阿里巴巴发布全新的开源视频模型Wan2.1,支持图片生成视频、文本生成视频、视频编辑等任务。
Wan2.1拥有四个不同的型号:
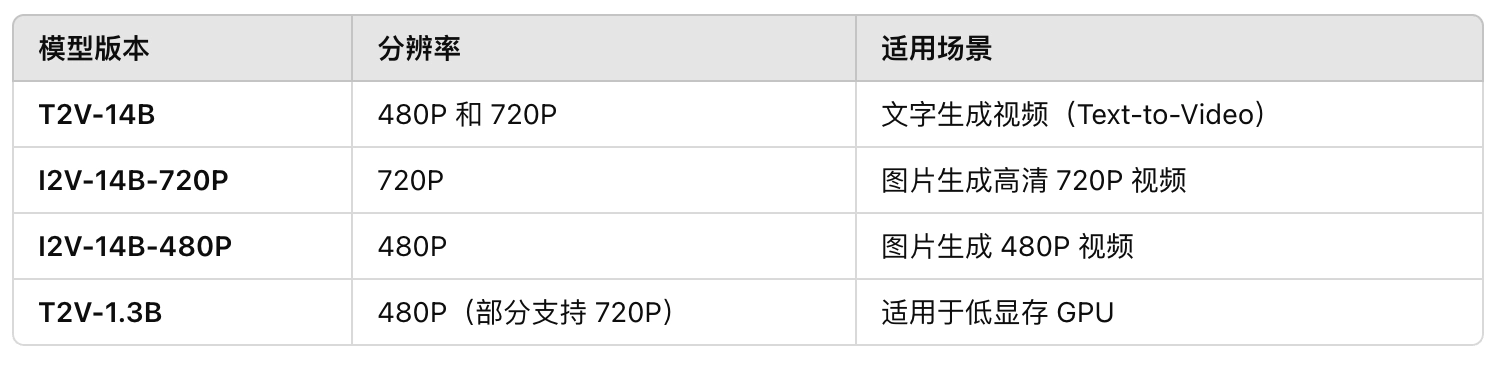
✅ 全球领先的 AI 视频生成模型,支持 720P 高清视频
✅ 适合普通 GPU 运行,无需超级计算机
✅ 完全开源,适用于个人开发者、研究人员、影视制作团队
✅ 支持多种任务:文本生成视频、图片生成视频、视频转音频等
主要特性
最先进的视频生成性能(SOTA)
- 在多项基准测试中,Wan2.1 超越了开源和商业闭源视频模型,生成质量达到业界领先水平。
兼容消费级 GPU
🖥 低显存需求:
- Wan2.1 T2V-1.3B 版本仅需 8.19GB 显存,适用于大多数消费级 GPU(如 RTX 3090、RTX 4090)。
- 在 RTX 4090 上大约 4 分钟生成 5 秒 480P 视频,并支持 720P。
🔹 相比其他闭源 AI 视频模型,Wan2.1 计算资源需求更低!适合个人开发者和研究者使用。
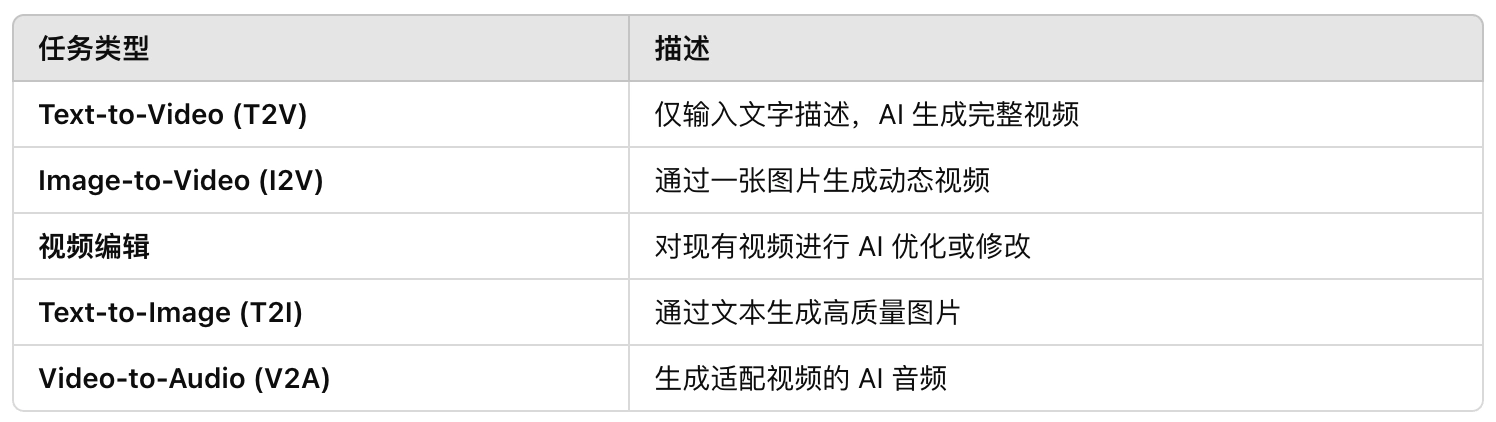
支持多种任务
- 文本生成视频(T2V):基于文本描述生成高质量视频。
- 图片生成视频(I2V):输入静态图片,生成动态视频。
- 视频编辑:对已有视频进行修改和优化。
- 文本生成图像(T2I):支持文本到图像生成。
视频生成音频(V2A):可以为视频自动生成匹配的音频。
特别亮点:
- 可以在视频中生成中英文字幕,这是目前大部分 AI 视频生成工具无法做到的。
- 生成的视频带有自然的运动感,不像早期 AI 视频那样有大量失真和伪影。
强大的 AI 变分自编码器(VAE)
Wan2.1 采用了先进的 3D 时空变分自编码器(3D VAE),能做到:
✅ 更高效的视频压缩,降低计算量,同时保留时间一致性。
✅ 支持 1080P 长视频,不会丢失时间信息。
✅ 相比传统 VAE,处理速度更快,质量更高。
模型架构
3D 变分自编码器(VAE)
- 创新 3D 时空 VAE 结构,优化视频数据压缩,降低显存使用,同时保证时间一致性。
Diffusion Transformer (DiT) 视频生成架构
- 采用 Flow Matching 训练框架,结合 Transformer 进行文本到视频生成。
- 采用 T5 编码器处理文本,支持多语言文本输入。
大规模数据集训练
- 大规模数据集去重与清洗,确保训练数据的质量和多样性。
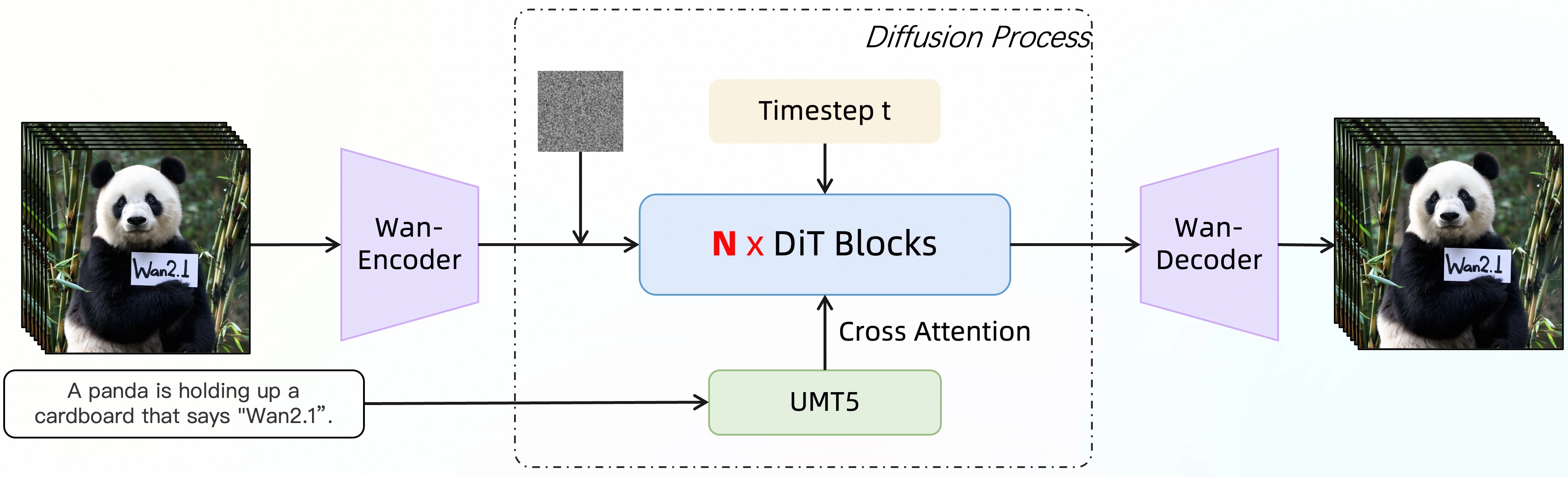
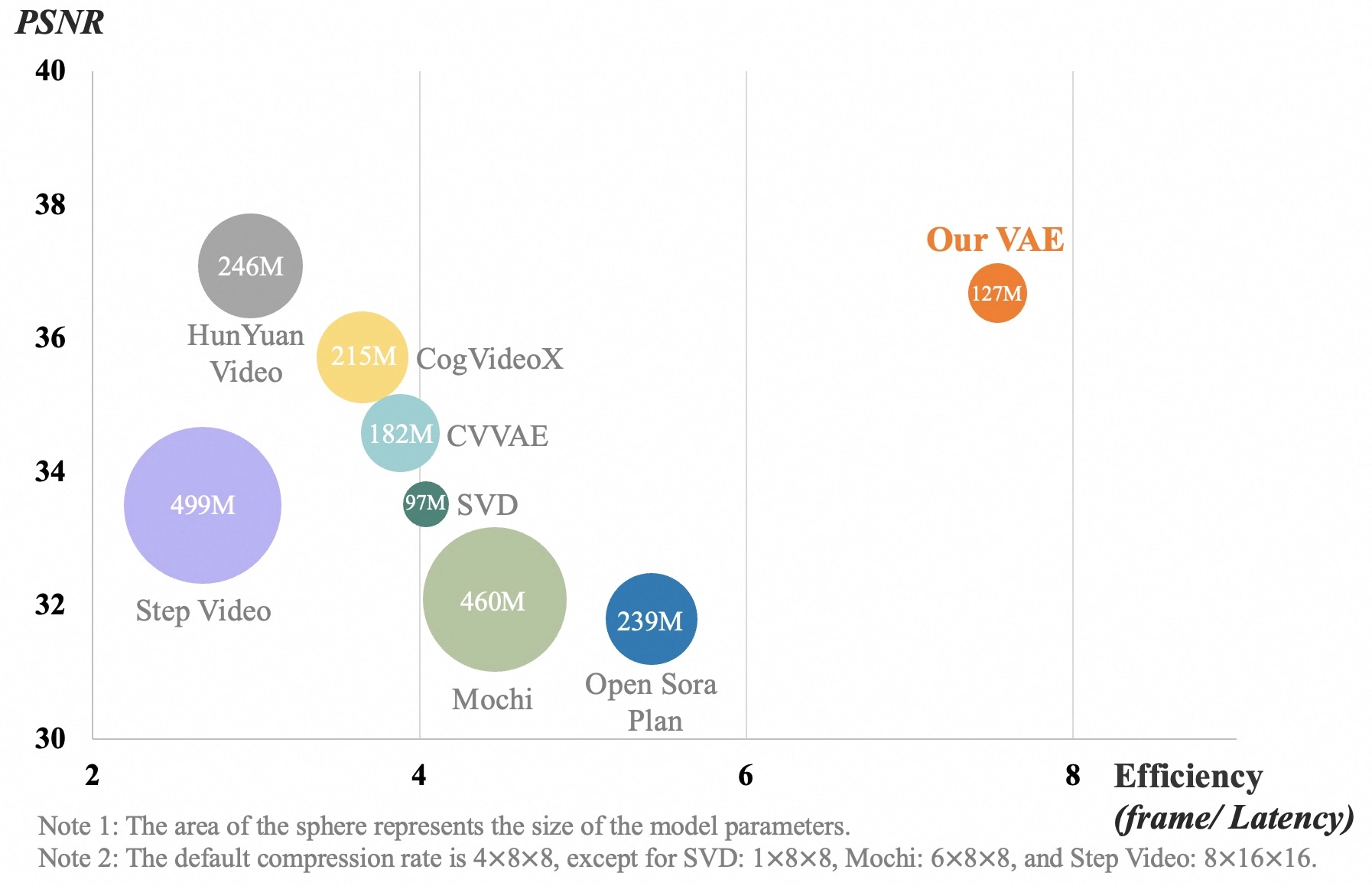
性能对比
在 1,035 个测试样例中,Wan2.1 在 14 个主要维度和 26 个子维度 上进行评估,最终综合得分超越了现有的开源和闭源模型:
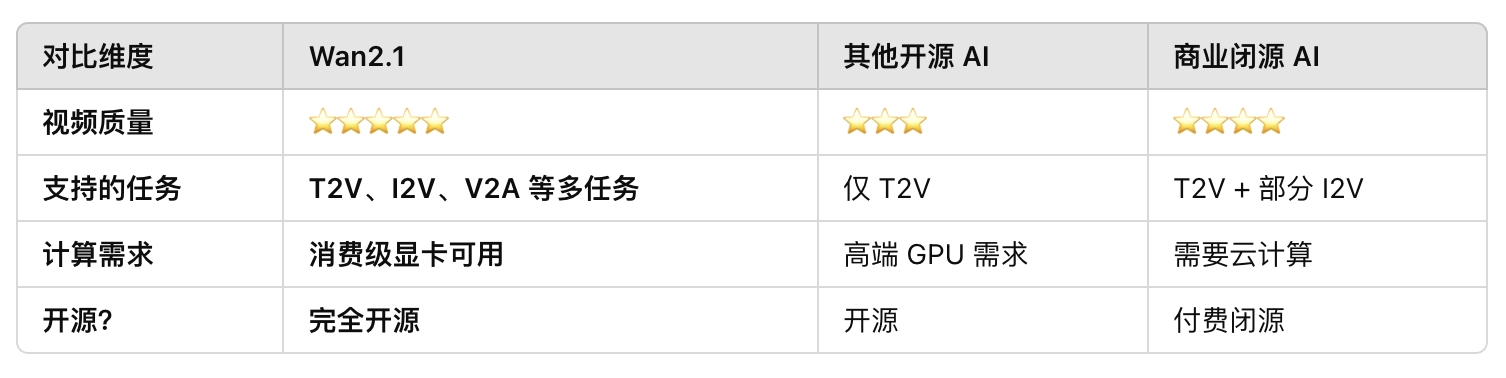
Wan2.1 兼顾了视频质量、计算成本和开源优势,适合个人开发者和 AI 研究人员使用!
🎯 立即体验!
你可以通过以下方式使用 Wan2.1:
- 前往 Hugging Face 官网 下载模型
- 安装依赖并运行本地测试
使用 Gradio Web 界面进行交互
bash复制编辑cd gradio python i2v_14B_singleGPU.py --ckpt_dir_720p ./Wan2.1-I2V-14B-720P