LangChain 团队发布 LangMem SDK
今天我们发布了 LangMem SDK,这是一个可帮助你的代理通过长期记忆进行学习和改进的库。
它提供了从对话中提取信息、通过提示更新来优化代理行为,以及维护关于行为、事实和事件的长期记忆的工具。
你可以将其核心 API 与任何存储系统以及任何代理框架一起使用,并且它可以原生集成到 LangGraph 的长期记忆层中。我们还推出了一项托管服务,用于免费提供额外的长期记忆结果——如果有兴趣在生产环境中使用,可以在这里注册。
我们的目标是让任何人都能更轻松地构建随着时间推移更加智能、更加个性化的 AI 体验。这项工作基于我们先前对托管 LangMemalpha 版服务以及 LangGraph 持久化长期记忆层的研究成果。
要安装,请直接运行:
pip install -U langmem
快速链接
- 文档:链接
- 托管服务注册:链接
- 视频教程:基本概念:链接LangMem 中的语义记忆:链接LangMem 中的程序性记忆:链接
关于记忆和自适应代理
代理使用记忆来学习,但它们如何形成、存储、更新和检索记忆会影响你的代理能够学习和掌握的知识或技能类型。在 LangChain,我们发现首先确定你的代理需要学习的能力,将这些需求映射到具体的记忆类型或方法,然后再在代理中实现它们会很有帮助。在添加记忆之前,我们建议你考虑:
- 哪些行为应该通过用户反馈来学习,哪些应该是预先定义好的?
- 需要追踪哪些类型的知识或事实?
- 在什么条件下应该触发对记忆的回溯?
尽管有时它们之间会有一些重叠,但在构建自适应代理时,每种记忆类型都发挥不同的功能:
记忆类型 目的 代理示例 人类示例 常见存储模式
语义记忆
事实与知识
用户偏好;知识三元组
“Python 是一种编程语言”
配置文件或集合
情景记忆
过往经历
Few-shot 示例;对过去对话的总结
“记得我第一天上班的情景”
集合
程序性记忆
系统行为
核心个性和回应模式
“知道如何骑自行车”
提示规则或集合
基于以上问题让我们再来思考:
- 哪些行为应该是可学习的,哪些应该是固定的?代理的一些行为可能需要根据反馈和经验而适应,而另一些行为则应该保持一致。这将指导你是否需要程序性记忆来演进行为模式,或者仅用固定的提示规则就足够了。这在本质上类似于 OpenAI 模型规范中的“指挥链”概念,因为学习到的行为是由用户交互塑造的。
- 需要追踪哪些类型的知识或事实?不同的用例需要持久化不同类型的知识。你可能需要语义记忆来维护关于用户或领域的事实,也可能需要情景记忆来从成功的交互中学习,或者同时需要二者配合使用。
- 在什么条件下应该触发对记忆的回溯?某些记忆(核心的程序性记忆)可能是与数据无关的——它们在提示中始终存在。另一些记忆则依赖数据,可以基于语义相似度来回溯。还有一些记忆会基于应用上下文、相似度、时间等综合判断来回溯。另一个相关问题是记忆隐私。在 LangMem 中,所有记忆都有一个命名空间。最常见的做法是使用 user_id 作为命名空间,以避免用户之间的记忆交叉。通常,可以将记忆限定在特定的应用路由内、用户个人、团队共享,也可让代理在所有用户间学习核心程序。记忆的共享程度既由隐私需求也由性能需求来决定。
所有这些记忆类型都用于超越单次对话的回溯。在一次对话(或线程)内部的短期记忆已经通过 LangGraph 的检查点机制得到相对合理的处理(只要它没有超出模型的有效上下文窗口),这相当于代理的“短期”或“工作”记忆系统。
需要注意的是,这也与标准 RAG 在一些方面有所不同。不同之处在于信息的获取方式:通过交互而不是离线数据摄入;以及所优先存储的信息类型。下面我们将更详细地介绍这些记忆类型。
语义记忆:事实
语义记忆用于存储关键事实(及其关系)以及其他能支撑代理回答的信息。它让你的代理记住模型本身并未预先训练或无法通过网络搜索或通用检索器获取的重要细节。
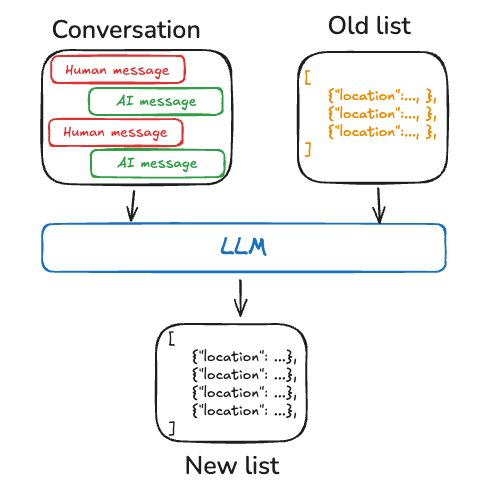 代码示例:
代码示例:
memories = [
ExtractedMemory(
id="27e96a9d-8e53-4031-865e-5ec50c1f7ad5",
content=Memory(
content="Alice manages the ML team and mentors Bob, who is also on the team."
),
),
ExtractedMemory(
id="e2f6b646-cdf1-4be1-bb40-0fd91d25d00f",
content=Memory(
content="Bob now leads the ML team and the NLP project."
),
),
]
在我们的实践中,语义记忆是工程师在寻求为代理添加记忆层时(除了或许是短期“对话历史”记忆之外)最常想要实现的“记忆”形式。
它也(可以说)与传统 RAG 系统有最多的重叠。如果相同的知识可以从其他存储(文档站点、代码库等)检索,并且该存储是权威信息源(而不是仅从交互中获得),那么你的代理也许可以直接在该知识库中检索即可。或者,你也可以周期性地将该知识摄入语义记忆系统。如果这些知识是关于个性化内容(用户信息)或在原始材料中找不到的概念性关系,那么语义记忆就非常适合。
程序性记忆:行为演进
程序性记忆表示如何执行任务的内化知识。它与情景记忆不同,后者关注的是具体经历;而程序性记忆的重点在于通用技能、规则和行为。对于 AI 代理来说,程序性记忆通常保存在模型权重、代理代码以及代理的提示信息之中,这些共同决定了代理的功能。在 LangMem 中,我们主要关注将学到的程序以更新后的代理提示信息的形式加以保存。
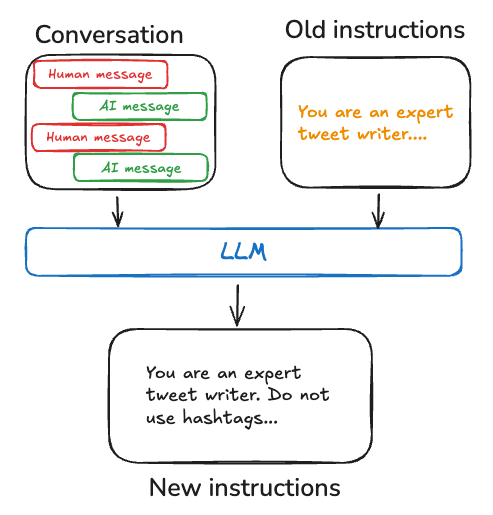 代码示例(提示片段):
代码示例(提示片段):
"""
You are a helpful assistant..
If the user asks about astronomy, explain topics clearly using real-world examples and current scientific data.
Use visual references when helpful and adapt to the user's knowledge level.
Balance practical observational astronomy with theoretical concepts, providing either viewing advice or technical explanations based on user needs.
"""
优化器会根据成功或失败的交互,生成并更新系统提示,从而强化有效的行为。通过这种方式形成反馈循环,使代理的核心指令可以根据性能不断演进。
在我们的提示优化工作中,LangMem 提供了多种生成提示更新建议的算法,包括:
- metaprompt:通过反思和额外的“思考”时间,分析对话并使用元提示(meta-prompt)生成更新建议
- gradient:明确将工作分为独立的批判和提示生成步骤,以进一步简化每一步的任务
- prompt_memory:在单一步骤中同时进行上述工作
情景记忆:事件和经历
情景记忆用于存储过去交互的记忆。它与程序性记忆的区别在于它侧重对具体经历的回溯;与语义记忆的区别在于它记录的是过去事件,而不是一般性知识,回答的是“代理是如何解决特定问题的”而非“问题的答案是什么”。情景记忆通常以 few-shot 示例的形式出现,每个示例都来自对更长原始交互的提炼。LangMem 目前并未对情景记忆提供强 Opinion 的实用工具。
立即体验
查看文档以获取更多关于如何使用 LangMem 实现自定义记忆系统的示例,包括以下指南:
- 创建能主动管理自身记忆的代理
- 在代理之间共享记忆
- 使用命名空间将记忆按用户或团队进行组织
- 在你的自定义框架中集成 LangMem
如果你的团队希望在代理中添加个性化或持续学习功能,请填写我们的意向表。
加入我们
我们正在招募工程师来构建全球最出色的自适应代理运行时。如果你对与我们一起设计和构建这些技术感兴趣,请查看我们开放的职位。