声明:本文来自于微信公众号 量子位,作者:允中,授权Soraor转载发布。
下面的两个有声书演播片段,你能分辨是真人还是AI合成的吗?

实际上这两个小说片段都是AI合成的,方案来自于豆包语音模型团队。为了逼近一流真人主播的演播效果,豆包语音模型基于原有Seed-TTS框架进一步加入上下文理解,最终实现了高表现力、高自然度、高语义理解的小说演播效果。
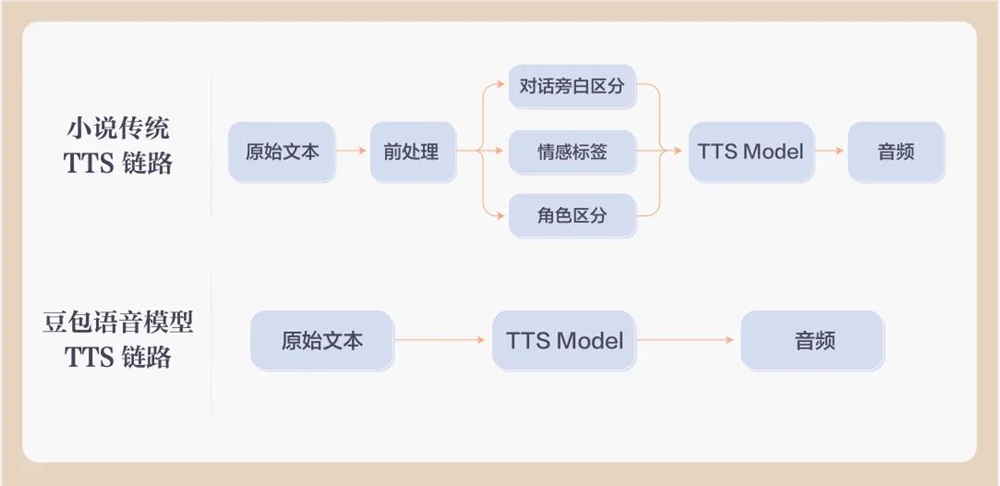
市面上很多的语音模型已经能保证足够自然的合成表现,但在音质、韵律、情感,以及多角色演绎上还有探索空间。特别是在小说演播场景下,想要媲美一流主播细腻的演播效果,要做好旁白和角色的区分演绎、角色情感的精确表达、不同角色的区分度等。
传统的小说TTS生成方式,需要提前给对话旁白、情感、角色打标签,而豆包语音模型则可以做到端到端合成,无需额外标签标注。
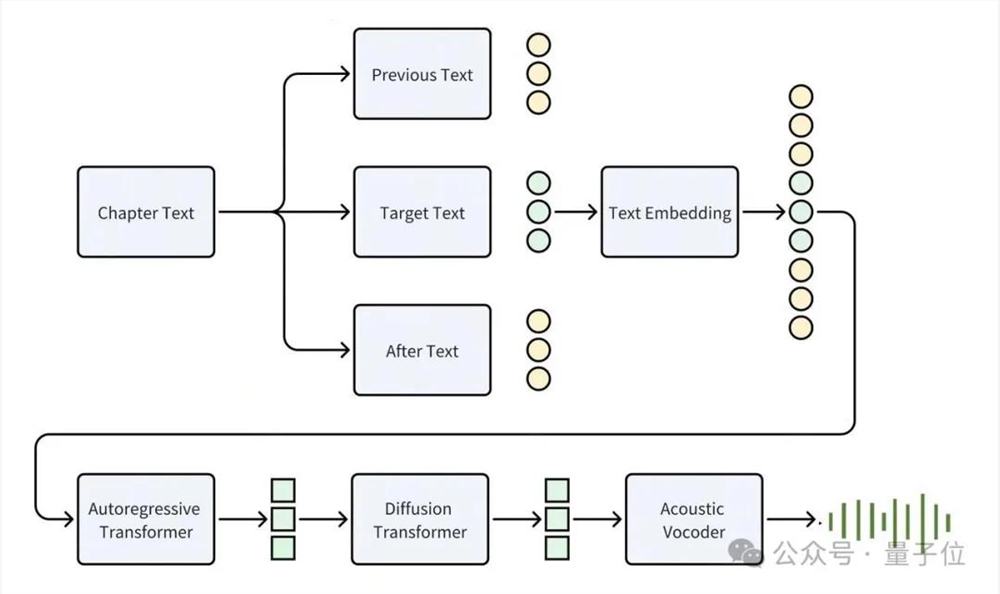
原始Seed-TTS(技术报告:https://arxiv.org/pdf/2406.02430)是一种自回归文本到语音模型,主要分为4个主要模块:Speech Tokenizer、Autoregressive Transformer、Diffusion Model、Acoustic Vocoder。
其中Speech Tokenizer解析了参考音频信息,决定了合成音频的音色和全局风格;Autoregressive Transformer接收传入的目标文本和Speech Tokenizer的输出,进而生成出包含语义信息的Semantic Token;Diffusion Model会基于Semantic Token建模出包含语音信息的Acoustic Token;Acoustic Vocoder负责将Acoustic Token重建还原出最终的音频。

为进一步提升小说演播下的语音表现力和长文本的理解,豆包技术团队对Seed-TTS进行了改进。
在数据上,小说音频做章节级别处理,保证了长文下的语音一致性和连贯性。
在特征上,融合TTS前端提取的音素、音调、韵律信息和原始文本,提升发音和韵律的同时,保留小说语义。
在结构上,将speech tokenizer改为speaker embedding,解除reference audio对于语音风格的限制,因而同一个发音人能在不同角色上作出更贴合人设的演绎。
最后在目标合成文本之外,额外加入了上下文的信息,从而使得模型能够感知更大范围的语义信息,旁白和角色音表现更精准到位。
经过专业评测,优化后的豆包语音模型在小说演播场景,CMOS(Comparative Mean Opinion Score,与真人打对比分的一种主观评分方式)已达一流主播的90%+效果。
豆包语音大模型团队以王明军、李满超两位演播圈大咖的声音为基础,采用新技术合成的千部有声书,已上线番茄小说,题材覆盖了历史、悬疑、灵异、都市、脑洞、科幻等热门书目类型。
据了解,未来豆包语音模型会继续探索前沿科技与业务场景的结合,追求更极致的“听”体验。
王明军演播试听:
李满超演播试听: