近日,通义宣布开源其最新的通义万相大模型 Wan2.1。Wan2.1是一款专注于高质量视频生成的 AI 模型,凭借其在处理复杂运动、还原真实物理规律、提升影视质感以及优化指令遵循方面的卓越表现,成为了创作者、开发者和企业用户拥抱 AI 时代的首选工具。

在权威评测集 Vbench 中,通义万相 Wan2.1以总分86.22% 的成绩登顶榜首,大幅领先国内外其他知名视频生成模型,如 Sora、Minimax、Luma、Gen3和 Pika 等。这一成就得益于 Wan2.1基于主流的 DiT 和线性噪声轨迹 Flow Matching 范式,通过一系列技术创新实现了生成能力的重大进步。其中,自研高效的3D 因果 VAE 模块实现了256倍无损视频隐空间压缩,并通过特征缓存机制支持任意长度视频的高效编解码,同时减少了29% 的推理时内存占用。此外,该模型在单个 A800GPU 环境下,视频重建速度比现有最先进方法快2.5倍,展现出显著的性能优势。
Wan2.1的视频 Diffusion Transformer 架构通过 Full Attention 机制有效建模长时程时空依赖,生成高质量且时空一致的视频。其训练策略采用6阶段分步训练法,从低分辨率图像数据的预训练逐步过渡到高分辨率视频数据的训练,并在最后通过高质量标注数据进行微调,确保模型在不同分辨率和复杂场景下的出色表现。在数据处理方面,Wan2.1设计了四步数据清洗流程,重点关注基础维度、视觉质量和运动质量,以从嘈杂的初始数据集中筛选出高质量且多样化的数据,促进有效训练。
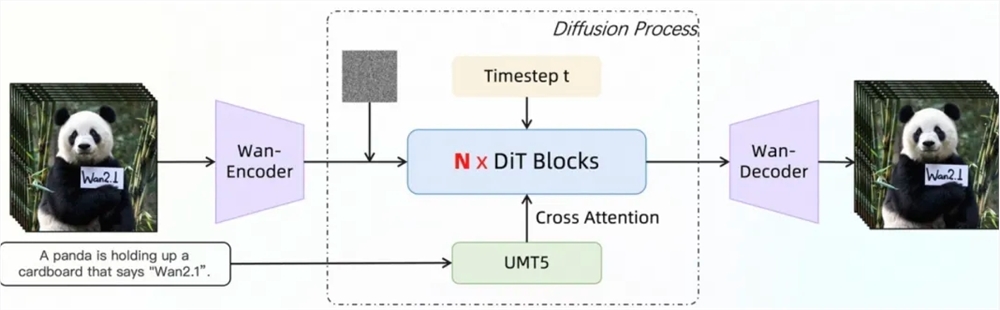
在模型训练和推理效率优化方面,Wan2.1采用了多种策略。训练阶段,针对文本、视频编码模块和 DiT 模块,分别采用不同的分布式策略,并通过高效的策略切换避免计算冗余。显存优化方面,采用分层的显存优化策略,结合 PyTorch 显存管理机制解决显存碎片问题。推理阶段,使用 FSDP 和2D CP 的组合方法进行多卡分布式加速,并通过量化方法进一步提升性能。
目前,通义万相 Wan2.1已在 GitHub、Hugging Face 和魔搭社区等平台开源,支持多种主流框架。开发者和研究者可以通过 Gradio 快速体验,或利用 xDiT 并行加速推理提升效率。同时,该模型正在加速接入 Diffusers 和 ComfyUI,以简化一键推理与部署流程,降低开发门槛,为用户提供灵活的选择,无论是快速原型开发还是高效生产部署,都能轻松实现。
Github:https://github.com/Wan-Video
HuggingFace:https://huggingface.co/Wan-AI
在线体验:https://tongyi.aliyun.com/wanxiang