Claude 的推理思考(Extended Thinking)【译】
 有些事情,我们几乎瞬间就会想到答案,比如“今天是星期几?”。但也有一些事情需要更大的脑力投入,例如解一道有难度的填字谜题或排查一段复杂的代码错误。我们可以根据手头的任务,自由选择要投入多大程度的认知努力。
有些事情,我们几乎瞬间就会想到答案,比如“今天是星期几?”。但也有一些事情需要更大的脑力投入,例如解一道有难度的填字谜题或排查一段复杂的代码错误。我们可以根据手头的任务,自由选择要投入多大程度的认知努力。
现在,Claude 也具备了这种灵活性。我们在最新的Claude 3.7 Sonnet中引入了“延伸思考模式”(extended thinking mode)的切换开关,用户可以根据问题难度让模型进行更深入的思考。1 开发者还可以设置一个“思考预算”(thinking budget),从而精确控制 Claude 在思考某个问题时所花费的时间。
需要强调的是,“延伸思考模式”并不是切换到一个截然不同、拥有独立策略的模型;而是让同一个模型在回答时拥有更多的思考时间并付出更多努力。
Claude 新增的延伸思考功能在“智慧”层面带来了显著提升。但对于关注 AI 模型工作方式、评估方法以及如何提升安全性的人来说,也因此引发了许多重要问题。本文中,我们将分享自己的一些洞见。
可见的思考过程
我们不仅赋予了 Claude 更长的思考时间,从而能够回答更棘手的问题,还让它的思考过程以“原始”形式对外可见。这么做有多重好处:
- 信任(Trust):能够直接观察 Claude 的思考过程,更容易理解并检验它的答案,也可能帮助用户获得更好的结果。
- 对齐(Alignment):在我们之前的一些对齐科学(Alignment Science)研究中,通过模型内部思考和对外回答的矛盾,可以发现模型是否出现了诸如故意欺骗等令人担忧的行为。
- 趣味(Interest):看着 Claude 进行思考常常令人着迷。一些有数学或物理背景的研究人员指出,Claude 的思考过程与他们自己思考复杂问题时的思路令人惊讶地相似,往往会从多个角度出发,不断反复检验结果。
然而,让思考过程可见也带来了一些弊端。首先,用户可能会注意到,这种显露出来的思考内容在语气上更客观、疏离,少了默认输出中常见的“人格化”风格。这是因为,我们并没有对模型的思考过程进行常规的角色化(character)训练。我们希望给 Claude 最大的自由度,以便让它进行各种必要的思维活动——而与人类的思考相似,Claude 的内部思路也可能包含错误、误导或不成熟的想法。许多用户可能会觉得这种形式很有价值,但也有人会认为它过于“生硬”,缺乏人情味。
另一个问题是“忠实度(faithfulness)”:我们并不确定思考过程里显示的内容是否真的就是模型内部真实发生的思维活动(例如,使用英文词汇是否就能准确描述模型为何会表现出某种行为)。如何确保忠实度是我们正在积极研究的课题之一。目前的研究表明,模型经常基于许多并没有在思考过程中“显式提及”的因素来做出决策。这意味着,仅靠观察当前模型的思考过程,就很难对其安全性得出很强的结论。2
第三,这也带来了多重安全与保密层面的担忧。有恶意行为者可能利用可见的思考过程,更容易构建策略来对 Claude 进行“越狱”。更具推测性的是,如果模型在训练阶段就知道自己的内部思考会被展示,它也许会被激励去换一种思维方式,或者刻意隐藏某些想法,使其行为更难预测。
对于未来更强大的 Claude 版本而言,这类安全顾虑尤其迫切;一旦此类模型出现失对齐的情况,风险更高。我们会在未来版本中慎重权衡是否也让思考过程可见。3 目前,Claude 3.7 Sonnet 所提供的可见思考过程仍然算是一种研究预览版功能。
对 Claude 思考方式的新测试
Claude 的代理能力(Claude as an agent)
Claude 3.7 Sonnet 在“行动扩展(action scaling)”方面有所提升,能够反复调用函数,并对环境变化做出响应,持续执行,直至完成一个开放式任务。例如,它可以在用户的计算机环境中“点击鼠标”“键盘输入”来帮助解决某些任务。相比之前的版本,Claude 3.7 Sonnet 可以花费更多轮次的思考和更多的时间及计算资源,从而在此类任务中取得更优的结果。
我们可以用OSWorld测评结果来观察这种提升,该测评主要用于衡量多模态 AI 代理的能力。Claude 3.7 Sonnet 一开始就比前代表现更好,随着与虚拟计算机的持续交互,其性能优势不断拉大。
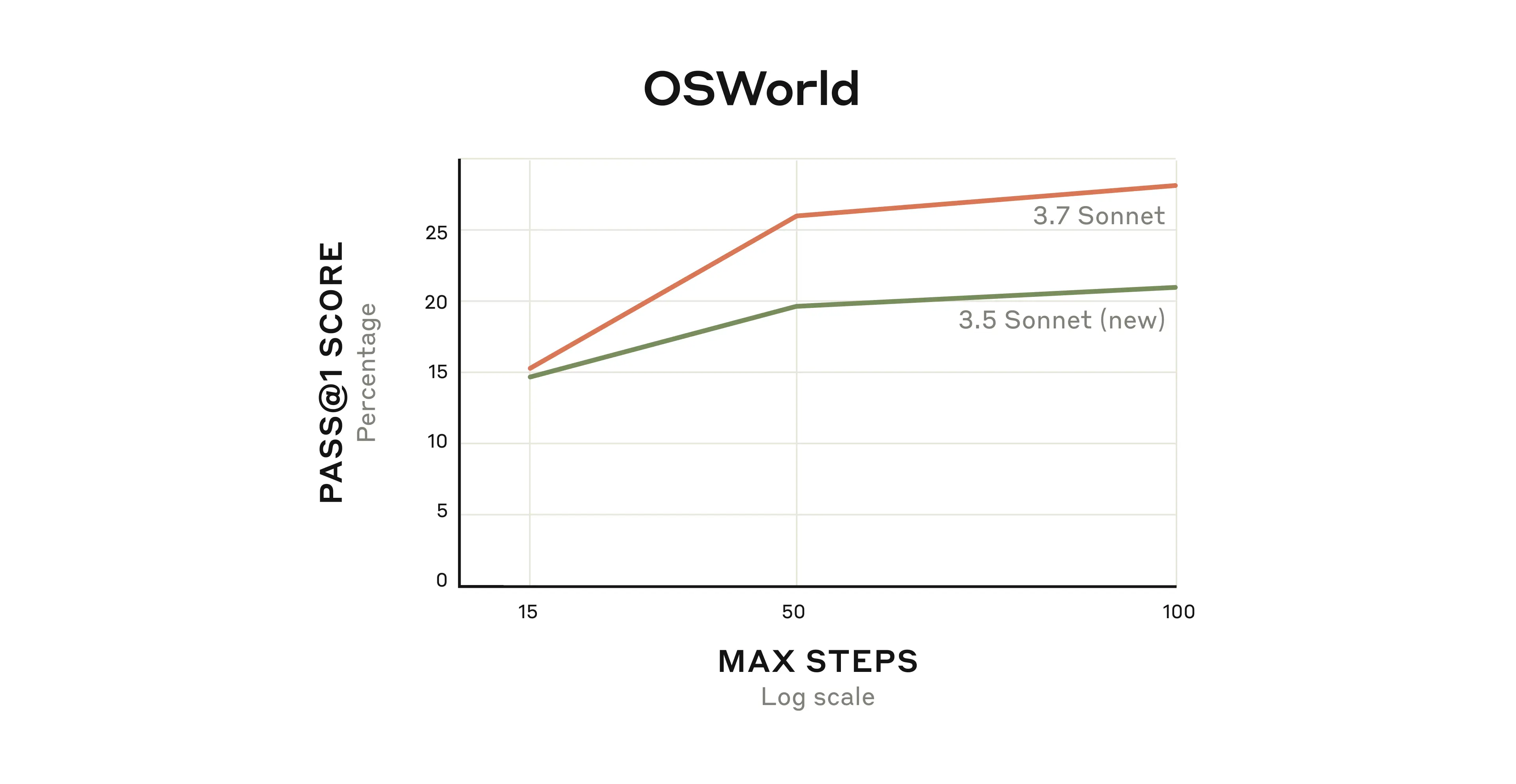 (上图)Claude 3.7 Sonnet 与前代模型在 OSWorld 测评(测试其多模态使用计算机的技能)中的表现对比。“Pass @ 1” 指的是模型在只有一次尝试机会时,是否能解决某个问题才能算通过。
(上图)Claude 3.7 Sonnet 与前代模型在 OSWorld 测评(测试其多模态使用计算机的技能)中的表现对比。“Pass @ 1” 指的是模型在只有一次尝试机会时,是否能解决某个问题才能算通过。
得益于延伸思考和代理能力训练,Claude 在许多标准评估(如 OSWorld)中都有进步。但它也能在一些意想不到的任务中展现显著提升。
一个有趣的示例是玩 Game Boy 经典游戏《精灵宝可梦:红》(Pokémon Red)。我们让 Claude 拥有基本的记忆功能、画面像素输入并可调用函数来模拟按键操作,从而在超出一般对话窗口的巨大交互量中持续进行游戏,突破数万次交互。
下图显示了 Claude 3.7 Sonnet 与过去不具备可延伸思考模式版本在玩《精灵宝可梦:红》时的进度对比。可以看到,之前的 Sonnet 版本很快就卡住了,Claude 3.0 Sonnet 甚至一直困在游戏初始的真新镇房子里。
而 Claude 3.7 Sonnet 依靠改进后的代理能力,成功战胜了三位道馆馆主(Gym Leader)并获得徽章(Badge)。这种在尝试不同策略、质疑先前假设方面的能力使得 Claude 可以在游戏中持续进步。
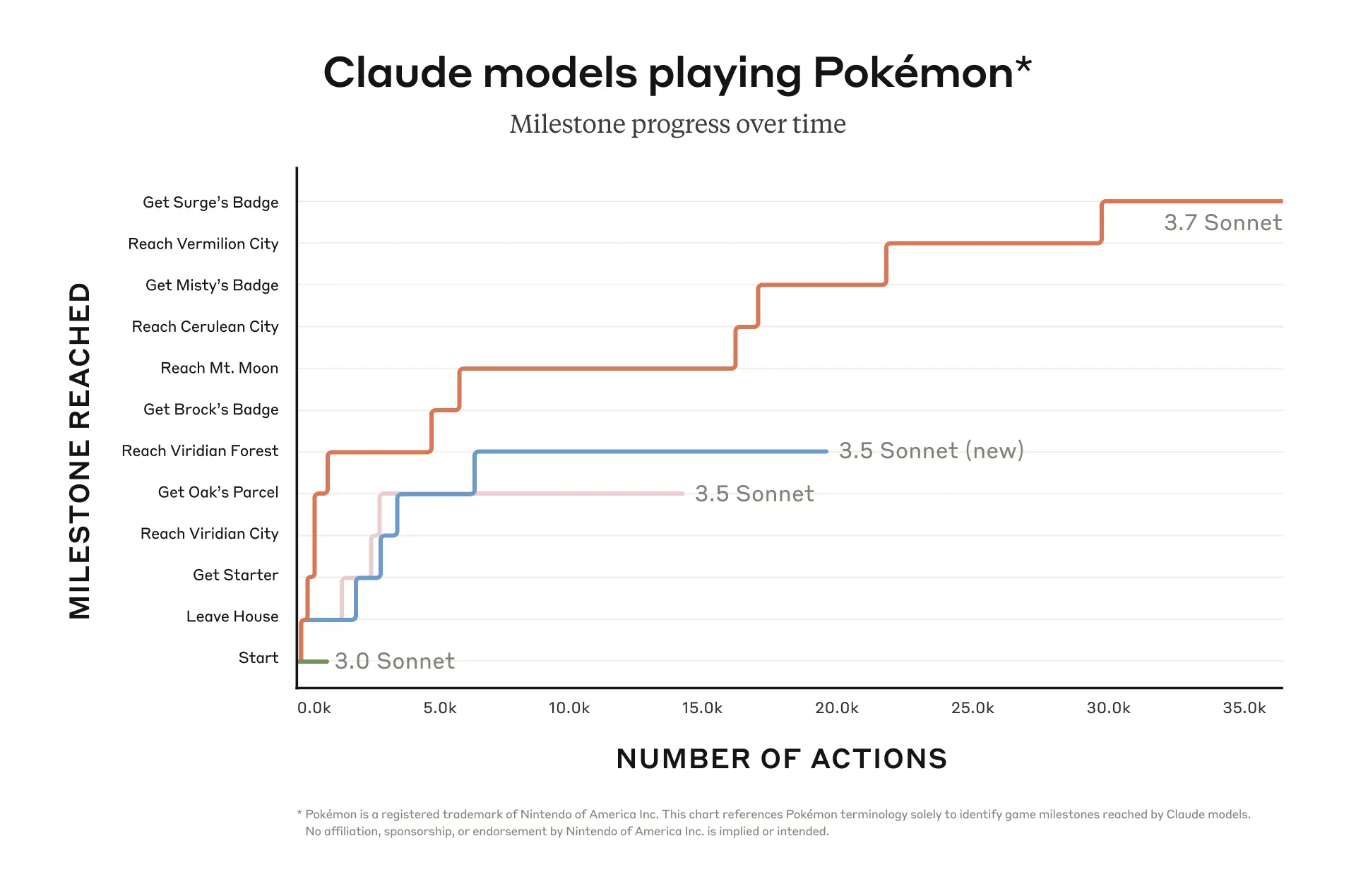 (上图)Claude 3.7 Sonnet 在玩《精灵宝可梦:红》时远胜之前的 Sonnet 版本。横轴表示 Claude 与游戏交互的总次数,纵轴是游戏中的里程碑事件(例如获取关键道具、到达新区域或打败道馆馆主)。
(上图)Claude 3.7 Sonnet 在玩《精灵宝可梦:红》时远胜之前的 Sonnet 版本。横轴表示 Claude 与游戏交互的总次数,纵轴是游戏中的里程碑事件(例如获取关键道具、到达新区域或打败道馆馆主)。
虽然拿《精灵宝可梦:红》举例很有趣,但 Claude 3.7 Sonnet 的这类能力在现实世界中还有更广阔的应用前景。它持续专注并完成开放式目标的能力,将帮助开发者构建各种最先进的 AI 代理系统。
“序列式”和“并行式”的推理资源扩展
Claude 3.7 Sonnet 的延伸思考功能,本质上可以视为“序列式测试时计算”(serial test-time compute)。也就是说,模型在输出最终答案之前,会先进行多步的连贯推理,在这个过程中分阶段地使用更多计算资源。一般来说,这会带来性能的提升。例如,在回答数学问题时,模型的准确度会随着“思考 token”上限的提高而呈对数式增长。
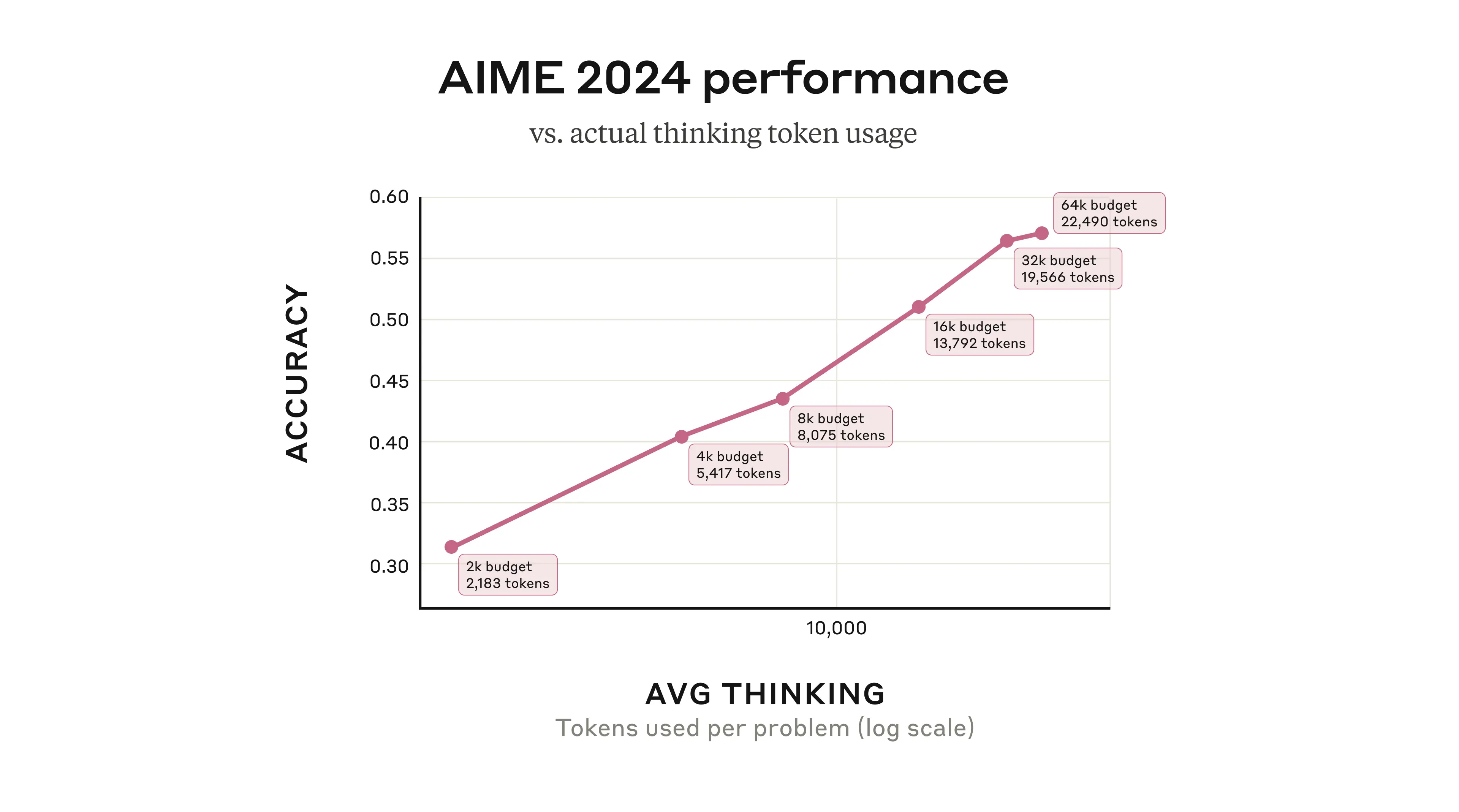 (上图)Claude 3.7 Sonnet 在回答 2024 年美国数学邀请赛(AIME 2024)题目时,随着思考 token(用于思考的最大长度)增加而带来的性能提升。需要注意的是,即使给定了最大思考预算,模型通常会在到达预算上限前就停止思考。图中也包含了用于输出最终答案的内容所消耗的 tokens。
(上图)Claude 3.7 Sonnet 在回答 2024 年美国数学邀请赛(AIME 2024)题目时,随着思考 token(用于思考的最大长度)增加而带来的性能提升。需要注意的是,即使给定了最大思考预算,模型通常会在到达预算上限前就停止思考。图中也包含了用于输出最终答案的内容所消耗的 tokens。
我们的研究人员还在尝试利用并行测试时计算来提升模型性能。具体做法是针对同一个问题,采样多条独立的思考过程(类似多条推理分支),再在不知晓正确答案的情况下,选出一个可能最佳的答案。常见方法包括多数票(majority)或共识投票,选择出现频率最高的答案;或利用另一个语言模型(同一个模型的第二实例)来检查这些答案,或者使用一个学到的打分函数来选出最优答案。其他不少模型的评估结果、论文或报告中也曾提到过类似方法。
在GPQA 测试集(常用于衡量生物、化学和物理方面的复杂问题)上,使用并行推理并配合一个训练出来的打分模型,以及最长 64k token 的延伸思考,Claude 3.7 Sonnet 可以达到 84.8% 的总分(其中物理子集的分数达 96.5%)。即便在超越多数投票的情况下继续增加并行程度,仍然持续见效。我们在下图中展示了使用打分模型和多数投票等方法的结果。
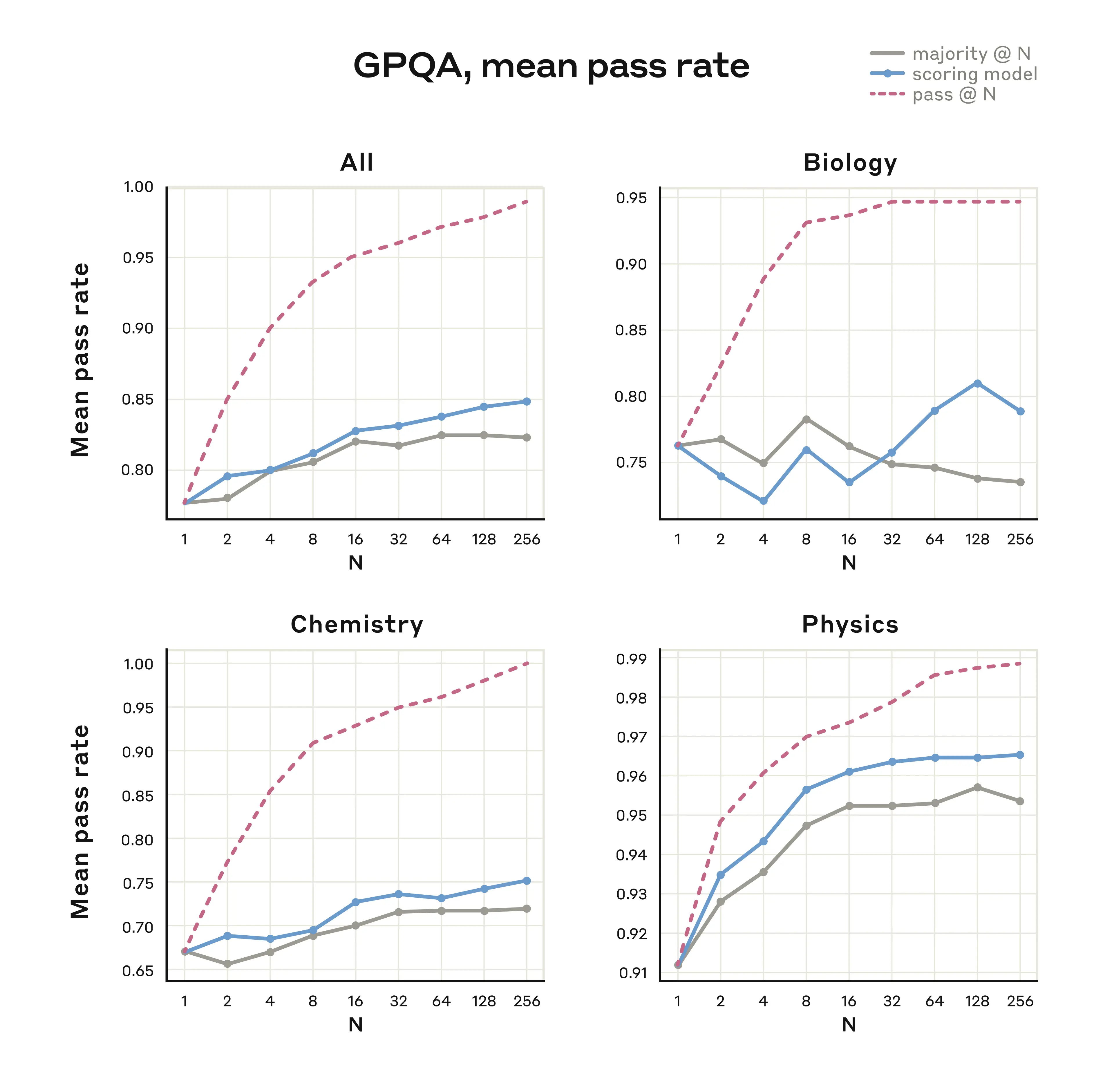 (上图)在 GPQA 测试集中利用并行推理拓展来提升 Claude 3.7 Sonnet 性能的实验结果。不同曲线分别对应不同的打分方法:
(上图)在 GPQA 测试集中利用并行推理拓展来提升 Claude 3.7 Sonnet 性能的实验结果。不同曲线分别对应不同的打分方法:
- “Majority @ N” 指针对相同问题采样 N 个答案后,采用多数投票作为最终结果;
- “scoring model” 表示用一个单独的模型来评估多个候选答案,选出它认为最优的答案;
- “pass @ N” 表示如果在 N 次尝试中有一次成功则算通过。
通过这些方法,我们通常无需等待模型完成所有思考就能显著提高答案的质量。因为 Claude 可以并行地进行多条思考路径,从而能更全面地探索问题,并最终更可能给出正确答案。虽然并行推理目前还不在我们最新发布的 Claude 版本中开放,但我们仍在研究中,期待未来能够实现。
Claude 3.7 Sonnet 的安全机制
AI 安全等级(AI Safety Level)Anthropic 的负责任扩展政策(Responsible Scaling Policy)承诺,在对模型进行训练或部署之前,一定会实施适当的安全和防护措施。我们的前沿红队(Frontier Red Team)和对齐压力测试团队(Alignment Stress Testing team)对 Claude 3.7 Sonnet 进行了深入测试,以确认它是否需要与前代相同的 ASL-2(AI Safety Level 2)标准还是更高等级的安全和保密措施。
经过全面评估,我们认为对 Claude 3.7 Sonnet 依然维持 ASL-2 的安全标准是合适的。与此同时,该模型在各领域展现了更强的能力。在涉及化学、生物、放射和核(CBRN)武器相关任务的模拟研究中,我们发现,借助 Claude 的帮助,参与者确实比仅仅依靠网络公开信息走得更远。然而,在所有尝试中,都会出现关键信息缺失,最终导致无法成功完成上述危害性任务。
针对这款模型的专家红队测试反响不一。有专家指出,模型在 CBRN 相关流程上确实表现出更深入的知识。但关键点在于,它在执行端到端的攻击类任务时,仍然会反复出现关键信息或步骤缺失,无法完成真正的危害性操作。我们正在进一步加强 ASL-2 级别防护,包括加速开发针对性分类器和监测系统。
我们也考虑到,这款模型的未来迭代版本有可能需要升级到下一阶段的 ASL-3 安全措施。我们近期在宪法式分类器(Constitutional Classifiers)等方面所做的工作,为未来履行 ASL-3 的更高要求打下了良好基础。
可见的思考过程即使是 ASL-2 级别,Claude 3.7 Sonnet 将延伸思考过程“可见化”这一做法也比较新,因此需要相应的新防护措施。极少数情况下,Claude 的思考过程可能涉及潜在的高风险内容(例如与儿童安全、网络攻击或危险武器相关)。在此种情况下,我们会对思考过程中的相关片段进行加密处理:Claude 依然可以在内部思维阶段包含这些内容,但用户看不到具体的思考详情,而只会看到提示“the rest of the thought process is not available for this response”。我们希望这种加密处理的触发次数保持在较低水平,且仅在有较高潜在风险时才会触发。
计算机使用最后,在 Claude 的计算机使用功能(使 Claude 能够“看到”用户的电脑屏幕并代替用户执行操作)方面,我们也升级了安全保护措施。我们对抗“提示注入”(prompt injection)攻击取得了显著进展。在这类攻击中,恶意第三方会将隐藏指令置于 Claude 使用的界面中,试图欺骗 Claude 执行非用户意愿的操作。我们采用了新的对抗性训练,让模型更能抵御这些注入,同时在系统提示(system prompt)中明确说明,应当忽略此类攻击信息;此外还增加了一个在检测到可疑注入时会触发的分类器。通过这些措施,我们能在 88% 的攻击场景下抵御成功,明显高于不加防护时的 74%。4
上述只是我们在 Claude 3.7 Sonnet 上所做大量安全工作的简要摘要。如需获取更多信息、分析结果以及若干示例以了解这些防护如何实际运行,请参阅我们的完整系统报告(System Card)。
如何使用 Claude
你可以立即在Claude.ai上或者我们的 API中使用 Claude 3.7 Sonnet。正如 Claude 现在可以向你展示它在想什么,我们也希望收到你对这款新模型的反馈——欢迎发送到feedback@anthropic.com。
1注:原文中带脚注的内容,表明这是引用或说明性内容,并不代表用户可直接在该功能中为其提供额外参考信息。
2注:这一部分讨论了模型内部思考的“忠实度”问题,即显示出来的思考流程可能并不完整或完全反映实际决策过程。
3注:随着模型能力的进一步提升,对于是否公开内部思考过程,将需要更加审慎的权衡。
4注:这是在实验条件下的统计结果,实际应用中可能会因场景和对手方式不同而有所波动。