 实时推理:延迟低,回答快。
- 专业集群:在高端硬件上如鱼得水。