近日,由 Arc Institute 和 Nvidia 联合开发的 Evo2生物 AI 模型正式发布。这一基础模型基于超过10万种生物的 DNA 数据,旨在深度解码生物学中的各种复杂现象。Evo2能够在不同生物体的基因序列中识别出研究者们需要花费多年时间才能发现的模式,极大提升了疾病相关突变的识别能力,并可以设计出与简单细菌相当的全新基因组。
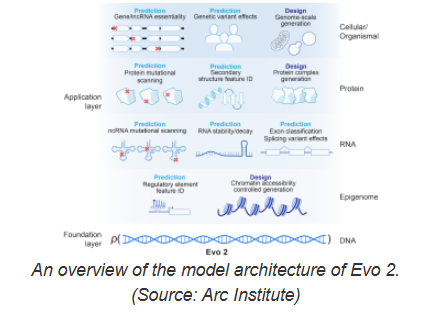
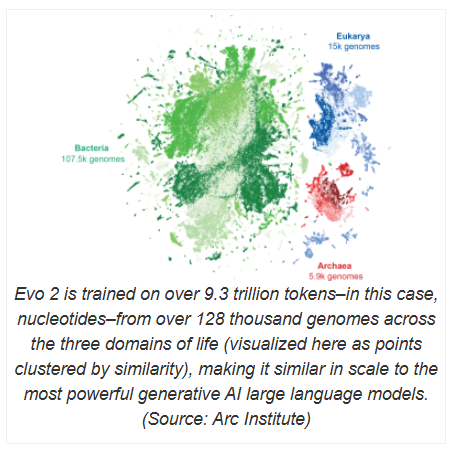
Evo2的训练涉及超过93万亿个核苷酸的处理,远超其前身 Evo1。其开发团队来自 Nvidia 和位于加州帕洛阿尔托的非营利生物医学研究机构 Arc Institute,还与斯坦福大学、加州大学伯克利分校和加州大学旧金山分校的研究人员密切合作。Evo2不仅具备强大的计算能力,还在透明性和可解释性方面做出了积极探索。为了使科学研究更加开放,研究团队还公开了 Evo2的训练数据、代码和模型权重,标志着其成为迄今为止最大规模的完全开源生物 AI 模型。
Patrick Hsu,Arc Institute 的共同创始人及 UC Berkeley 的助理教授表示,Evo2的开发是生成生物学领域的一次重要突破。通过这项技术,机器能够 “阅读”、“写作” 和 “思考” 核苷酸的语言,推动了生物研究的进展。Evo2的训练能力与大规模语言模型相媲美,显示出在预测疾病突变及设计潜在人工生命方面的强大潜力。
此外,Evo2还能够为生物疗法的设计提供新思路,例如针对特定细胞类型激活的基因治疗,以减少副作用并提高治疗精度。Evo2的开发不仅是在技术上的突破,同时也对生物学的理解产生了深远影响。
在研究人员确保模型的负责任开发时,特意排除了会感染人类及其他复杂生物的病原体数据。Nvidia 的数字生物学总监 Anthony Costa 表示,Evo2突破了生物基础模型的局限,为全球科学家提供了强大的合作工具,以应对人类面临的重大健康和疾病挑战。