2025 年 2 月 21 日,阿里巴巴国际化团队宣布其新型多模态大语言模型Ovis2 系列正式开源。
Ovis2 是阿里巴巴国际化团队提出的Ovis系列模型的最新版本。与前序1. 6 版本相比,Ovis2 在数据构造和训练方法上都有显著改进。它不仅强化了小规模模型的能力密度,还通过指令微调和偏好学习大幅提升了思维链(CoT)推理能力。此外,Ovis2 引入了视频和多图像处理能力,并增强了多语言能力和复杂场景下的OCR能力,显著提升了模型的实用性。
此次开源的Ovis2 系列包括1B、2B、4B、8B、16B和34B六个版本,各个参数版本均达到了同尺寸的SOTA(State of the Art)水平。其中,Ovis2-34B在权威评测榜单OpenCompass上展现出了卓越的性能。在多模态通用能力榜单上,Ovis2-34B位列所有开源模型第二,以不到一半的参数尺寸超过了诸多70B开源旗舰模型。在多模态数学推理榜单上,Ovis2-34B更是位列所有开源模型第一,其他尺寸版本也展现出出色的推理能力。这些成绩不仅证明了Ovis架构的有效性,也展示了开源社区在推动多模态大模型发展方面的巨大潜力。
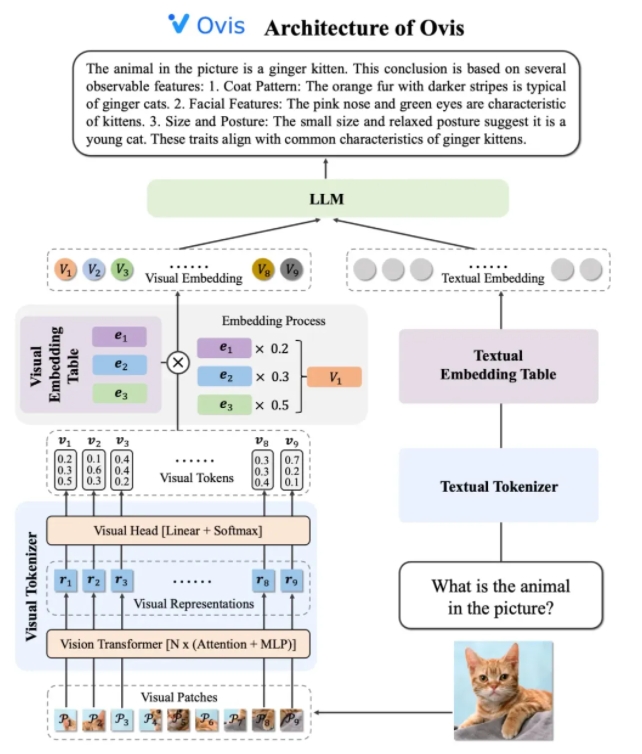
Ovis2 的架构设计巧妙地解决了模态间嵌入策略差异这一局限性。它由视觉tokenizer、视觉嵌入表和LLM三个关键组件构成。视觉tokenizer将输入图像分割成多个图像块,利用视觉Transformer提取特征,并通过视觉头层将特征匹配到“视觉单词”上,得到概率化的视觉token。视觉嵌入表存储每个视觉单词对应的嵌入向量,而LLM则将视觉嵌入向量与文本嵌入向量拼接后进行处理,生成文本输出,完成多模态任务。
在训练策略上,Ovis2 采用了四阶段训练方法,以充分激发其多模态理解能力。第一阶段冻结大部分LLM和ViT参数,训练视觉模块,学习视觉特征到嵌入的转化。第二阶段进一步增强视觉模块的特征提取能力,提升高分辨率图像理解、多语言和OCR能力。第三阶段通过对话形式的视觉Caption数据对齐视觉嵌入与LLM的对话格式。第四阶段则是多模态指令训练和偏好学习,进一步提升模型在多种模态下对用户指令的遵循能力和输出质量。
为了提升视频理解能力,Ovis2 开发了一种创新的关键帧选择算法。该算法基于帧与文本的相关性、帧之间的组合多样性和帧的序列性挑选最有用的视频帧。通过高维条件相似度计算、行列式点过程(DPP)和马尔可夫决策过程(MDP),算法能够在有限的视觉上下文中高效地选择关键帧,从而提升视频理解的性能。
Ovis2 系列模型在OpenCompass多模态评测榜单上的表现尤为突出。不同尺寸的模型在多个Benchmark上均取得了SOTA成绩。例如,Ovis2-34B在多模态通用能力和数学推理榜单上分别位列第二和第一,展现了其强大的性能。此外,Ovis2 在视频理解榜单上也取得了领先性能,进一步证明了其在多模态任务中的优势。
阿里巴巴国际化团队表示,开源是推动AI技术进步的关键力量。通过公开分享Ovis2 的研究成果,团队期待与全球开发者共同探索多模态大模型的前沿,并激发更多创新应用。目前,Ovis2 的代码已开源至GitHub,模型可在Hugging Face和Modelscope平台上获取,同时提供了在线Demo供用户体验。相关研究论文也已发布在arXiv上,供开发者和研究者参考。
代码:https://github.com/AIDC-AI/Ovis
模型(Huggingface):https://huggingface.co/AIDC-AI/Ovis2-34B
模型(Modelscope):https://modelscope.cn/collections/Ovis2-1e2840cb4f7d45
Demo:https://huggingface.co/spaces/AIDC-AI/Ovis2-16B
arXiv: https://arxiv.org/abs/2405.20797