近日,Vectara 发布了一份名为 “幻觉排行榜” 的报告,比较了不同大型语言模型(LLM)在总结短文档时产生幻觉的表现。这份排行榜利用了 Vectara 的 Hughes 幻觉评估模型(HHEM-2.1),该模型定期更新,旨在评估这些模型在摘要中引入虚假信息的频率。根据最新数据,报告指出了一系列流行模型的幻觉率、事实一致性率、应答率以及平均摘要长度等关键指标。
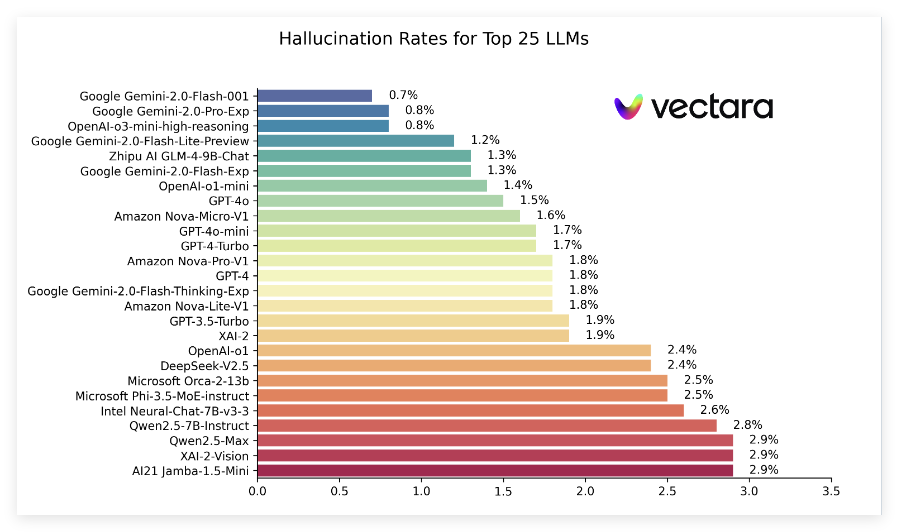
在最新的排行榜中,谷歌的 Gemini2.0系列表现出色,尤其是 Gemini-2.0-Flash-001,以0.7% 的低幻觉率位居榜首,显示出其在处理文档时几乎没有引入虚假信息。此外,Gemini-2.0-Pro-Exp 和 OpenAI 的 o3-mini-high-reasoning 模型分别以0.8% 的幻觉率紧随其后,表现同样不俗。
报告还显示,尽管许多模型的幻觉率有所上升,但大部分仍保持在一个较低的水平,且多模型的事实一致性率均在95% 以上,表明它们在确保信息真实方面的能力相对强劲。特别值得注意的是,模型的应答率普遍较高,绝大多数模型的应答率接近100%,这意味着它们在理解和回应问题时表现出色。
另外,排行榜还提及了不同模型的平均摘要长度,说明模型在信息浓缩方面的能力差异。总体来看,该排行榜不仅为研究者和开发者提供了重要的参考数据,也为普通用户了解当前大型语言模型的表现提供了便利。
具体排名入口:https://github.com/vectara/hallucination-leaderboard
划重点:
🌟最新幻觉排行榜评估了不同大型语言模型在文档摘要中的表现。
🔍 谷歌 Gemini 系列模型表现突出,幻觉率低至0.7%。
📊 模型的应答率接近100%,显示出其在信息处理上的高效性。