在人工智能领域,语言模型的快速发展引发了语音理解语言模型(SULMs)的广泛关注。近日,西北工业大学 ASLP 实验室发布了开放语音理解模型 OSUM,旨在探索在学术资源有限的情况下,如何有效训练和利用语音理解模型,以推动学术界的研究与创新。
OSUM 模型融合了 Whisper 编码器与 Qwen2语言模型,支持8种语音任务,包括语音识别(ASR)、带时间戳的语音识别(SRWT)、语音事件检测(VED)、语音情感识别(SER)、说话风格识别(SSR)、说话人性别分类(SGC)、说话人年龄预测(SAP)及语音转文本聊天(STTC)。该模型通过采用 ASR+X 训练策略,能够在进行目标任务的同时高效稳定地优化语音识别,提升多任务学习的能力。
OSUM 模型的发布不仅注重性能表现,还强调透明性。其训练方法和数据准备过程均已开放,旨在为学术界提供有价值的参考与指导。根据技术报告 v2.0的介绍,OSUM 模型的训练数据量已提升至50.5K 小时,显著高于之前的44.1K 小时。其中,包括3000小时的语音性别分类数据和6800小时的说话人年龄预测数据。这些数据的扩展使得模型在各种任务中的表现更加优异。
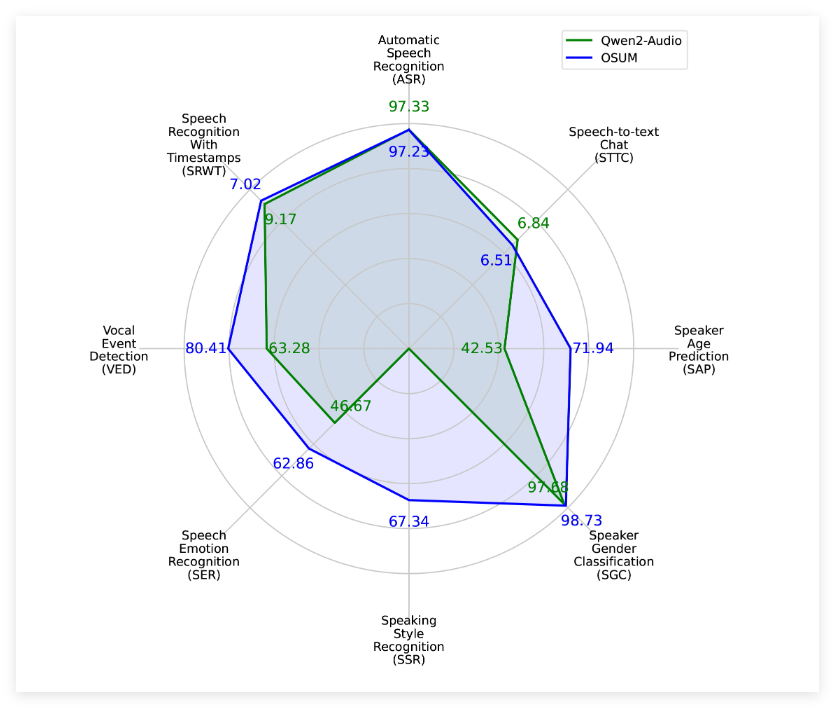
据评估结果显示,OSUM 在多项任务上优于 Qwen2-Audio 模型,即使在计算资源和训练数据方面明显较少。相关的评估结果不仅涵盖了公共测试集,还包括内部测试集,展示了 OSUM 模型在语音理解任务上的良好性能。
西北工业大学 ASLP 实验室表示,OSUM 的目标是通过开放的研究平台,促进先进语音理解技术的发展。科研人员和开发者可自由使用该模型的代码和权重,甚至可用于商业目的,从而加速技术的应用与推广。
项目入口:https://github.com/ASLP-lab/OSUM?tab=readme-ov-file
划重点:
🌟 OSUM 模型结合 Whisper 编码器与 Qwen2语言模型,支持多种语音任务,助力多任务学习。
📊 OSUM 在技术报告 v2.0中,训练数据量增至50.5K 小时,提升了模型的性能。
🆓 该模型的代码和权重在 Apache2.0许可下开放使用,鼓励学术界和工业界的广泛应用。