OpenAI 论文:使用大型推理模型进行竞技编程
摘要 我们发现,将强化学习应用于大型语言模型(LLM)能够显著提升在复杂编程和推理任务上的表现。此外,我们比较了两种通用的推理模型——OpenAI 的 o1 和一个早期版本的 o3——与一种面向特定领域的系统 o1-ioi。o1-ioi 采用了人工设计的推理策略,旨在参加 2024 年国际信息学奥林匹克竞赛(IOI)。我们使用 o1-ioi 在 IOI 2024 的现场比赛中参赛,并结合手动调试的测试时策略,获得了第 49 百分位的成绩;在放宽比赛限制后,o1-ioi 达到了金牌水平。然而,当我们评估后续版本如 o3 时发现,o3 在无需人工编写的特定领域策略或放宽限制的情况下,也能获得金牌。我们的研究表明,尽管 o1-ioi 这类专门管线能带来显著性能增益,但规模更大的通用模型 o3 无需依赖人工设计的推理启发式即可超越这些结果。值得注意的是,o3 在 2024 IOI 上取得了金牌,并在 CodeForces 上的水平可与顶尖人类选手媲美。整体而言,这些结果说明,与其依赖特定领域的技巧,不如通过扩大通用强化学习规模的方式,为在需要推理能力的领域(如竞技编程)实现最先进的 AI 提供了更稳健的路径。
1 引言
竞技编程被广泛认为是衡量推理和编程熟练度的高难度基准 [2]. 要解决复杂的算法问题,需要高级的计算思维和问题解决能力。此外,这类问题可进行客观评分,使其成为评估 AI 系统推理能力的理想测试平台。
近期在大型语言模型的程序合成方面已有研究 [1] 表明,即便是从 2.44 亿到 1,370 亿参数规模的相对通用模型,也能根据自然语言指令生成简短的 Python 脚本。值得注意的是,模型规模的增大会带来对数线性地性能提升,而微调则能显著提升准确率。同时,Codex [2](一种早期的面向代码的 LLM)在 Python 程序生成方面表现出色,并为 GitHub Copilot 提供了支持。接下来,AlphaCode [7] 通过大规模的生成和推理时启发式方法,成功地解决了竞技编程任务;之后的 AlphaCode2 [6] 进一步提升了 AlphaCode 的解题数量近乎一倍,在 CodeForces 平台达到了第 85 个百分位的成绩。两代 AlphaCode 系统在推理时都采用了大规模抽样策略:每道题最多生成多达一百万个候选解,然后选取最优的 10 个提交,这一过程依赖手工设计的测试时策略。
自那以后,利用强化学习提升 LLM 推理能力的研究取得了重大进展。由此催生了所谓的“大型推理模型”(LRM):通过强化学习训练的语言模型,能“思考”并进行扩展的推理链。尤其是 OpenAI 的 o1 [4,12] 以及即将发布的继任者 o3 [13],都利用“链式思考”来处理复杂的数学和编程任务。DeepSeek-R1 [3] 和 Kimi k1.5 [15] 的研究也分别表明,学习到的链式思考可以在数学和编程难题上提升性能。
仍待探索的问题是:人工设计的、面向特定领域的推理策略,与模型自主生成并执行的策略相比,究竟孰优孰劣?我们手头有三个可帮助回答该问题的系统:o1、o1-ioi,以及 o3 的早期版本。OpenAI 的 o1 是首个大型推理模型,利用通用方法提升编程表现;在此基础上,o1-ioi 是一个为 2024 年国际信息学奥林匹克竞赛(IOI)而专门微调的系统,并在推理时采用了与 AlphaCode 类似的策略,因而在 2024 IOI 和 CodeForces 等平台上都取得了显著的性能提升。随后,o3 的出现进一步提升了 AI 模型的推理能力,与 o1-ioi 或 AlphaCode 不同的是,o3 并不依赖人工定义的面向编程的推理策略;我们发现,通过端到端的强化学习,o3 在推理时自然涌现出了复杂的策略,令其在各类竞技编程基准上取得了前所未有的表现。
本报告首先概述了推理在编程任务(如竞技编程)中的重要性,接着回顾了 OpenAI 系列大型推理模型在编程能力方面的进展,并介绍了我们在多种竞技编程和代码基准上的评测方法和结果。
2 OpenAI o1
我们首先介绍 OpenAI o1,这是一种使用强化学习训练的大型语言模型,旨在应对复杂推理任务。在回答问题之前生成一条扩展的内部“思考链”(chain of thought)[16],让 o1 可以像人类一样系统性地逐步解决复杂问题。强化学习用于优化这种链式思考过程,帮助模型识别并纠正错误,将复杂任务分解成可管理的子问题,并在方法失败时探索替代的解决路径。通过在上下文中执行推理,这些机制大幅提升了 o1 在广泛任务上的整体表现。
此外,OpenAI o1 还被训练使用外部工具 [14],尤其在安全环境中编写并执行代码。^1 这一能力让 o1 可以检查生成的代码能否编译、是否通过给定的测试用例,以及是否符合其他正确性标准。通过在一次采样过程中测试并修正输出,o1 得以迭代式地改进解答。
- 译者注:原文脚注“especially for writing and executing code in a secure environment.1 This capability…”已在此合并表述。
2.1 CodeForces 基准
CodeForces 是一个举办在线竞赛的编程网站,面向全球顶尖的竞技编程选手。在此平台上模拟真实竞赛,有助于评估模型的竞技编程能力。我们的评测涵盖了 2023 年 12 月和 2024 年的 CodeForces Division 1 比赛,并确保这些竞赛都在预训练和强化学习的时间截止点之后。此外,我们也使用了 OpenAI 的嵌入 API 检查,确认测试题目并未在训练阶段出现。
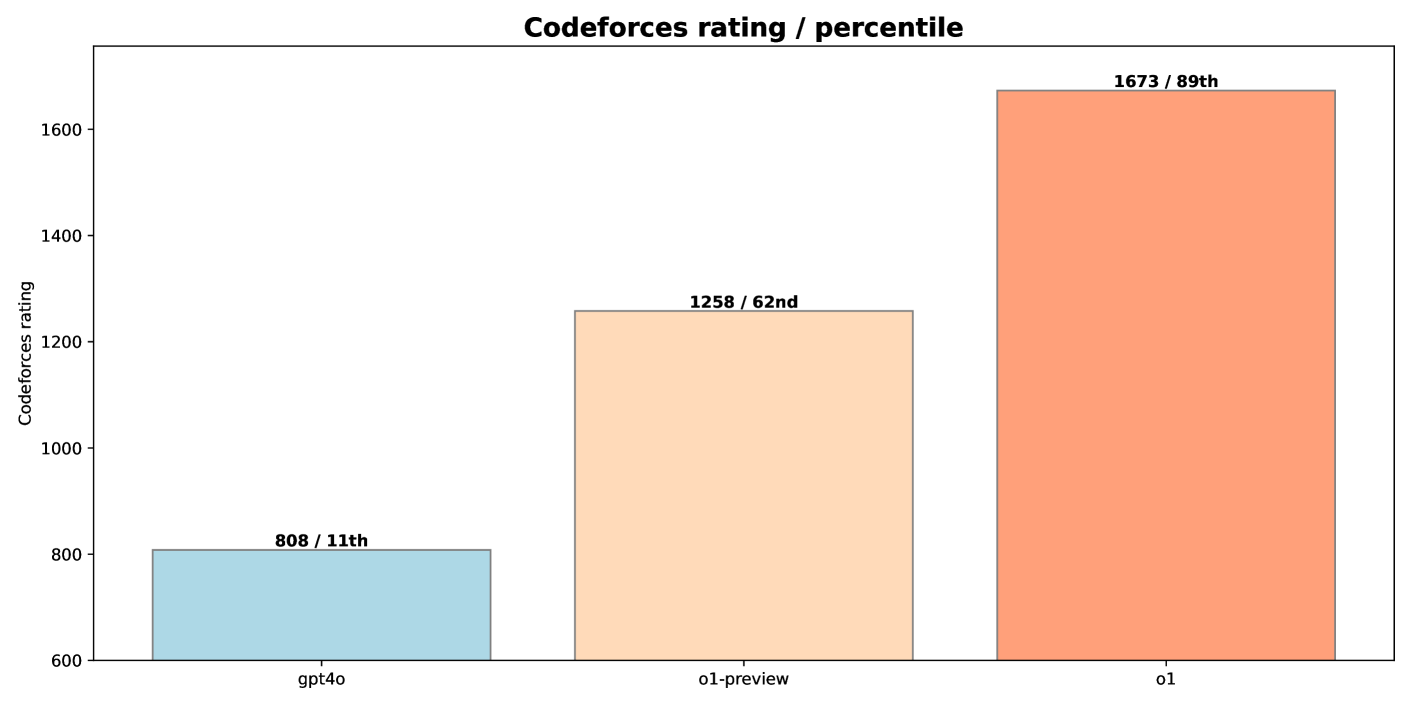 图 1:在 CodeForces 上比较推理型 LLM(OpenAI o1-preview 和 o1)与非推理型 LLM(gpt-4o)。
图 1:在 CodeForces 上比较推理型 LLM(OpenAI o1-preview 和 o1)与非推理型 LLM(gpt-4o)。
我们将 o1 与一个无推理的 LLM(gpt-4o)以及一个早期的推理模型(o1-preview)进行了对比。由图1可见,o1-preview 和 o1 相比 gpt-4o 在 CodeForces 上都有显著性能提升,这突出了强化学习在复杂推理方面的有效性。o1-preview 获得了 1258 的 CodeForces 评分(第 62 百分位),而 gpt-4o 为 808(第 11 百分位);经过更多训练的 o1 则达到 1673(第 89 百分位),创造了 AI 在竞技编程上的新里程碑。
附录B中提供了我们模型可解题目的更多细节及评分的计算方法。
3 OpenAI o1-ioi
在开发和评测 OpenAI o1 的过程中,我们发现,无论是在强化学习训练上投入更多算力,还是在推理时投入更多算力,都能持续提升模型性能。
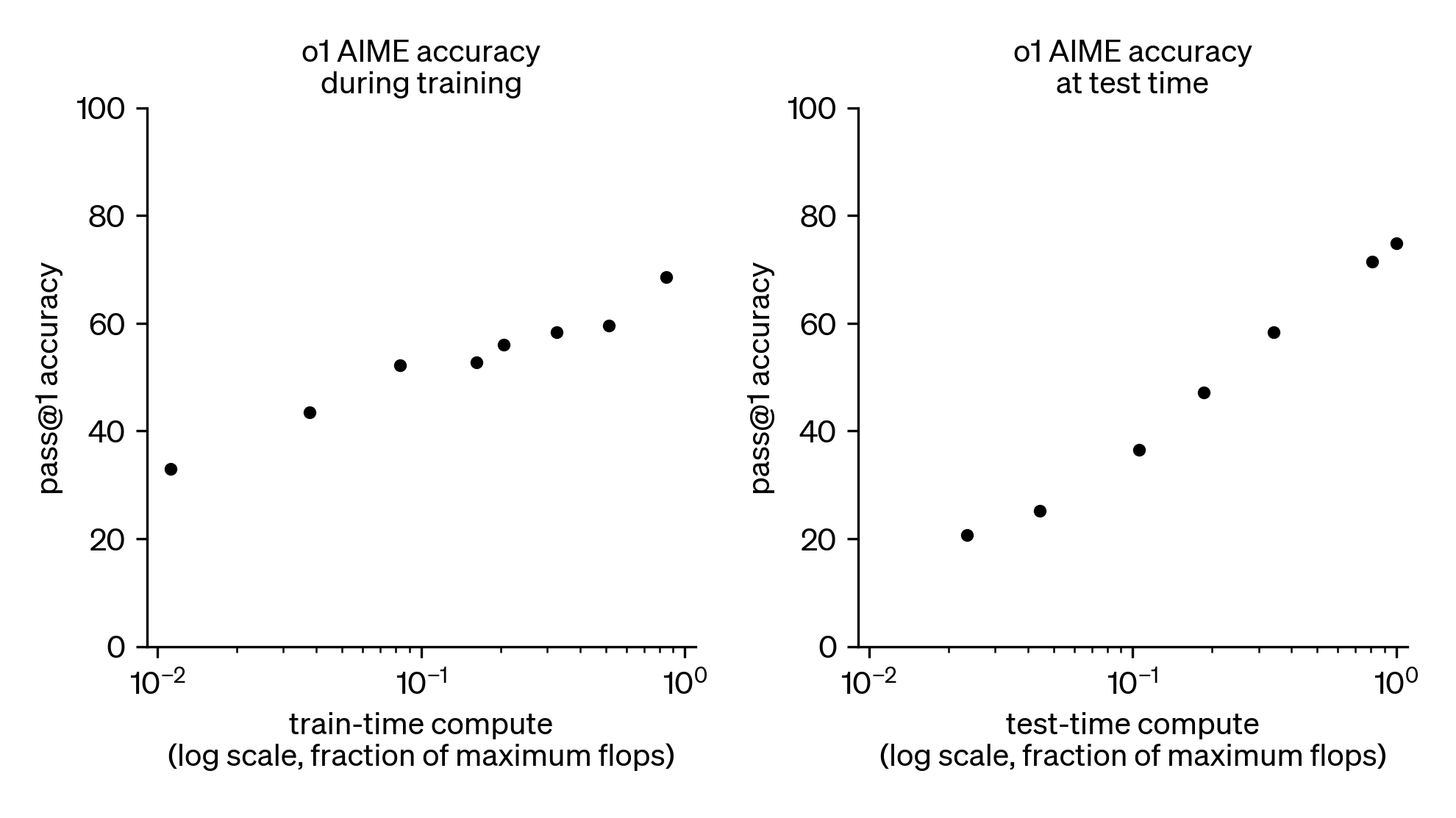 图 2:额外的强化学习训练以及更多推理时算力可提高在“竞技数学”任务上的表现。
图 2:额外的强化学习训练以及更多推理时算力可提高在“竞技数学”任务上的表现。
如图2所示,扩大强化学习阶段的训练规模并延长测试时推理流程,都能带来明显增益,显示出在常规的 LLM 预训练之外,优化这两个算力维度对于继续提升性能至关重要。
基于此,我们构建了o1-ioi系统,用于参加 2024 年的国际信息学奥林匹克竞赛(IOI)。在 o1 的基础上持续针对编程任务进行强化学习训练,同时加入了面向竞赛的专业化测试时推理策略。
3.1 编程方向的强化学习微调
首先,我们在 OpenAI o1 检查点的基础上继续进行强化学习训练,重点关注编程任务,通过投入更多的训练计算量来强化模型规划、实现和调试复杂解法的能力。具体做法包括:
- 从 OpenAI o1 的模型权重继续强化学习训练。
- 着重加入高难度编程题,强化模型在 C++ 生成和运行时检查方面的能力。
- 进一步引导模型输出符合 IOI 提交格式的结果。
这种对于编程的专门强化,使得 o1-ioi 能在推理阶段编写和执行 C++ 代码。通过迭代运行并改进解法,模型的编程和问题解决能力得以双重强化。
3.2 o1-ioi 的测试时策略
简而言之,我们将每道 IOI 题目拆分为若干子任务(subtask),对每个子任务生成 10,000 个解法,然后使用基于聚类和重排序的方案,从这些候选中选出要提交的解。
问题拆分 在 IOI 中,评分是按照子任务进行的;每位选手在每个子任务上可得到的分数是他们对该子任务所有提交的最高得分。基于此,我们将每道 IOI 题目按照评分指引拆分为多个子任务,并为每个子任务生成独立的文档(只保留对应子任务的信息,去除其他子任务的描述)。
聚类 我们基于模型自动生成的测试用例输出,对生成的解法进行聚类。对每个子任务,首先提示模型根据题目描述编写 C随机测试数据生成器,再通过这些生成器生成 256 个随机测试输入;随后提示模型编写 C校验程序(validator)来检查这些随机输入是否符合子任务的约束;最终,我们选取通过至少 75% 校验器的测试输入作为有效测试用例。对每个子任务,我们共生成 256 个这样的随机输入,并根据解法在这些测试输入上的输出将其进行聚类:只要在全部测试输入上的输出一致,就将这些解法归于同一聚类。
重排序 随后,我们执行核心的重排序步骤:对每个解法打分,分数由以下几个部分组成:
- 模型学习到的评分函数衡量的解法质量;
- 在模型生成的测试输入上的错误数;
- 在公开测试用例上的失败情况。
每个聚类的得分为其中解法的平均得分减去提交次数的惩罚。惩罚权重在过去 IOI 题目的模拟上通过随机搜索方式调优,并在提交过程中采用轮流提交的方式进行模拟。
提交 我们会针对各子任务提交最多 50 次(与人类选手相同),在各子任务之间按难度从高到低的顺序轮转提交,每次从得分最高的聚类中选取得分最高的解法。当某个子任务被成功解出(达到该子任务满分)时,就停止对该子任务的进一步采样。若要提交的子任务是已解子任务的超集,我们会过滤掉在已解子任务的测试输入上输出不一致的解法,从而快速缩小更高难度子任务的候选提交范围。
3.3 CodeForces 基准
我们再次在 CodeForces 环境下评测 o1-ioi 的编程能力,模拟真实竞赛时的完整测试用例,以及时间、内存限制等。
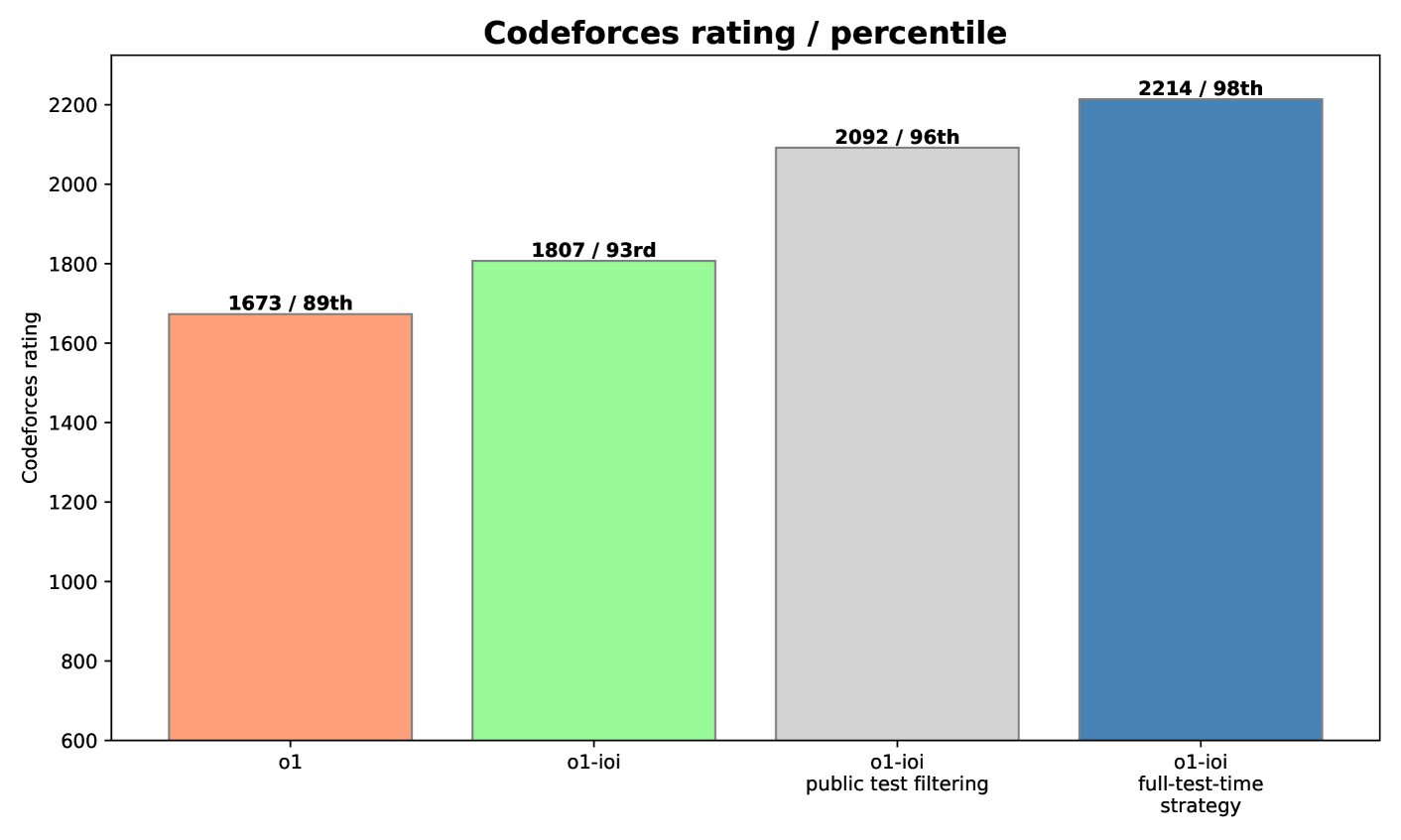 图 3:继续对 OpenAI o1 进行编程任务强化学习,并加入测试时策略,能显著提升性能。
图 3:继续对 OpenAI o1 进行编程任务强化学习,并加入测试时策略,能显著提升性能。
如图3所示,o1-ioi 在 CodeForces 上的评分达到 1807(超越 93% 的选手),可见针对编程的额外强化学习确实带来了显著的性能提升。当我们增加一个简单的筛选策略(过滤掉无法通过公开测试的解法),评分提升至 2092(第 96 百分位);而采用完整测试时策略后,评分进一步提升到 2214(第 98 百分位)。这些结果说明,面向特定领域的强化学习微调与高级解法筛选启发式的结合,能够显著提升在竞技编程中的表现。
3.4 IOI 2024 现场比赛
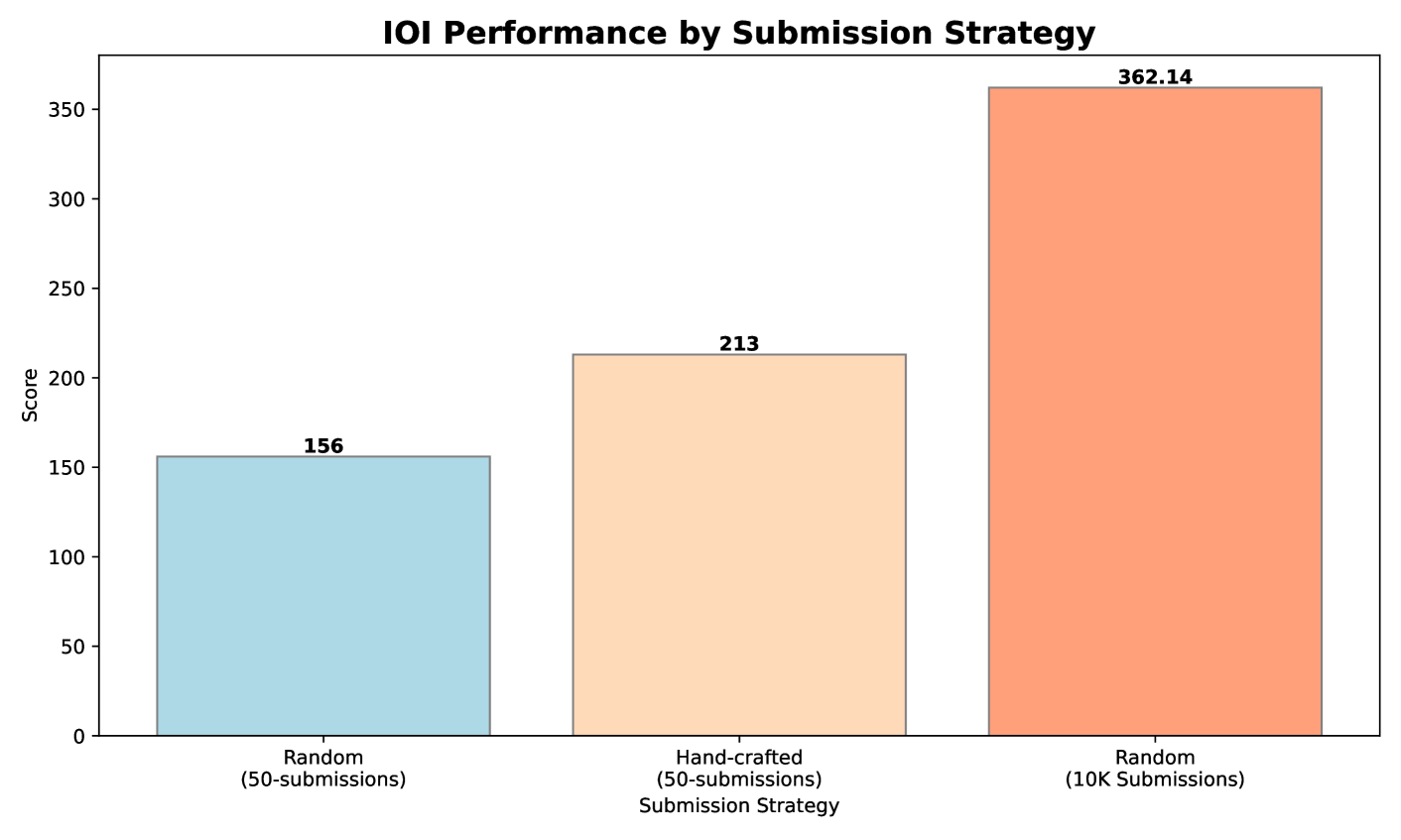 图 4:o1-ioi 在 IOI 2024 比赛中的表现。
图 4:o1-ioi 在 IOI 2024 比赛中的表现。
o1-ioi 系统以与人类选手相同的条件参加了 2024 年国际信息学奥林匹克竞赛(IOI)。比赛中有 6 道高难度算法题,选手有 10 小时的解题时间,每道题最多可提交 50 次。图4展示了结果。
比赛期间,我们为每个题目生成了 10,000 个候选解,并通过测试时的选择策略挑选出 50 个方案进行提交。此策略综合考虑了公开测试用例、模型自动生成的测试用例以及一个学习到的评分函数。最终,模型得到了 213 分,在全部选手中位列第 49 百分位。
相比之下,如果随机选择 50 个提交,平均只能获得 156 分,说明我们所采用的解法选择策略在受到比赛限制的情况下额外贡献了近 60 分。
若将每题允许的提交次数放宽到 10,000 次,则 o1-ioi 的分数可大幅提升至 362.14 分,超过了金牌线。这表明在策略不变但提交量不受限的情况下,模型能展现出强大的潜力。我们在附录C中展示了部分取得 362.14 分的提交样例。
4 OpenAI o3
在总结 o1 和 o1-ioi 的经验后,我们希望探索仅依赖强化学习训练、而无需人类手动设计推理策略时,模型可达成的极限表现。虽然 o1-ioi 通过额外的编程方向强化学习和精心设计的测试时流程获得了优异成绩,但这些成果很大程度上依赖人类专家对测试时的干预。我们想进一步探究:若给模型充足的强化学习训练量,使之自主学会并执行推理过程,性能会如何?为此,我们使用了 o3 [13] 的早期版本,在竞技编程任务上进行了评估。
4.1 CodeForces 基准
我们在 CodeForces 的测试集上评估了一个早期的 o3 检查点,每道题目的提示包括题目描述、约束以及可用的示例测试。
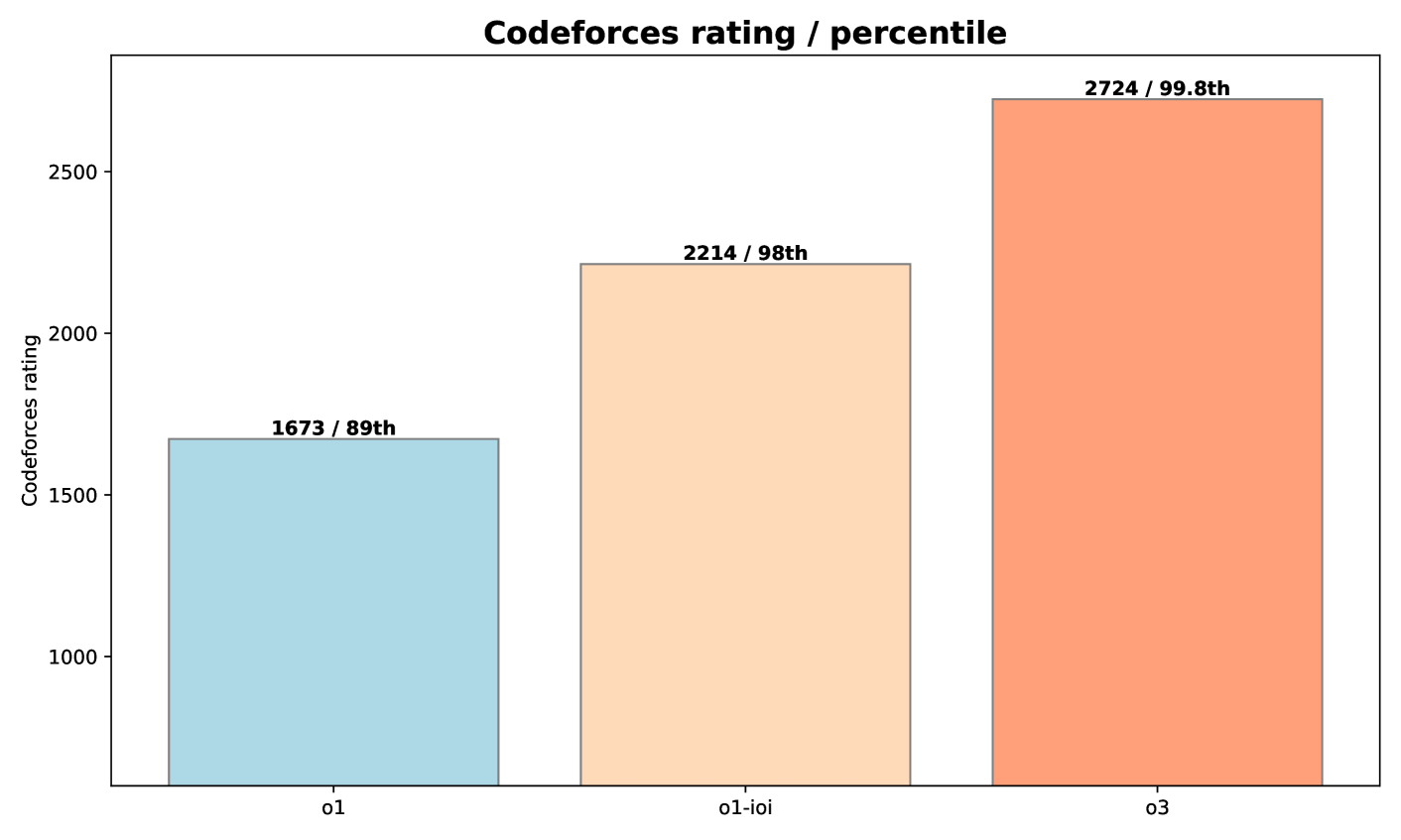 图 5:OpenAI o3 在 CodeForces 测试集上的表现。
图 5:OpenAI o3 在 CodeForces 测试集上的表现。
由图5可见,相较于 o1 以及包含了手动策略的完整 o1-ioi,进一步的强化学习让 o3 的性能大大提升。o1-ioi 的评分为 2214(第 98 百分位),而 o3 则跃升到 2724(第 99.8 百分位),在竞技编程上取得了重大突破。这表明 o3 能以更高的可靠度解决更多种类的复杂算法问题,其能力已接近 CodeForces 上的顶尖人类选手。
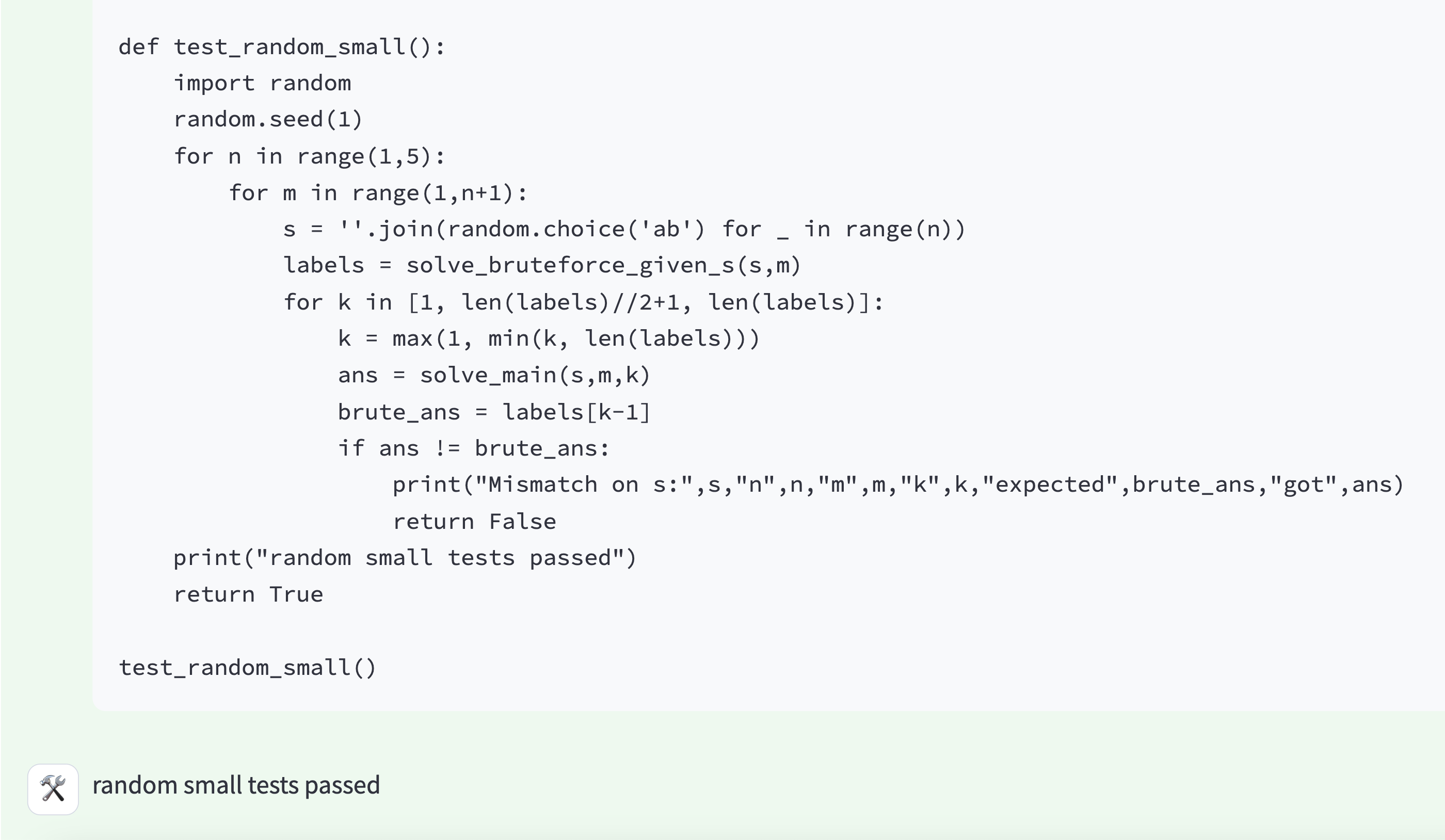 图 6:o3 对自身解法进行测试的示例。可以看出,o3 在推理时部分复现了 o1-ioi 在 IOI 2024 所采用的手工测试策略。
图 6:o3 对自身解法进行测试的示例。可以看出,o3 在推理时部分复现了 o1-ioi 在 IOI 2024 所采用的手工测试策略。
除了解题能力显著增强之外,我们还观察到 o3 的链式思考更加深入和周到。模型不仅会编写并执行代码来验证其解法是否通过公开测试用例,还会根据验证结果进行改进。图6中展示了一个高级的推理时策略:对于无法简单验证的题目,o3 往往会先写一个尽管效率较低但正确性较高的暴力解,再与更优化的算法输出进行对比;通过这种自我验证,o3 可以及时发现并纠正错误,从而提高解法的可靠性。
4.2 IOI 2024 测试
虽然我们在 IOI 2024 的现场比赛中使用的是 o1-ioi,但事后我们也用相同的 6 道 IOI 2024 题目对一个 o3 检查点进行了离线评估,并且严格遵守官方的 IOI 规则(每题最多提交 50 次)。值得注意的是,这个用于 IOI 2024 评测的 o3 版本比之前用于 CodeForces 评测的早期版本更新一些,并且包含了更多的新训练数据。IOI 2024 的题目在该模型的训练截止日期之后,我们也再次确认题目未出现在训练集中。
采样方法 与 o1-ioi 不同,o3 并没有对每个子任务单独采样,而是直接对包含完整题目描述的单个提示进行采样。此外,o1-ioi 是对每个子任务各生成 10,000 个解,而我们对 o3 则只对每个题目生成 1,000 个解。
两者的解法筛选策略也存在差异:o1-ioi 依赖复杂的人工手动设计流程(见3.2),而 o3 仅采用了非常简化的方法:我们在每道题抽样的 1,024 个解法中选择“推理时消耗计算量最高”的前 50 个进行提交。尽管方法简化,o3 在不需要额外人工对子任务做划分、也不需要各种聚类或复杂提交策略的情况下,仍能可靠地覆盖大部分甚至全部子任务。
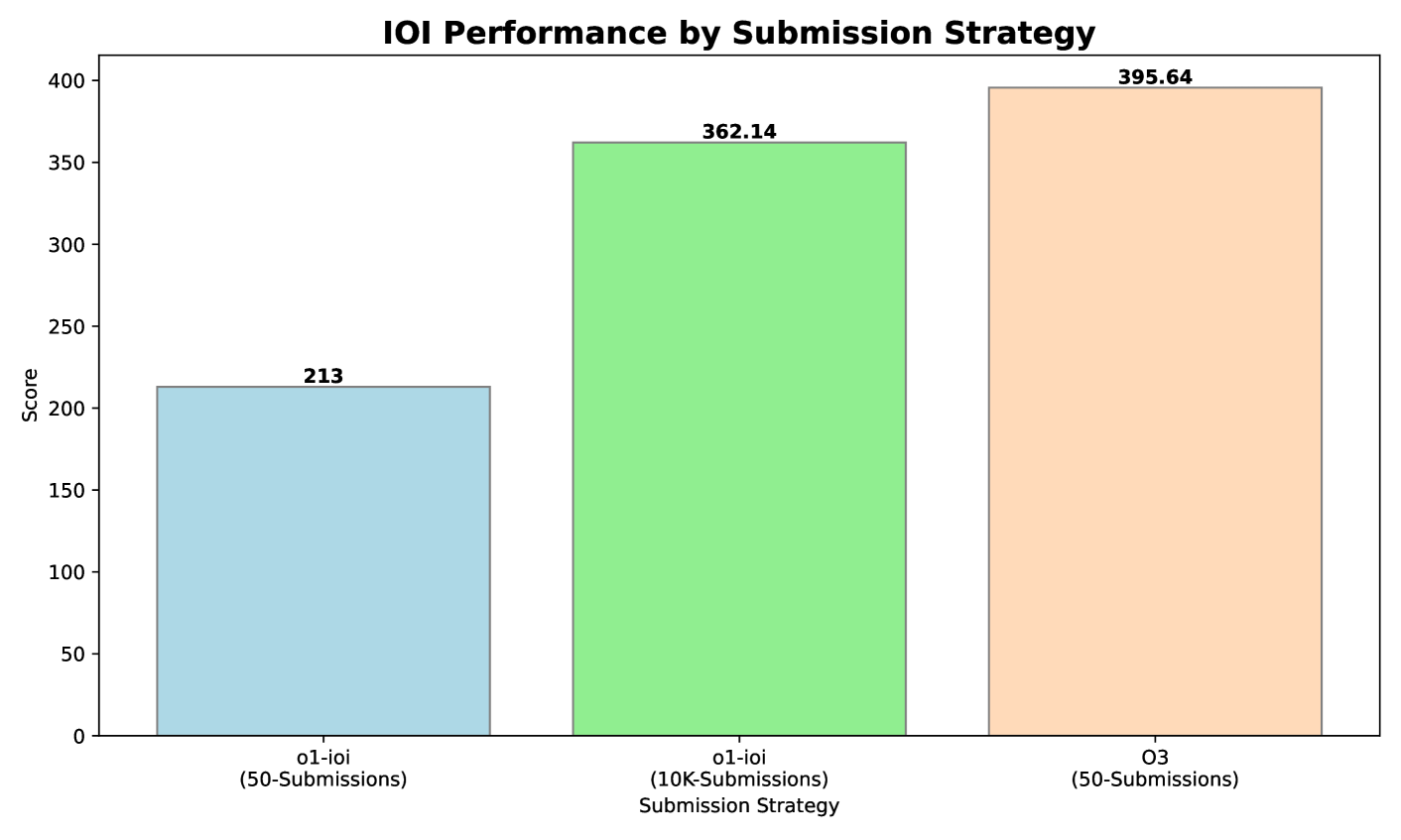 图 7:2024 IOI 不同提交策略对应的得分。即使不采用人工启发式或放宽提交上限,o3 只用 50 次提交就超过了金牌分数线,并且超越了 o1-ioi 的表现。
图 7:2024 IOI 不同提交策略对应的得分。即使不采用人工启发式或放宽提交上限,o3 只用 50 次提交就超过了金牌分数线,并且超越了 o1-ioi 的表现。
结果 图7给出了最终分数。IOI 使用子任务计分,总分为 600 分(2024 年竞赛设置),其中金牌的分数线约在 360 分左右。关键结果包括:
- o1-ioi 在 50 次提交限制下得到 213 分,若将提交限制放宽到 10,000 次,可升至 362.14 分,刚好越过金牌线。
- o3 则在 50 次提交限制下即取得 395.64 分,超过了金牌线。
这说明 o3 无需面向 IOI 的手工推理策略,也能超越 o1-ioi 的表现。在 o3 的强化学习训练中,自发涌现的高级推理时策略(例如通过编写暴力解自检)已足够全面,无需再依赖人类预先编排的聚类与筛选管线。
总体而言,IOI 2024 的结果表明,仅通过大规模强化学习的训练即可获得最先进的编程与推理性能。o3 能够自主学会生成、评估并改进解法,并最终在没有任何手工启发或聚类方法的情况下,超越了 o1-ioi。
5 软件工程领域的评测
我们已经展示了推理对竞技编程性能的重大提升,而解决复杂算法挑战正是竞技编程的特征。然而,我们也想确认,推理能否在更贴近实际需求的编程场景中发挥同样的作用。为此,我们在 HackerRank Astra2 数据集和 SWE-bench verified3 [5,11] 这两个数据集上进行了测试。
5.1 HackerRank Astra
HackerRank Astra 数据集由 65 个项目式编程挑战组成,涵盖 React.js、Django、Node.js 等多种框架,旨在模拟真实的软件开发场景,考察在多文件、长上下文等场景中解决问题的能力。与传统的竞技编程数据集不同,HackerRank Astra 不提供公开测试用例,因而无法依赖手动设计的推理时策略。对该数据集的评测可以帮助我们判断,推理带来的性能提升,是否仅在算法性质较强的任务中有效,还是也能拓展到更具工业应用背景的任务中。
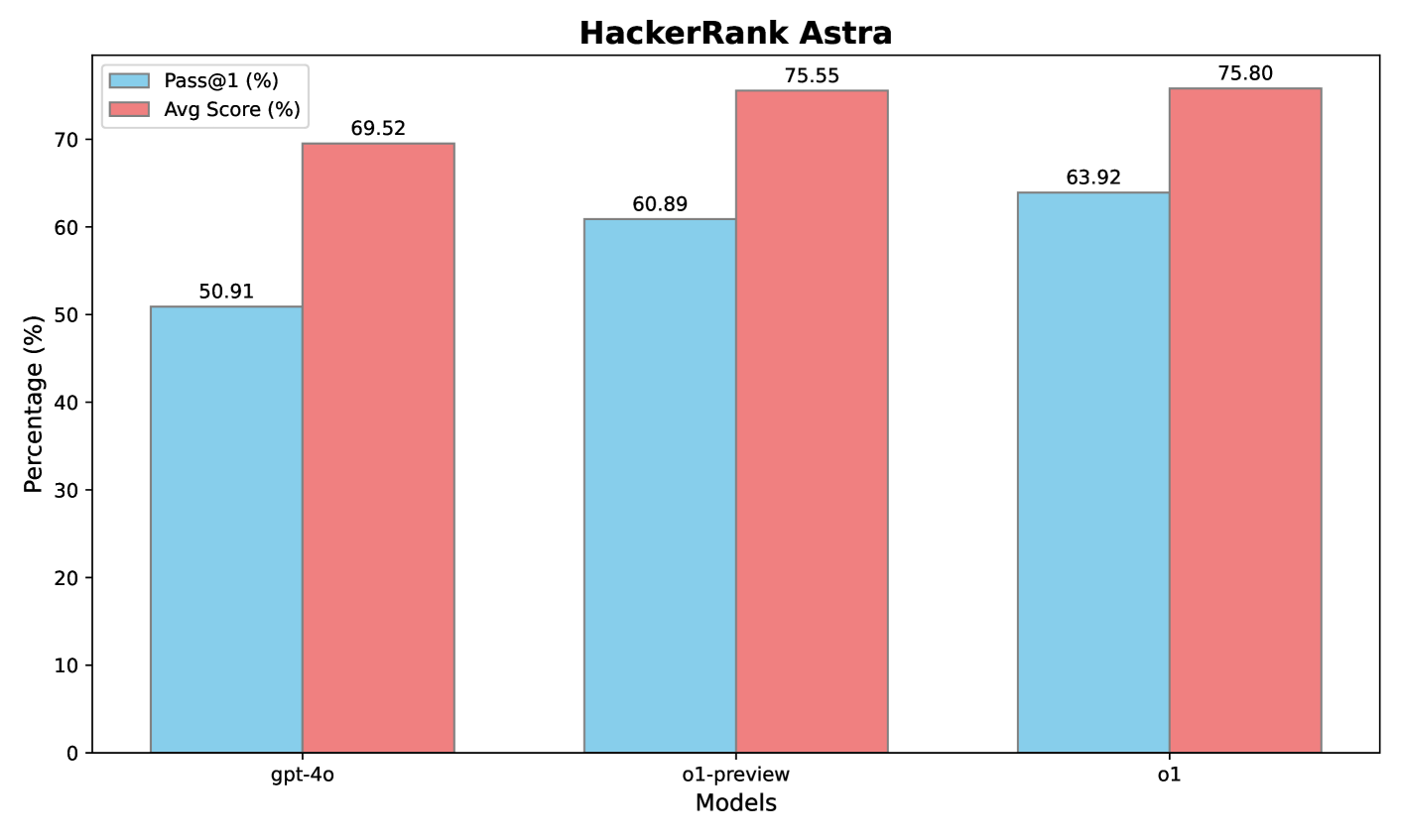 图 8:HackerRank Astra 的评测结果。
图 8:HackerRank Astra 的评测结果。
图8展示了 pass@1(第一次尝试就成功的概率)和平均分(通过的测试用例占比)等指标。结果显示,o1-preview 相比 GPT-4o 在 pass@1 上提升了 9.98%,在平均得分上提升了 6.03%,体现了链式思考对于此类真实开发任务的助益。进一步的强化学习微调让 o1 在 pass@1 达到 63.92%、平均得分 75.80%,比 o1-preview 再提升了 3.03% 的 pass@1。可见 o1 具备更强的推理和适配能力,在与工业应用更贴近的软开任务上也能取得良好效果。
5.2 SWE-Bench Verified
SWE-bench Verified 是 OpenAI 的“准备度”团队对 SWE-bench 中部分任务进行人工校验后得到的子集,能更可靠地评估 AI 模型在解决实际软件问题时的水平。该子集含有 500 个任务,修正了 SWE-bench 中一些常见问题(如正确解被判为错误、题目描述不完整或单元测试过度指定等),使得评分更加可信。
为展示在此软件任务上的表现,我们引用了 o1 system card [4] 中的结果以及对一个早期 o3 检查点 [13] 的结果。由于 o1-preview 没有使用代码执行或文件编辑工具的能力,当时我们采用了最佳可用的开源“无代理(Agentless)”方案来进行评测。与 IOI 不同,在 SWE-Bench Verified 上我们没有使用专业化的测试时策略。所有模型在每个任务上均可尝试 5 次,若 5 次均失败,则视为错误;评测会在 3 轮试验的平均基础上得到最终分数。对于系统故障(例如容器崩溃或评分失败),我们会重试,直到得到有效结果为止。
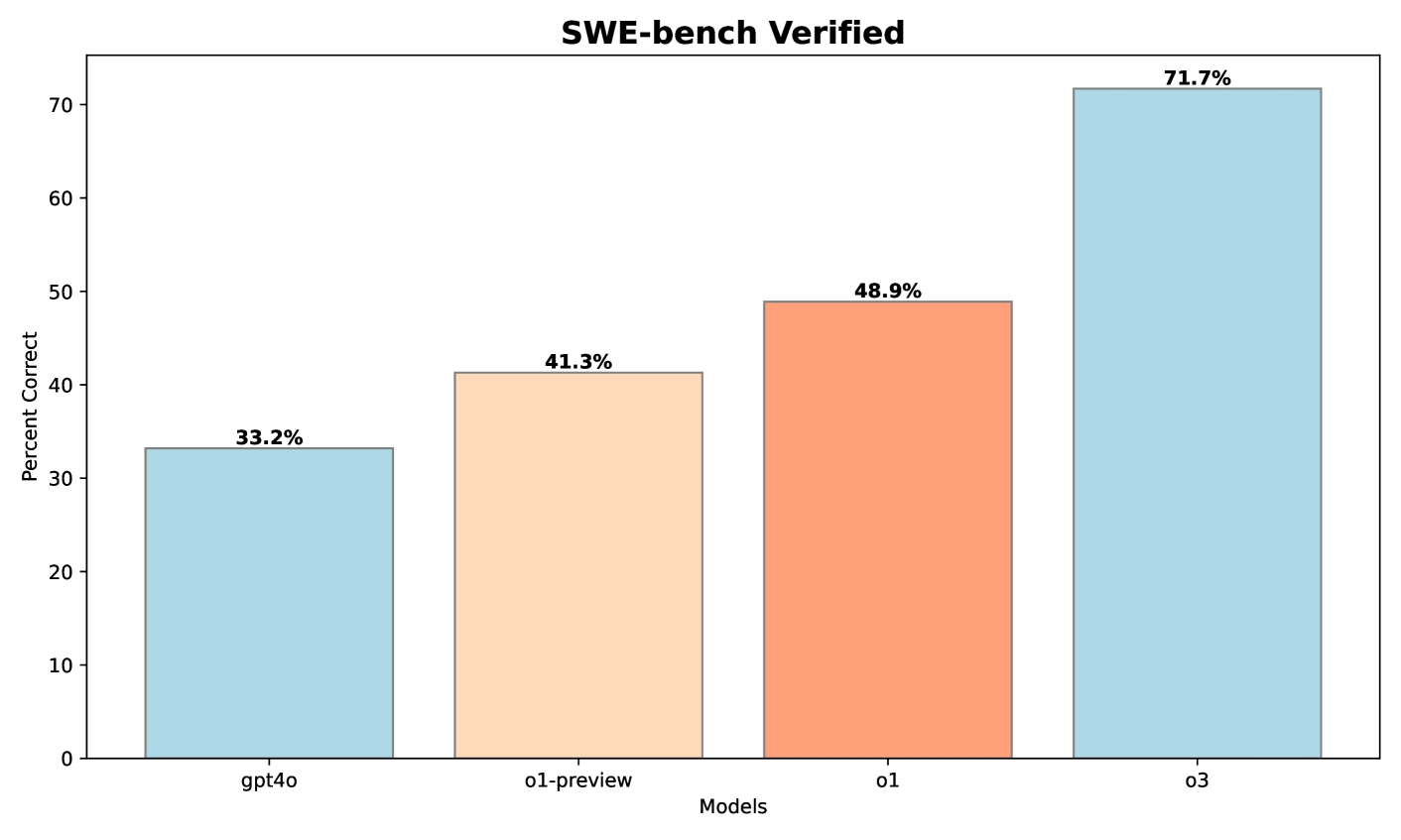 图 9:SWE-bench 评测结果。
图 9:SWE-bench 评测结果。
如图9所示,相比 gpt-4o,o1-preview 在 SWE-bench 上提升了 8.1%,再次证明了其推理能力的增强;在进一步强化学习训练后,o1 相比 o1-preview 又提升了 8.6%。值得一提的是,使用比 o1 更大规模的强化学习训练资源后,o3 又在 o1 的基础上提升了 22.8%。这些结果表明,推理能力的增强不只对竞技编程有效,也适用于更多面向真实世界的软件工程任务。
6 结论
通过 o 系列大型推理模型,我们证明了链式思考(chain-of-thought)对于编程任务(无论是 CodeForces、IOI 等竞技编程,还是更贴近产业需求的 SWE-bench、Astra)都能显著提升性能。我们的研究显示:只要不断增加强化学习的训练算力,并在推理时适度增加算力,模型的性能就能持续提升,最终可接近世界级人类高手的水平。基于这些结果,我们相信,o 系列大型推理模型将在科学、编程、数学等众多领域激发更多新应用。
附录 A 作者、署名归属与致谢
数据准备 (Data Preparation)Borys Minaev, Ignasi Clavera, Lorenz Kuhn, Nat McAleese, Oleg Mürk, Szymon Sidor
IOI 模型训练 (IOI Model Training)Ahmed El-Kishky, Mostafa Rohaninejad
采样基础设施 (Sampling Infrastructure)Andre Saraiva, Hunter Lightman, Vineet Kosaraju, Wenda Zhou
测试时策略 (Test-time Strategy)Alexander Wei, Daniel Selsam, David Dohan, Francis Song, Ignasi Clavera, Max Schwarzer, Rhythm Garg, Rui Shu
评测 (Evaluation)Andre Saraiva, Ignasi Clavera, Lorenz Kuhn, Nat McAleese
领导 (Leadership)Jakub Pachocki, Jerry Tworek, Lukasz Kaiser, Mark Chen
o3 模型开发 (o3 Model Development)o3 contributors [13].
致谢 (Acknowledgments)我们感谢 IOI 组委会允许我们使用模型 o1-ioi 参加 2024 国际信息学奥林匹克竞赛。也感谢 IOI 技术委员会成员 Wael Ewida 搭建了一个平台,使我们能在与选手相同的条件下提交解法。此外,我们要感谢为我们的沙盒环境提供支持的团队成员:Taylor Gordon, Oleg Boiko, John Rizzo, Paul Ashbourne, Leo Liu, Alexander Prokofiev, 以及 Scottie Yan;感谢 Chris Orsinger 和 Michelle Fradin 对数据工作的贡献。最后,我们对所有参与 o1 与 o3 强化学习推理研究的同事表示由衷感谢,你们的辛勤与专业为本研究的推进奠定了基础。
附录 B CodeForces 相关细节
为将我们的模型与人类选手进行对比,我们模拟了完整的编程竞赛环境。本附录介绍如何进行模拟、计算得分和评分,以及每场比赛的详细表现。
B.1 数据
测试集中包含了 2023 年末和 2024 年的 “Division 1” 竞赛,它们的时间均在 o3 的训练数据截止点之后。我们另外通过向量检索方式确认这些测试题目不在模型的训练集中。因其中一场比赛包含了交互式题目,评分较为繁琐,所以被排除在外;除此之外,我们纳入了截止评估时可获取的所有 Division 1 赛题。在训练过程中,我们主要使用“Division 2”的题目作为验证集;当验证集结果显示性能足够强时,才对所选的 Division 1 题目进行了正式测评。
B.2 评分
我们会对每道题目运行完整测试,并确保测试环境与 CodeForces 官方评测环境高度一致,亦包括手动向 CodeForces 官方环境提交解答以验证两者一致性。参考 AlphaCode [6] 的方法,我们允许模型对每道题有最多 10 次独立的提交机会,若其中任意一次全部通过测试,即视为通过。与人类在正式比赛中的流程略有差异(人类只能即时知道预测试结果),但对于 Division 1 题目来说,预测试通常较全面,与最终测试的相关度很高;而我们的结果也显示,实际需要的失败次数非常少(见表格 LABEL:tab)。我们并未获得哪些测试用例是预测试用例的具体信息。
B.3 “思考时间”
在人类参赛时,得分会随着提交速度的提升而提高,而模型可以并行思考和同时解决所有题目,天然地获得一定优势。为了减小这种优势,我们在主要结果中采用了这样的方法:如果 o3 通过了某道题,则将其在该题的得分视为“与在比赛中用相同失败次数通过该题的人类选手的得分中位数”一致。
我们也可将模型的实际思考时间纳入评分:在最大并行的假设下,模型对各提交进行排序所需的总时间是各次推理耗时的最大值。但由于模型在生成和筛选解法时的推理可完美并行,如果真要计算,实际上会得到比我们报告的更高的估计评分。然而,从历史上看,随着语言模型规模不断变大,推理时计算量早已显著增加;在实践中,o3 依旧能相当快速地提交,并行程度越高,提交速度越快。
B.4 估计评分
CodeForces 的积分系统由其作者在三篇博客 [8,9,10] 中进行了说明。它与 Elo 体系相似,若选手 A 的评分为 (RA),选手 B 的评分为 (RB),则 A 在比赛最终排名中超越 B 的概率估计为 [ \frac{1}{1 + 10^{\frac{RB - RA}{400}}} ] 为了得到模型的评分,我们首先计算模型在每场测试比赛中的名次(基于它的比赛总分),再根据上式与所有人类选手的评分计算联合似然,以最大化该似然的模型评分为估计值,并对不同比赛中参与人数的差异做了加权平均。我们验证了该方法可利用选手在比赛中的实际表现大体复原其已知评分,并且也与选手的解题数线性拟合得到的评分相符合。
B.5 百分位表现
Codeforces 有一个针对活跃用户的全球榜单,因此可以用模型的预估评分来与整个平台的玩家做比较。我们也可将模型在测试集中与实际参赛的选手做直接比较。图10显示了后者的结果:每个点代表一名在至少 8 场测试比赛中参赛的选手,横坐标是该选手当前的 CodeForces 评分,纵坐标是他们在所参与比赛中的平均解题率。可以看到,一部分最顶尖的人类选手的解题率仍然超过 85%,显著高于 AI;但从评分和解题率来看,o3 大约能排进世界前 200 名活跃选手之列。
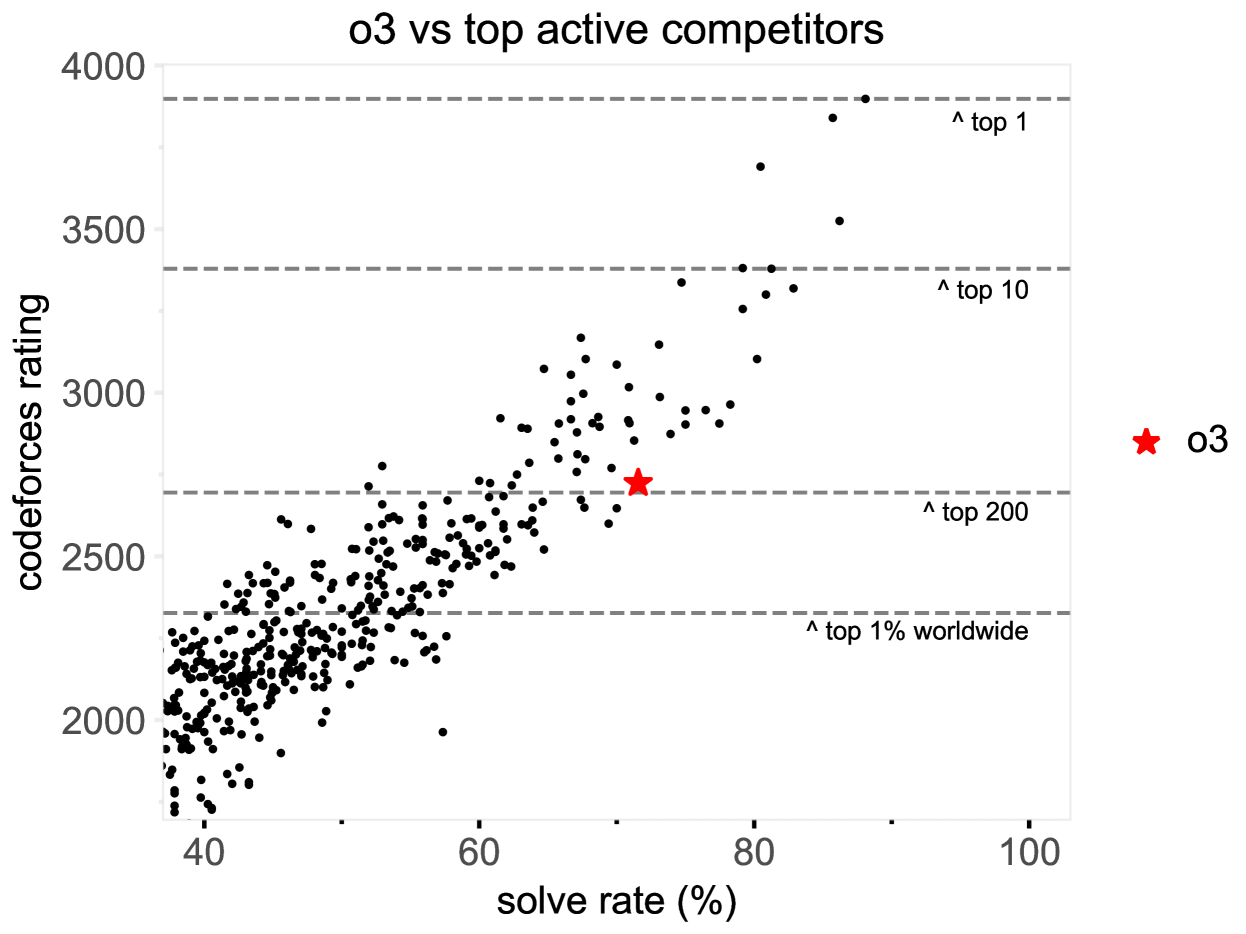 图 10:若将 o3 与在这 12 场测试比赛中至少参加 8 场的选手对比,o3 将排在世界顶尖编程选手之列。图中横坐标为选手的现有 CodeForces 评分,纵坐标为他们在参赛的比赛中的平均解题数。横线标出了 CodeForces 全站活跃选手在不同区段的评分边界。不难看出,目前顶尖人类选手依然在解题率上领先于 AI。
图 10:若将 o3 与在这 12 场测试比赛中至少参加 8 场的选手对比,o3 将排在世界顶尖编程选手之列。图中横坐标为选手的现有 CodeForces 评分,纵坐标为他们在参赛的比赛中的平均解题数。横线标出了 CodeForces 全站活跃选手在不同区段的评分边界。不难看出,目前顶尖人类选手依然在解题率上领先于 AI。
B.6 按题目细分结果
表 1:我们通过模拟比赛来估计 CodeForces 评分。此处省略了对 o3 的逐题表现的具体表格细节;详见原文表格 1(或引用中相应位置)。
problempass@1problemrating(no ranking)
pass@10(no ranking)
failed submissions
pass@10(ranking 1162)
Contest 1909 - 23/Dec/23 - Pinely score: 7,220
Round 3 (Div.
1 + Div. 2)
1909 A8001156 / 1162
1.00
0
solved
1909 B12001066 / 1162
1.00
0
solved
1909 C14001075 / 1162
1.00
0
solved
1909 D19001099 / 1162
1.00
0
solved
1909 E2400703 / 1162
1.00
0
solved
1909 F1220057 / 1162
0.40
0
solved
1909 F225000 / 1162
0.00
0
not solved
1909 G30003 / 1162
0.03
0
not solved
1909 H35000 / 1162
0.00
0
not solved
1909 I19000 / 1162
0.00
0
not solved
Contest 1916 - 30/Dec/23 - Good
Bye 2023
score: 8,920
1916 A8001157 / 1162
1.00
0
solved
1916 B10001133 / 1162
1.00
0
solved
1916 C12001145 / 1162
1.00
0
solved
1916 D1700483 / 1162
1.00
0
solved
1916 E23006 / 1162
0.05
0
solved
1916 F2900369 / 1162
0.98
2
solved
1916 G35000 / 1162
0.00
0
not solved
1916 H127001059 / 1162
1.00
0
solved
1916 H227001045 / 1162
1.00
0
solved
Contest 1919 - 06/Jan/24 - Hello 2 score: 6,214
024
1919 A8001161 / 1162
1.00
0
solved
problem problemrating
pass@1(no ranking)
pass@10# failed (no ranking)submissions
pass@10# failed (no ranking)submissions
pass@10(ranking 1162)
--
--
--
--
--
1919 B800
1141 / 1162
1.000
1.000
solved
1919 C1400
499 / 1162
1.000
1.000
solved
1919 D2100
25 / 1162
0.202
0.202
solved
1919 E2600
6 / 1162
0.051
0.051
solved
1919 F12300
1090 / 1162
1.000
1.000
solved
1919 F22800
227 / 1162
0.890
0.890
solved
1919 G3500
0 / 1162
0.000
0.000
not solved
1919 H2000
0 / 1162
0.000
0.000
not solved
Contest 1942 - 30/M
ar/24 - CodeTON Round 8 (Div. 1 + Div. 2, Rated, Prizes!)
ar/24 - CodeTON Round 8 (Div. 1 + Div. 2, Rated, Prizes!)
ar/24 - CodeTON Round 8 (Div. 1 + Div. 2, Rated, Prizes!)
ar/24 - CodeTON Round 8 (Div. 1 + Div. 2, Rated, Prizes!)
score: 8,701
1942 A800
1157 / 1162
1.000
1.000
solved
1942 B1100
1157 / 1162
1.000
1.000
solved
1942 C11300
999 / 1162
1.000
1.000
solved
1942 C21700
525 / 1162
1.001
1.001
solved
1942 D2100
1061 / 1162
1.000
1.000
solved
1942 E2300
347 / 1162
0.970
0.970
solved
1942 F2700
0 / 1162
0.000
0.000
not solved
1942 G2800
239 / 1162
0.900
0.900
solved
1942 H3500
0 / 1162
0.000
0.000
not solved
Contest 1943 - 16/Mar/24 - Codeforces Round 934 (Div. 1)
Contest 1943 - 16/Mar/24 - Codeforces Round 934 (Div. 1)
Contest 1943 - 16/Mar/24 - Codeforces Round 934 (Div. 1)
Contest 1943 - 16/Mar/24 - Codeforces Round 934 (Div. 1)
score: 3,427
1943 A1300
116 / 1162
0.650
0.650
solved
1943 B2000
1 / 1162
0.010
0.010
not solved
1943 C2300
160 / 1162
0.770
0.770
solved
1943 D12400
848 / 1162
1.000
1.000
solved
1943 D22800
14 / 1162
0.110
0.110
solved
1943 E12900
0 / 1162
0.000
0.000
not solved
1943 E23300
0 / 1162
0.000
0.000
not solved
1943 F3500
0 / 1162
0.000
0.000
not solved
Contest 1951 - 06/Apr/24 - Codeforces Global Round 25 score: 9,396
Contest 1951 - 06/Apr/24 - Codeforces Global Round 25 score: 9,396
Contest 1951 - 06/Apr/24 - Codeforces Global Round 25 score: 9,396
Contest 1951 - 06/Apr/24 - Codeforces Global Round 25 score: 9,396
1951 A900
1157 / 1162
1.000
1.000
solved
1951 B1200
1150 / 1162
1.000
1.000
solved
1951 C1400
1155 / 1162
1.000
1.000
solved
1951 D2000
875 / 1162
1.000
1.000
solved
1951 E2000
1009 / 1162
1.000
1.000
solved
1951 F2500
53 / 1162
0.370
0.370
solved
1951 G3100
34 / 1162
0.260
0.260
solved
1951 H3200
1 / 1162
0.010
0.010
not solved
1951 I3200
0 / 1162
0.000
0.000
not solved
Contest 1965 - 27/Ascore: 3,891
pr/24 - Codeforces Round 941 (Div. 1)
pr/24 - Codeforces Round 941 (Div. 1)
pr/24 - Codeforces Round 941 (Div. 1)
1965 A1400
1143 / 1162
1.000
1.000
solved
1965 B1800
1064 / 1162
1.000
1.000
solved
1965 C2300
313 / 1162
0.960
0.960
solved
1965 D2900
690 / 1162
1.000
1.000
solved
1965 E3100
0 / 1162
0.000
0.000
not solved
1965 F3300
0 / 1162
0.000
0.000
not solved
Contest 1967 - 30/Ascore: 3,871
pr/24 - Codeforces Round 942 (Div. 1)
pr/24 - Codeforces Round 942 (Div. 1)
pr/24 - Codeforces Round 942 (Div. 1)
1967 A1400
1088 / 1162
1.000
1.000
solved
1967 B11400
1154 / 1162
1.000
1.000
solved
1967 B22200
1149 / 1162
1.000
1.000
solved
1967 C2300
1116 / 1162
1.000
1.000
solved
1967 D2800
9 / 1162
0.080
0.080
solved
1967 E13100
0 / 1162
0.000
0.000
not solved
1967 E23500
0 / 1162
0.000
0.000
not solved
1967 F3200
0 / 1162
0.000
0.000
not solved
Contest 1975 - 25/May/24 - Codeforces Round 947 (Div. 1 + Div. 2) score: 5,959
Contest 1975 - 25/May/24 - Codeforces Round 947 (Div. 1 + Div. 2) score: 5,959
Contest 1975 - 25/May/24 - Codeforces Round 947 (Div. 1 + Div. 2) score: 5,959
Contest 1975 - 25/May/24 - Codeforces Round 947 (Div. 1 + Div. 2) score: 5,959
Contest 1975 - 25/May/24 - Codeforces Round 947 (Div. 1 + Div. 2) score: 5,959
problem problemrating
pass@1(no ranking)
pass@10# failed (no ranking)submissions
pass@10(ranking 1162)
--
--
--
--
1975 A800
1161 / 1162
1.000
solved
1975 B1000
1091 / 1162
1.000
solved
1975 C1200
492 / 1162
1.000
solved
1975 D1700
9 / 1162
0.083
solved
1975 E2100
80 / 1162
0.511
solved
1975 F2600
12 / 1162
0.100
solved
1975 G3000
0 / 1162
0.000
not solved
1975 H3500
0 / 1162
0.000
not solved
1975 I3500
0 / 1162
0.000
not solved
Contest 1984 - 09/Jun/24 - Codeforces Global Round 26 score: 12,255
Contest 1984 - 09/Jun/24 - Codeforces Global Round 26 score: 12,255
Contest 1984 - 09/Jun/24 - Codeforces Global Round 26 score: 12,255
Contest 1984 - 09/Jun/24 - Codeforces Global Round 26 score: 12,255
1984 A800
1161 / 1162
1.000
solved
1984 B1100
1158 / 1162
1.000
solved
1984 C11300
914 / 1162
1.000
solved
1984 C21700
768 / 1162
1.000
solved
1984 D2000
193 / 1162
0.841
solved
1984 E2400
849 / 1162
1.001
solved
1984 F2500
918 / 1162
1.000
solved
1984 G3200
0 / 1162
0.000
not solved
1984 H3300
138 / 1162
0.723
solved
Contest 2002 - 11/Aug/24 - EPIC IoT Round August 2024 (Div. 1 + Div. 2)
Contest 2002 - 11/Aug/24 - EPIC IoT Round August 2024 (Div. 1 + Div. 2)
Contest 2002 - 11/Aug/24 - EPIC IoT Round August 2024 (Div. 1 + Div. 2)
Contest 2002 - 11/Aug/24 - EPIC IoT Round August 2024 (Div. 1 + Div. 2)
score: 8,981
2002 A800
1161 / 1162
1.000
solved
2002 B1000
1152 / 1162
1.000
solved
2002 C1200
1096 / 1162
1.000
solved
2002 D11900
1067 / 1162
1.000
solved
2002 D22300
805 / 1162
1.000
solved
2002 E2300
232 / 1162
0.890
solved
2002 F12600
12 / 1162
0.108
solved
2002 F22800
7 / 1162
0.060
not solved
2002 G3400
143 / 1162
0.731
solved
2002 H3500
0 / 1162
0.000
not solved
Contest 2006 - 30/Aug/24 - Codeforces Round 969 (Div. 1)
Contest 2006 - 30/Aug/24 - Codeforces Round 969 (Div. 1)
Contest 2006 - 30/Aug/24 - Codeforces Round 969 (Div. 1)
Contest 2006 - 30/Aug/24 - Codeforces Round 969 (Div. 1)
score: 2,757
2006 A1700
945 / 1162
1.000
solved
2006 B1800
1149 / 1162
1.000
solved
2006 C2300
811 / 1162
1.000
solved
2006 D2600
2 / 1162
0.020
not solved
2006 E3100
4 / 1162
0.030
not solved
2006 F3500
0 / 1162
0.000
not solved
CIOI Submissions
This section presents the solutions generated by o1-ioi during the 2024 International Olympiad in Infor matics.
C.1Nile
All 100 possible points for Nile were scored in a single submission.
```
include "nile.h"
include <bits/stdc++.h>
using namespace std;
struct UF{
vector<int> parent, sizee, minIndex;
vector<array<long long, 2>> singledPat; // singledPat[0] = min d[i] for i mod 2 = 0 in
block, singledPat[1] for i mod 2 = 1 in block
vector<long long> singledBr; // singled bridging
vector<long long> singled; // singled in block
};
long long sumSingledGlobal = 0;
int findRoot(UF &u, int x){
if(u.parent[x] == x) return x;
u.parent[x] = findRoot(u, u.parent[x]);
return u.parent[x];
}
void updateSingled(UF &u, int r){
if(u.sizee[r] %
u.singled[r] = 0;
} else {
long long val = min(u.singledPat[r][u.minIndex[r] %
if(val == LLONG_MAX)va1=0; // if no such node found, singled = 0?
u.singled[r] = val;
}
}
void unionNodes(UF &u, int a, int b){
a = findRoot(u, a);
b = findRoot(u, b);
if(a==b) return; // already in the same component
sumSingledGlobal -= u.singled[a];
sumSingledGlobal -= u.singled[b];
// union by size
if(u.sizee[a] < u.sizee[b]) swap(a, b);
u.parent[b]=a;
int newSize = u.sizee[a] + u.sizee[b];
int newMinIndex = min(u.minIndex[a], u.minIndex[b]);
array<long long, 2> newSingledPat;
newSingledPat[0] = min(u.singledPat[a][0], u.singledPat[b][0]);
newSingledPat[1] = min(u.singledPat[a][1], u.singledPat[b][1]);
long long newSingledBr = min(u.singledBr[a], u.singledBr[b]);
u.sizee[a] = newSize;
u.minIndex[a]=newMinIndex;
u.singledPat[a] = newSingledPat;
u.singledBr[a] = newSingledBr;
updateSingled(u, a);
sumSingledGlobal += u.singled[a];
}
void addBridging(UF &u, int x, long long val){
intx= findRoot(u, x);
sumSingledGlobal -= u.singled[r];
if(u.sizee[r] %
u.singledBr[r] = min(u.singledBr[r], val);
updateSingled(u, r);
} else {
// block size is even, singled = 0 anyway, bridging won’t matter because singledBr is for odd sized block.
// but bridging might matter if block size becomes odd in future merges, so store singledBr as well.
u.singledBr[r] = min(u.singledBr[r], val);
// singled is 0 anyway
}
sumSingledGlobal += u.singled[r];
}
std::vector<long long> calculate_costs(
std::vector<int> W, std::vector<int> A,
std::vector<int> B, std::vector<int> E){
intN=W.sinze();
intQ=E.sinze();
vector<int> idx(N); iota(idx.begin(), idx.end(), 0);
sort(idx.begin(), idx.end(), &{return W[a] < W[b];});
vector<long long> sortedW(N), d(N);
i=0;i<N;i++)
sortedw[i]=W[idx[i]];
d[i] = (long long)A[idx[i]] - (long long)B[idx[i]];
}
long longsupB=0;
for(int i=0;i<N;i++) sumB +=B[idx[i]];
struct Edge{ long long diff; int idx;};
vector<Edge> edges;
edges.reserve(N-1);
for(int i=0; i < N-1; i++) {
edges.push_back({sortedW[i+1] - sortedW[i], i});
}
sort(edges.begin(), edges.end(), &{return a.diff <
b.diff;});
vector<pair<long long, int>> bridging;
bridging.reserve(N-2);
for(int i=1;1<N-1; i++) {
long long val = sortedW[i+1] - sortedW[i-1];
bridging.push_back({val, i});
}
sort(bridging.begin(), bridging.end(), &{return a.first < b.first;});
vector<pair<long long, int>> queriesVec;
queriesVec.reserve(Q);
for(int i = 0; i < Q; i++) queriesVec.push_back({(long long)E[i], i});
sort(queriesVec.begin(), queriesVec.end(), &{return a.first <
b.first;});
UF u;
u.parent.resize(N);
u.sizee.resize(N);
u.minIndex.resize(N);
u.singledPat.resize(N);
u.singledBr.resize(N);
u.singled.resize(N);
for(int i=0;i<N;i++) {
u.parent[1]=i;
u.sinxsec[i]=1;
u.minIndex[i] = i;
u.singledPat[i][0] = (i %
u.singledPat[i][1] = (i %
u.singledBr[i] = LLONG_MAX;
u.sing1ed[i]=d[i];11singled=d[i] because block size 1 is odd
}
sumSingledGlobal=0
for(inti=0;i<N;i++){
sumSingledGlobal += u.singled[i];
}
vector<long long> result(Q);
intpcosE=0;;//index in edges
int posB = 0; // index in bridging
for(inti=0;i<Q;i++λf
long long D = queriesVec[i].first;
int qidx = queriesVec[i].second;
while(posE < (int)edges.size() && edges[posE].diff <= D) {
unionNodes(u, edges[posE].idx, edges[posE].idx+1);
posE++;
}
while(posB < (int)bridging.size() && bridging[posB].first <= D) {
intx=bridging[posB].second;
addBridging(u, x, d[x]);
posB++;
}
long long costVal = sumB + sumSingledGlobal;
result[qidx] = costVal;
}
return result;
} ```
C.2Message
This solution achieved a score of 79.64 out of 100, with full marks awarded for subtask 1 and partial credit received for subtask 2.
```
include "message.h"
include <bits/stdc++.h>
using namespace std;
extern std::vector<bool> send_packet(std::vector<bool> A);
void send_message(std::vector<bool> M, std::vector<bool> C)
{
vector<int> safe_cols;
vector<int> sabotage_cols;
for (inti=0; i < 31; i++) {
if (!C[i]) safecols.pushback(i);
else sabotagecols.pushback(i);
}
// Step 1: send the first 4 packets with distinct sequences.
vector<vector<bool>> first4results;
first4results.reserve(4);
for (intP=0;p<4;p++){
vector<bool> A(31, false);
i=0;i<16;i++
int $c o l = s a f e _ { - } c o l s [ i ]$
$\int ( i t ) d t = ( i > > p )$ & 1; // p-th bit of i, i is the index in safe subset
A[col] = bit;
}
for (int col : sabotage_cols) {
A[cos1]=false;
}
std::vector<bool>B=send_packet(A);
first4results.push_back(B);
}
// Now identify known safe column from the results of these 4 calls.
vector<string> colSequences(31, string(4, ’0’));
for (intc=0;c<31;c+1
x=0;x<4;x++)
colSequences[c][r] = first4results[r][c] ? ’1’ : ’0’;
}
}
map<string, vector<int>> seqToCols;
for (intc=0;c<31;c+t)t
seqToCols[colSequences[c]].push_back(c);
}
int knownSafeCol = -1;
for (auto &kv : seqToCols) {
if (kv.second.size() == 1) {
int col = kv.second[0];
// check if col is in safe subset. Because known safe column must be a safe column.
if (find(safecols.begin(), safecols.end(), col) != safe_cols.end()) {
// also check if the sequence is one of the distinct sequences for safe subset.
The index in the safe subset is i, the sequence is 4 bits representing i.
string seq = kv.first;
int va1=0;
for (inti=0;i<4;i+i)t
if$( \sec _ { 1 } ] = - 1 ^ { \prime } ) v a 1 = ( 1 < < i ) ;$
}
// check if val is < 16.
(va1<16)16)(
known1SafeCol=col
break;
}
}
}
}
if (knownSafeCol =-1) {
// If not found, pick a safe column that has a distinct sequence anyway.
// But for correctness, we require knownSafeCol to be found. If not found, our method
has a problem.
}
// Step 2: store sabotage subset’s bits in the known safe column in next 31 calls. The other 15 safe columns store message bits if available.
int S = M.size(); // message length.
int offset = 0; // offset in M.
for (inti=0;i<31;i++λf
vector<bool> A(31, false);
int sabotageBit = C[i];
A[knownSafeCol] = sabotageBit; // store sabotage subset’s bit i in known safe column.
for (int c : safe_cols) {
(c= knownSafeCol) continue; // skip known safe column because we used it for
sabotage subset.
int col = c;
(offset<S)
A[co1]=M[offaot];
offset++;
} else {
A[col] = false;
}
}
for (int sc : sabotage_cols) {
A[sc] = false;
}
std::vector<bool> B=send_packet(A);
// We do not store B because we do not need to adapt further. Actually, we can store B
if we want to adapt but the solution does not require further adaptation.
}
// Step 3: store message length in the next 11 calls in the known safe column. The other 15safe columns store more message bits if available.
L=S
vector<int> lengthBinary(11, 0);
for (inti=0;i<11;i++2i
lengthBinary[i] = (L >> i) & 1;
}
for (int i=0;i<11;i++λf
vector<bool> A(31, false);
int bit = lengthBinary[i];
A[knownSafeCol] = bit;11store length bit i in known safe column.
for (int c : safe_cols) {
if (c(c==knownSafeCol) continue; // skip known safe column.
col=c;
if(offset<S)
A[co1]==M[offset];
offset++;
} else {
}
}
for (int sc : sabotage_cols) {
}
std::vector<bool>$B = s e n d _ { - } p a c k e t ( A ) ;$
}
// Step 4: store the rest of the message in subsequent calls using all 16 safe columns.
int messageLeft = S - offset; // how many bits are left to store.
int fullColumns = 16; // number of safe columns.
int messageRows = (messageLeft + fullColumns - 1) / fullColumns; // how many rows needed.
for (intx=0;x<messageRows; r++) {
vector<bool> A(31, false);
for (int i = 0; i < fullColumns && offset + i < S; i++) {
int col = safe_cols[i];
A[co1]=M[offset+i];
}
offset += fullColumns;
for (int sc : sabotage_cols) {
A[sc]=false;
}
std::vector<bool> B = send_packet(A);
}
}
std::vector<bool> receive_message(std::vector<std::vector<bool>> R)
{
A[co1]=falce;
A[sc]=false
int n = R.size();
vector<bool> result; // message to return.
(n<4)
return result;
}
// Step 1: from the first 4 rows in R, find the known safe column.
vector<string> colSequences(31, string(4, ’0’));
for (int c = 0; c < 31; c++) {
x=0;x<4数kx<n;x++)
if (x<n) {
colSequences[c][r] = R[r][c] ? ’1’ : ’0’;
}
}
}
map<string, vector<int>> seqToCols;
for (intc=0;c<31; c+t)t
seqToCols[colSequences[c]].push_back(c);
}
int knownSafeCol=-1;
for (auto &kv : seqToCols) {
if (kv.second.size() == 1) {
int col = kv.second[0];
// check if the sequence is one of the binary representations from 0..15 because safe subset’s sequences are distinct and in that range.
string seq = kv.first;
int val = 0;
for (int i=0;i<4;i++)t
[i]=⋯"1") |=(1<<i)
}
if (va1<16) {
knowsafeCol=col;
break;
}
}
}
if (knownSafeCol=-1) {
// If none found, that means sabotage overcame the method or we made an error.
}
// Step 2: from next 31 rows in known safe column, read sabotage subset.
vector<bool> sabotageSubset(31, false);
int sabotageStart = 4;
for (int i=0; i < 31 && sabotageStart + i < n; i++) {
sabotageSubset[i] = R[sabotageStart + i][knownSafeCol];
}
// Step 3: from next 11 rows in known safe column, read length.
vector<bool> lengthBits(11, false);
int lengthStart = sabotageStart + 31;
for (int i = 0; i < 11 && lengthStart+i<n;i++) {
lengthBits[i] = R[lengthStart + i][knownSafeCol];
}
int messageLength = 0;
i=0;i<11;i++)
messageLength |= (lengthBits[i] << i);
}
// Step 4: identify safe columns from sabotage subset.
vector<int> safe_cols;
for (inti=0;i<31;i++) {
if (!sabotageSubset[i]) safecols.pushback(i);
}
// Step 5: read message from the next (31 + 11) rows’ other safe columns and from subsequent rows using all safe columns.
vector<bool> message;
int offset = 0; // offset in message.
int sabotageRowStart = 4;
int sabotageRows = 31;
for (int r = sabotageRowStart; r < sabotageRowStart + sabotageRows && r < n; r++) {
for (int c : safe_cols) {
if (c == knownSafeCol) continue; // skip known safe column.
if (offset < messageLength) {
message.push_back(R[r][c]);
offset++;
}
}
}
int lengthRowStart = sabotageRowStart + sabotageRows;1/4+31=35.
int lengthRows = 11;
for (intx=1lengthRowStart; r < lengthRowStart + lengthRows &&r<n;r++){
for (int c : safe_cols) {
if (c == knownSafeCol) continue; // skip known safe column.
if (offset < messageLength) {
message.push_back(R[r][c]);
offset++;
}
}
}
int restRowStart = lengthRowStart + lengthRows; // 4 + 31 + 11 = 46.
int fullColumns = 16;11 number of safe columns.
int messageLeft = messageLength - offset;
int rowsForMessage = (messageLeft + fullColumns - 1) / fullColumns; // number of rows needed.
for (intx=restRowStart; r < restRowStart + rowsForMessage && r < n; r++) {
for (int i = 0; i < fullColumns && offset < messageLength; i++) {
intco1=$s a f e _ { - } c o l s [ i ] ;$
message.push_back(R[r][col]);
offset++;
}
}
// The message is now in vector message. If offset < messageLength, we did not get all bits. but we should.
return message;
} ```
C.3 Tree
A total of 30 points were scored on Tree across two separate submissions.
C.3.1Submission 1
The frst submission achieved a score of 17 out of 100, with points earned from subtasks 1 and 4.
```
include "tree.h"
include <bits/stdc++.h>
using namespace std;
static int NGlobal;
static vector<int> parentGlobal;
static vector<int> weightGlobal;
static vector<long long> deltaGlobal;
static vector<int> leafCountGlobal;
static vector<int> sortedByLeafCount; // We’ll store node indices sorted by leaf count.
static vector<long long> prefixDelta, prefixDeltaTimesLeafCount; // prefix sums in sorted order by leaf count.
static long long sumAllDelta;
static vector<vector<int>> childrenGlobal;
int computeLeafCountRec(int v){
if (childrenGlobal[v].empty()){ // leaf
leafCountGlobal[v] = 1;
return 1;
} else {
int sum=0;
for (int c : childrenGlobal[v]) sum += computeLeafCountRec(c);
leafCountGlobal[v] = sum;
return sum;
}
}
void init(std::vector<int> P, std::vector<int> W){
N=
NGlobal = N;
parentGlobal = P;
weightGlobal = W;
if(N=0) return;
childrenGlobal.assign(N, {});
for (int i=1; i<N; i++) childrenGlobal[parentGlobal[i]].push_back(i);
leafCountGlobal.resize(N);
computeLeafCountRec(0);
vector<int> deg(N,0);
for (int i=1;i < N; i++) deg[parentGlobal[i]]++;
deltaGlobal.resize(N);
for (inti=0;i<N;i++λf
if (parentGlobal[i]=-1){//xoot
if (deg[i]=0)f//leaf root
deltaGlobal[i] = weightGlobal[i];
} else { // internal root
deltaGlobal[i] = - (long long)weightGlobal[i];
}
} else {
if (deg[i]=0)[//1eaf
deltaGlobal[i] = (long long)weightGlobal[parentGlobal[i]] + (long
long)weightGlobal[i];
} else { // internal
deltaGlobal[i] = (long long)weightGlobal[parentGlobal[i]] - (long
long)weightGlobal[i];
}
}
}
sortedByLeafCount.resize(N);
iota(sortedByLeafCount.begin(), sortedByLeafCount.end(), 0);
sort(sortedByLeafCount.begin(), sortedByLeafCount.end(), {
return leafCountGlobal[a] < leafCountGlobal[b];
});
prefixDelta.resize(N,0);
prefixDeltaTimesLeafCount.resize(N,0);
sumAllDelta=0;
for (int i=0; i<N; i++) sumAllDelta += deltaGlobal[i];
long long runningDeltaTimesLeaf = 0;
long long runningDelta = 0;
for (inti=0; i < N;i+i)i
int idx = sortedByLeafCount[i];
long long valDeltaTimesLeaf = deltaGlobal[idx] * (long long)leafCountGlobal[idx];
runningDeltaTimesLeaf += valDeltaTimesLeaf;
runningDelta += deltaGlobal[idx];
prefixDeltaTimesLeafCount[i] = runningDeltaTimesLeaf;。
prefixDelta[i] = runningDelta;
}
}
long long query(int L, int R){
if (NGlobal ==0) return 0; // no nodes
long long a=R/ L; // floor of R/L.
$\int l t 1 e f t = - 1 ;$
intright=NGlobal;
while (right - left > 1){
int minid=(logtt+xight)/2;
int node = sortedByLeafCount[mid];
if ((long long)leafCountGlobal[node] <= a) left = mid; else right = mid;
}
int idx=1eft;11 idx is the last index where b[i] <=a.
long long sumA = 0;// sum of delta[i]*b[i] for nodes with b[i] <= a.
if (idx>=0) {
sumA = prefixDeltaTimesLeafCount[idx]; // sum_{i: b[i] <= a} delta[i]*b[i]
}
long long sumPrefixDeltaWhereLessOrEqual = 0;
if (idx >=0) sumPrefixDeltaWhereLessOrEqual = prefixDelta[idx]; else
sumPrefixDeltaWhereLessOrEqual=0
long long sumDeltaWhereBGreater = sumAllDelta - sumPrefixDeltaWhereLessOrEqual;
long long LLL=(10ng10ng)L;
long long RRR=(1ong1ong)R;
long longpartA=LLL*sumA;
long long partB = RRR * sumDeltaWhereBGreater;
long long cost = partA + partB;
return cost;
}
C.3.2Submission 2
Submission 2 achieved 13 of 100 points on subtask 2.
include "tree.h"
include <bits/stdc++.h>
using namespace std;
struct Pt {
long long x;
long long y;
};
struct PWL {
long long L, R;
vector<Pt> pts; // sorted by x
};
int NGlobal;
int PGlobal[2005];
int wGlobal[2005];
vector<int> childrenGlobal[2005];
PWL GGlobal[2005];
// define the helper functions as static.
static long long evalPWL(const PWL &f, long long x) {
if (f.pts.empty()) return LLONG_MAX/2; // no function
if (x <= f.pts.front().x) {
return f.pts.front().y; // domain out, but we prefer front.
}
(x >= f.pts.back().x) {
return f.pts.back().y; // domain out, but prefer back.
}
int left=00, right = f.pts.size()-1;
while (left+1 < right) {
$\int ( 1 0 t )$
if (f.pts[mid].x == x) return f.pts[mid].y;
if (f.pts[mid].x < x) left = mid; else right = mid;
}
if (f.pts[left].x <= x && x <= f.pts[right].x) {
long long x1 = f.pts[left].x;
long long y1 = f.pts[left].y;
long long x2 = f.pts[right].x;
long long y2 = f.pts[right].y;
if (x1 == x2) return y1;
long double slope = (long double)(y2 - y1)/(long double)(x2 - x1);
long double valf = (long double) y1+s1ope*(x-x1);
long long vali = (long long) llround(valf);
return vali;
} else {
return LLONG_MAX/2;
}
}
struct ChildState {
int idx; // child index in local array
long long x; // current x in child’s domain
int seg; // segment in child’s function
long double slope;
long long nextBound;
};
static PWL combineChildren(const vector<PWL> &childF, long long L, long long R) {
intd=chi1dF.size();
if (d=0)t
PWLf;f.L=L;f.R=R;f.pts={fL,0}, {R, 0}}; return f;
}
long long sumDomainL = (long long)d * L;
long long sumDomainR = (long long)d * R;
vector<ChildState> cs(d);
priority_queue<pair<long double, int>, vector<pair<long double, int>>, greater<pair<long double, int>>> pq;
for (inti=0;i<d;i++ {
csc[i],idx=i;
csc[1],x=L;
intseg=0;∈tn=childF[i].pts.size();
while (seg < n-1 && childF[i].pts[seg+1].x⇔L) seg++;
cs[i].seg=seg;
long double slope = 0;
if (sect+1<n)
long long dx = childF[i].pts[seg+1].x - childF[i].pts[seg].x;
long long dy = childF[i].pts[seg+1].y - childF[i].pts[seg].y;
slope = dx!=0?(long double)dy/dx:0;
} else {
slope=0;
}
cs[i].slope = slope;
if (εeg+1<n) cs[i].nextBound = min((long long)childF[i].pts[seg+1].x, R);
else cs[i].nextBound = R;
pq.push({slope, i});
}
long long sum = sumDomainL;
long long cost=0;
for (inti=0;i<d;i++λf
cost += evalPWL(childF[i], L);
}
vector<Pt> fpts;
fpts.push_back({sum, cost});
while (!pq.empty() && sum < sumDomainR) {
auto top = pq.top();
long double slope = top.first;
vector<int> group;
while (!pq.empty() && abs(pq.top().first - slope) < 1e-9) {
group.push_back(pq.top().second);
pq.pop();
}
if (group.empty()) break;
long long inc = LLONG_MAX;
for (int idx : group) {
long long newInc = cs[idx].nextBound - cs[idx].x;
if (newInc < inc) inc = newInc;
}
if (∈c<0){
for (int idx : group) {
pq.push({cs[idx].slope, idx});
}
break;
}
long long feasibleInc = inc;
if (sum + (long long)group.size() * inc > sumDomainR) {
feasibleInc = (sumDomainR - sum) / (long long) group.size();
}
if (feasibleInc <= 0) {
for (int idx : group) {
pq.push({cs[idx].slope, idx});
}
break;
}
sum = sum + group.size() * feasibleInc;
long double dcost = slope * feasibleInc * group.size();
cost = (long long) llround((long double)cost + dcost);
fpts.push_back({sum, cost});
for (int idx : group) {
cs[idx].x += feasibleInc;
if (cs[idx].x == cs[idx].nextBound) {
const PWL &g = childF[idx];
int seg = cs[idx].seg;
if (cs[idx].x == R) {
cs[idx].slope = 1e9; // saturate
cs[idx].nextBound = R;
} else {
seg++;
cs[idx].seg = seg;
int n = g.pts.size();
if (seg+1 < n) {
long long dx = g.pts[seg+1].x-gg.pts[seg].x;
long long dy = g.pts[seg+1].y - g.pts[seg].y;
long double slopeC = dx!=0?(long double)dy/dx:0;
cs[idx].slope = slopeC;
cs[idx].nextBound = min((long long)g.pts[seg+1].x, R);
} else {
cs[idx].slope = 0;
cs[idx].nextBound = R;
}
}
}
}
for (int idx : group) {
if (cs[idx].x < R) {
pq.push({cs[idx].slope, idx});
}
}
}
vector<Pt> unify;
unify.push_back(fpts[0]);
for (inti=1; i < fpts.size(); i++) {
if (fpts[i].x == unify.back().x) {
unify.back().y = min(unify.back().y, fpts[i].y);
} else unify.push_back(fpts[i]);
}
vector<Pt> final;
if (!unify.empty()) final.push_back(unify[0]);
for (inti=1;1< unify.size()-1; i++) {
long longx1=final.back().x;
long long y1 = final.back().y;
long longx2=unify[i].x;
long longy2=unify[i].y;
long longx3=unify[i+1].x;
long longy3=unify[i+1].y;
long double slope1 = (x2!=x1)? (long double)(y2-y1)/(x2-x1) : 1e9;
long double slope2 = (x3!=x2)? (long double)(y3-y2)/(x3-x2) : 1e9;
if (abs(slope1 - slope2) < 1e-9) {
// unify linear, skip unify[i]
} else {
final.push_back(unify[i]);
}
}
if (!unify.empty()) final.push_back(unify.back());
PWL result;
result.L = sumDomainL; result.R = sumDomainR;
result.pts = final;
return result;
}
static PWL parentFormula(const PWL &f, long long wVal, long long L, long long R) {
vector<long long> candVal;
candVal.push_back(L);
candVal.push_back(R);
for (auto &p : f.pts) {
if (p.x >= L &&p.x<=R)candVal.push_back(p.x)
}
if (f.L >= L && f.L <= R) candVal.push_back(f.L);
if (f.R >= L && f.R <= R) candVal.push_back(f.R);
for (int i = 0; i < (int)f.pts.size()-1; i++) {
long long sx = f.pts[i].x;
long long sy=f.pts[i+1].x;
long long dx = sy - sx;
long longdy=f,ptε[i+1],y-f,ptε[i],y;
long double a = dx!=0? (long double)dy/dx:0;11slope in s domain
if (a <= wVal && a>=-wval)t
long long inL = max(sx, (long long)L);
long long inR = min(sy, (long long)R);
if (inL <= inR) {
candVal.push_back(inL);
candVal.push_back(inR);
}
}
}
sort(candVal.begin(), candVal.end());
candVal.erase(unique(candVal.begin(), candVal.end()), candVal.end(), candVal.end()), candVal.end());()
vector<Pt> pts;
for (auto val : candVal) {
long long bestCost = LLONG_MAX/2;
if (val >= f.L && val <= f.R) {
int 1eft=0, right = f.pts.size()-1;
while (left+1 < right) {
intminid=(1eft+right) / 2;
if (f.pts[mid].x <= val) left = mid; elseright=minid;
}
if (f.pts[left].x <= val && val <=f.pts[right].x) {
long long x1 = f.pts[left].x;
long long y1 = f.pts[left].y;
long long x2 = f.pts[right].x;
long long y2 = f.pts[right].y;
long double slope = (x2!=x1? (long double)(y2 - y1)/(long double)(x2 - x1) : 0);
if (slope <= wVal && slope >= -wVal && val >= x1 && val <=x2)t
long double costf = (long double) y1 + slope * (long double)(val - x1);
long long c = (long long) llround(costf);
bestCost = min(bestCost, c);
}
}
}
for (auto &p : f.pts) {
long long s=P⋅x;
long long c = p.y + wVal * llabs(val - s);
if (c < bestCost) bestCost = c;
}
pts.push_back({val, bestCost});
}
sort(pts.begin(), pts.end(), {return a.x<b,x;3)
vector<Pt> unify;
unify.push_back(pts[0]);
for (int i = 1; i < pts.size(); i++) {
if (pts[i].x == unify.back().x) {
unify.back().y = min(unify.back().y, pts[i].y);
} else unify.push_back(pts[i]);
}
vector<Pt> final;
if (!unify.empty()) final.push_back(unify[0]);
for (inti=1;1<unify.size()-1; i++) {
long long x1 = final.back().x;
long long y1 = final.back().y;
long long x2=unify[i].x;
long long y2 = unify[i].y;
long long x3=unify[i+1].x;
long long y3 = unify[i+1].y;
long double slope1=x2!=x1?(long double)(y2-y1)/(x2-x1) : 1e9;
long double slope2=x3!=x2? (long double)(y3-y2)/(x3-x2) : 1e9;
if (abs(slope1 - slope2) < 1e-9) {
// unify linear, skip unify[i]
} else {
final.push_back(unify[i]);
}
}
if (!unify.empty()) final.push_back(unify.back());
PWL result;
result.L = L; result.R = R;
result.pts = final;
return result;
}
static void computeG(int node, long long L, long long R) {
for (int c : childrenGlobal[node]) {
computeG(c, L, R);
}
if (childrenGlobal[node].empty()) {
// leaf
PWL result;
result.L = L; result.R = R;
if (L<=0数发0<=R)
long long valL = wGlobal[node] * llabs(L);
long long val0 = wGlobal[node] * 0; // 0
long long valR = wGlobal[node] * llabs(R);
result.pts.clear();
result.pts.push_back({L, valL});
result.pts.push_back({0, val0});
result.pts.push_back({R, valR});
} else {
long long valL = wGlobal[node] * llabs(L);
long long valR = wGlobal[node] * llabs(R);
result.pts.clear();
result.pts.push_back({L, valL});
result.pts.push_back({R, valR});
}
GGlobal[node] = result;
} else {
vector<PWL> childF;
for (int c : childrenGlobal[node]) {
childF.push_back(GGlobal[c]);
}
PWL f=combineChildren(childF, L, R);
PWL p = parentFormula(f, wGlobal[node], L, R);
GGlobal[node] = p;
}
}
void init(std::vector<int> P, std::vector<int> W) {
NGlobal = W.size();
for (int i = 0; i < NGlobal; i++) {
PGlobal[i]=P[i];
wGlobal[i]=w[i];
}
for (int i = 0; i < NGlobal; i++) childrenGlobal[i].clear();
for (int i = 1; i < NGlobal; i++) {
childrenGlobal[P[i]].push_back(i);
}
}
long long query(int L, int R) {
computeG(0, L, R);
long long ans = LLONG_MAX;
for (auto &p : GGlobal[0].pts) {
if (p.y < ans) ans = p.y;
}
return ans;
}
C.4Hieroglyphs
A total of 44 points was scored on Hieroglyphs across two separate submissions.
C.4.1Submission 1
In the frst submission, a score of 34 out of 100 points was achieved, distributed across subtasks 1, 2,and 4.
include "hieroglyphs.h"
include <bits/stdc++.h>
using namespace std;
std::vector<int> ucs(std::vector<int> A, std::vector<int> B)
{
int N = (int) A.size();
int M = (int) B.size();
if(N=0||M=0){
std::vector<int> ret;
return ret;
}
const int MAX_VAL = 200001;
static int cntA[200002], cntB[200002];
for (inti=0;i<200002;i+4)(
cntA[i]=0;
cntB[i]=0;
}
for (int i = 0; i < N; i++) cntA[A[i]]++;
for (int i = 0; i < M; i++) cntB[B[i]]++;
static int cVal[200002];
for (int i = 0; i < 200002; i++) {
if (cntA[i] > 0 && cntB[i] > 0) {
cVal[i] = min(cntA[i], cntB[i]);
} else {
cVa1[i]=0;
}
}
long longsumC=0;
for (intx=0;x<200002;x+4) {
sumC +=cVal[x];
}
if (sumC=0) {
std::vector<int> ret;
return ret;
}
// Precompute earliest and latest occurrences in A and B for all x.
static int earliestA[200002], latestA[200002], earliestB[200002], latestB[200002];
for (inti=0; i < 200002; i++) {
earliestA[i]=-1;
1atcostA[i]=-1;
earliestB[i] = -1;
1atestB[i]=-1;
}
for (int i=0;i<N; i+i)t
int letter=A[i];
if (earliestA[letter]==-1) earliestA[letter] = i;
latestA[letter] = i;
}
for (inti=0;i<NM;i++) {
int letter = B[i];
if (earliestB[letter]==-1) earliestB[letter] = i;
latestB[letter] = i;
}
// Now intervals for cVal[x] = 1.
struct Interval {
int letter;
int eA, lA, eB, lB;
};
vector<Interval> intervals;
for (intx=0;x < 200002;x++){
if (cVal[x] == 1) {
Interval I;
I.letter = x;
I.eA = earliestA[x]; I.lA = latestA[x];
I.eB = earliestB[x]; I.lB = latestB[x];
intervals.push_back(I);
}
}
// sort intervals by eA.
std::sort(intervals.beginstd::sort(intervals.begin(), intervals.end() (), {return a.eA < b.eA;
});
// Balanced tree keyed by eB, store lB as well.
vector<int> segmentTree(4*(M+5), -1);
auto update = & -> void {
if (start ⋯end) {
segmentTree[idx] = val;
return;
}
int mid = (start+end)/2;
if (pos <= mid) f(idx*2, start, mid, pos, val, f);
else f(idx*2+1, mid+1, end, pos, val, f);
segmentTree[idx] = max(segmentTree[idx2], segmentTree[idx2+1]);
};
auto query = & -> int {
if (r < start || end < l) return -1;
if (l <= start && end <= r) {
return segmentTree[idx];
}
int mid = (start+end)/2;
int leftVal = f(idx*2, start, mid, l, r, f);
int rightVal = f(idx*2+1, mid+1, end, l, r, f);
return max(leftVal, rightVal);
};
vector<Interval> intervalsSortedByLA = intervals;
sort(intervalsSortedByLA.beginsort(intervalsSortedByLA.begin(), intervalsSortedByLA.end() (), intervalsSortedByLA.end(), {
return a.lA < b.lA;
});
int j=0;
for (inti=0;i<intervals.size(); i++) {
auto &x = intervals[i];
Ax=
// remove intervals from data structure where lA[y] < eAx.
while (j < intervalsSortedByLA.size() && intervalsSortedByLA[j]1A<eAx) {
auto &y = intervalsSortedByLA[j];
// remove y from segment tree keyed by eB[y].
update(1, 0, M-1, y.eB, -1, update);
j++;
}
// query in B dimension: find if there’s an interval y with eB[y] <= lB[x] and lB[y] >=eB[x].
int minB = x.eB; // eB[x]
int maxB = x.lB; // lB[x]
if (minB > maxB) {
// If eB[x] > lB[x], no intersection possible.
} else {
// query in the segment tree range [0, maxB] to find the maximum lB[y].
int maxVal = query(1, 0, M-1, 0, maxB, query);
if (maxVal >= minB) {
// found intersection with a letter y where cVal[y] = 1.
std::vector<int> ret;
ret.push_back(-1);
return ret;
}
}
// add x to data structure keyed by eB[x].
update(1, 0, M-1, x.eB, x.lB, update);
}
// If no intersection found among cVal=1 intervals, proceed with chain method.
// The chain method code.
static vector<int> posAarr[200002];
static vector<int> posBarr[200002];
for (int i = 0; i < 200002; i++) {
posAarr[i].clear();
posBarr[i].clear();
}
for (inti=0;i<N;i++λf
if (cVal[A[i]] > 0) posAarr[A[i]].push_back(i);
}
for (int i = 0; i < M; i++) {
if (cVal[B[i]] > 0) posBarr[B[i]].push_back(i);
}
struct QItem {
int letter;
int pos;
};
struct QComp {
bool operator()(const QItem &a, const QItem &b) const {
if (a.pos == b.pos) return a.letter > b.letter;
return a.pos > b.pos;
}
};
priority_queue<QItem, vector<QItem>, QComp> pq;
static int posAarrIdx[200002];
static int occInAarr[200002];
for (intz=0;x<200002;x+4){
posAarrIdx[x] = 0;
occInAarr[x]=0;
if(cVal[x]>0 L
QItem item;
item.1etter=x;
item.pos = posAarr[x][0];
pq.push(item);
}
}
static int TAlpha[200002];
for (intx=0;x<200002;x++){
if (cVal[x] > 0)TAlpha[x]=cntB[x]-cVal[x]; else TAlpha[x]=0;
}
static int freqAlpha[200002]; // freq in B up to posB0.
for (intx=0; x < 200002; x++) freqAlpha[x]=0
int posB0Alpha = -1;
{
inti=0;
for (; i < M; i++) {
int letter = B[i];
if (cVal[letter] > 0) {
freqAlpha[letter]++;
if (freqAlpha[letter] > TAlpha[letter]) {
freqAlpha[letter]--;
break; // cause posB0Alpha=i-1
}
}
}
posB0Alpha = i-1;
if (i=M) posB0Alpha=M-1;
}
vector<int> U;
U.reserve(sumC);
int posB = -1;
int usedCount = 0;
auto updatePosB0Alpha = & {
。int i = posB0Alpha + 1;
while (i < M) {
int1=B[i];
(cVal[1]>0)
freqAlpha[l]++;
if (freqAlpha[l] > TAlpha[l]) {
freqAlpha[l]--;
break;
}
}
i++;
}
posB0Alpha = i-1;
};
while (!pq.empty() && usedCount < sumC) {
QItem item = pq.top();
pq.pop();
int letter = item.letter;
int posAVal = posAarr[letter][posAarrIdx[letter]];
auto &barr = posBarr[letter];
int idx = (int) (std::lower_bound(barr.begin(), barr.end() (), barr.end(), posB + 1) - barr.begin());, posB + 1) - barr.begin()
if (idx == (int) barr.size()) {
posAarrIdx[letter]++;
if (posAarrIdx[letter] < posAarr[letter].size()) {
QItem newItem;
newItem.letter = letter;
newItem.pos = posAarr[letter][posAarrIdx[letter]];
pq.push(newItem);
}
continue;
} else {
int posBVal = barr[idx];
TAlpha[letter]++;
int oldPosB0Alpha = posB0Alpha;
vector<pair<int,int>> freqChanges;
int startIndex = posB0Alpha + 1;
int i = startIndex;
while (i<M)∈
int 1=B[i];
if(cVal[1]>0)f
freqAlpha[l]++;
freqChanges.push_back({l, i});
if (freqAlpha[l] > TAlpha[l]) {
freqAlpha[l]--;
freqChanges.pop_back();
break;
}
}
i++;
}
int newPosB0Alpha = i-1;
if (posBVal <= newPosB0Alpha) {
U.push_back(letter);
usedCount++;
posB = posBVal;
occInAarr[letter]++;
posAarrIdx[letter]++;
if (occInAarr[letter] < cVal[letter] && posAarrIdx[letter] <
posAarr[letter].size()) {
QItem newItem;
newItem.letter = letter;
newItem.pos = posAarr[letter][posAarrIdx[letter]];
pq.push(newItem);
}
posB0Alpha = newPosB0Alpha;
} else {
TAlpha[letter]--;
for (auto &fc : freqChanges) {
freqAlpha[fc.first]--;
}
posB0Alpha = oldPosB0Alpha;
posAarrIdx[letter]++;
if (posAarrIdx[letter] < posAarr[letter].size()) {
QItem newItem;
newItem.letter = letter;
newItem.pos = posAarr[letter][posAarrIdx[letter]];
pq.push(newItem);
}
continue;
}
}
}
if (usedCount < sumC) {
std::vector<int> ret;
ret.push_back(-1);
return ret;
}
return U;
}
C.4.2Submission 2
In the second submission, the model scored 10 points on subtask 3.
include "hieroglyphs.h"
include <bits/stdc++.h>
using namespace std;
std::vector<int> ucs(std::vector<int> A, std::vector<int> B)
{
int$N = ( \int t s l a t ) A . s i z e ( ) ;$
M=(∈t)B.sintze();
inta0=0,a1=0;
for (inti=0;i<N;i++){
if (A[i] == 0) a0++;
else if (A[i] == 1) a1++;
}
intb0=0,b1=0;
i=0;i<M;i++)
if (B[i]=0)bo++;
else if (B[i]⋯1) b1++;
}
intZ=min(a0,b0);
int0=min(a1,b1);
// If Z=0 and 0=0, universal subsequence is the empty sequence.
if (Zz=0&& 0==0)t
return {};
}
vector<int> zeroPosA; zeroPosA.reserve(a0);
for (inti=0;i<N;i++) if (A[i]==0) zeroPosA.push_back(i);
vector<int> zeroPosB; zeroPosB.reserve(b0);
for (inti=0;i<M; i++) if (B[i] ==0) zeroPosB.push_back(i);
vector<int> prefixOnesA(N+1, 0);
for (inti=1;i<=N;i++λ prefixOnesA[i] =prefixOnesA[i-1]+(A[i-1]=1);
vector<int> prefixOnesB(M+1, 0);
for (inti=1;i<M; i++) prefixOnesB[i]=prefixOnesB[i-1]+(B[i-1]=1)
auto getOnesAfterZero = [&](vector<int> & zeroPos, vector<int> & prefixOnes, int totalOnes,
int z) {
if (z=0) return totalOnes;
else {
if (z-1 >= (int)zeroPos.size()) return 0;11 safety
int pos = zeroPos[z-1];
int onesUsed = prefixOnes[pos+1];
int onesAfter = totalOnes - onesUsed;
return onesAfter;
}
};
vector<int> fAval(Z+1), fBval(Z+1);
for (intz=0;z<=Z;z++){
fAval[z] = getOnesAfterZero(zeroPosA, prefixOnesA, a1, z);
fBval[z] = getOnesAfterZero(zeroPosB, prefixOnesB, b1, z);
}
vector<int> cZ(Z+1);
for (intz=0;z<=Z;z++cZ[z] = min(fAval[z], fBval[z]);
vector<int> onePosA; onePosA.reserve(a1);
for (inti=0;i< N; i++) if (A[i] == 1) onePosA.push_back(i);
vector<int> onePosB; onePosB.reserve(b1);
for (inti=0;i < M; i++) if (B[i]=1) onePosB.push_back(i);
vector<int> prefixZerosA(N+1, 0);
for (int i=1;i <=N;i++)prefixZerosA[i] = prefixZerosA[i-1] + (A[i-1] == 0)
vector<int> prefixZerosB(M+1, 0);
for (inti=1;i<=M; i++) prefixZerosB[i] = prefixZerosB[i-1] + (B[i-1] == 0)
auto getZerosAfterOne = [&](vector<int> & onePos, vector<int> & prefixZeros, int
totalZeros, int w) {
if (u=0) return totalZeros;
else {
if (w-1 >= (int)onePos.size()) return 0; // safety
int pos = onePos[w-1];
int zerosUsed = prefixZeros[pos+1];
int zerosAfter = totalZeros - zerosUsed;
return zerosAfter;
}
};
vector<int> gAval(O+1), gBval(O+1);
u=0;w<=0;w++)
gAval[w] = getZerosAfterOne(onePosA, prefixZerosA, a0, w);
gBval[w] = getZerosAfterOne(onePosB, prefixZerosB, b0, w);
}
vector<int> cO(O+1);
for (intu=0;w<=0; w++) co[w]=min(gAval[w], gBval[w]);
vector<int> U;
U.reserve(Z+O)
int zUsed = 0;
intoUsed=0;
auto canPlaceZero = & {
if (zUsed >=Z) return false;
intc=cZ[zUsed+1];11constraint for the next zero in U.
int onesLeft = O - oUsed;
return onesLeft >= c;
};
auto canPlaceOne = & {
if (oUsed >=0) return false;
int c=c0[oUaed+1]; // constraint for the next one in U.
int zerosLeft = Z - zUsed;
return zerosLeft >= c;
};
for (int i = 0; i < Z+O; i++) {
bool placeZ = canPlaceZero(zUsed, oUsed);
bool placeO = canPlaceOne(zUsed, oUsed);
if (!placeZ && !placeO) {
return {-1};
} else if (placeZ && !placeO) {
U.push_back(0);
zUsed++;
} else if (!placeZ && placeO) {
U.push_back(1);
oUsed++;
} else {
int cZc = cZ[zUsed+1];
int cOc = cO[oUsed+1];
bool canPickZero = false;
bool canPickOne = false;
{
int newZUsed = zUsed + 1;
int newOUsed = oUsed;
int onesLeft = O - newOUsed;
int zerosLeft = Z - newZUsed;
bool feasible = true;
if (Z > newZUsed) { // check cZ in range [newZUsed+1..Z]
int maxZConstraint = cZ[newZUsed+1];
if (onesLeft < maxZConstraint) feasible = false;
}
if (O > newOUsed) { // check cO in range [newOUsed+1..O]
int maxOConstraint = cO[newOUsed+1];
if (zerosLeft < maxOConstraint) feasible = false;
}
canPickZero = feasible;
}
{
int newZUsed = zUsed;
int newOUsed = oUsed + 1;
int onesLeft = O - newOUsed;
int zerosLeft = Z - newZUsed;
bool feasible = true;
if (Z > newZUsed) {
int maxZConstraint = cZ[newZUsed+1];
if (onesLeft < maxZConstraint) feasible = false;
}
if (O > newOUsed) {
int maxOConstraint = cO[newOUsed+1];
if (zerosLeft < maxOConstraint) feasible = false;
}
canPickOne = feasible;
}
if (canPickZero && !canPickOne) {
U.push_back(0);
zUsed++;
} else if (!canPickZero && canPickOne) {
U.push_back(1);
oUsed++;
} else if (canPickZero && canPickOne) {
if (cZc > cOc) {
U.push_back(0);
zUsed++;
} else if (cOc > cZc) {
U.push_back(1);
oUsed++;
} else {
if ((Z - zUsed) < (O - oUsed)) {
U.push_back(0);
zUsed++;
} else {
U.push_back(1);
oUsed++;
}
}
} else {
return {-1};
}
}
}
// Validate U with constraints.
vector<int> zeroPositions, onePositions;
zeroPositions.reserve(Z);
onePositions.reserve(O);
for (int$i = 0 ; i < ( \int u , \sin i z e ( ) ; i + + ) f$
if (U[i]⋯0) zeroPositions.push_back(i);
else onePositions.push_back(i);
}
for (intz=0;z<=Z;z++λ{
int POE=(z=0)?-1: zeroPositions[z-1];
()int onesRight = (int)onePositions.size() - (int)(std::lowerbound(onePositions.begin - (int)(std::lowerbound(onePositions.begin(),()onePositions.end(), pos+1) - onePositions.begin());
if (onesRight < cZ[z]) {
return {-1};
}
}
for (intW=0;u<=0;u++λ
int pos = (w == 0) ? -1 : onePositions[w-1];
int zerosRight = (int)zeroPositions.size() -
(int)(std::lower_bound(zeroPositions.begin(), zeroPositions.end(), zeroPositions.end(), pos+1) -()zeroPositions.begin());
if (zerosRight < cO[w]) {
return {-1};
}
}
auto isSubsequence = & {
int idx=0;
for (inti=0;i<(∈t)X,sintze()&&idx<(∈t)C.sintze();i++) {
if(X[i]=C[idx])idx++;
}
return idx == (∈t)C.sintze();
};
if (!isSubsequence(U, A) || !isSubsequence(U, B)) {
return {-1};
}
return U;
} ```
C.5 Mosaic
A total of 42 points were scored on Mosaic across two separate submissions.
C.5.1 Submission 1
The frst submission achieved a score of 22 out of 100, with points distributed across subtasks 1, 2, and 4.
```
include "mosaic.h"
include <bits/stdc++.h>
using namespace std;
std::vector<long long> mosaic(std::vector<int> X, std::vector<int> Y,
std::vector<int> T, std::vector<int> B,
std::vector<int> L, std::vector<int> R)
{
intN=X.sinze();
intQ=T.sinze();
=0)
return vector<long long>(Q, 0LL);
}
// Step 1: fill A (N*N array, store as char 0/1)
vector<unsigned char> A;
$A . r e s i z e ( ( s i z e _ { - } t ) M \cdot ( s i z e _ { - } t ) N ) ;$
// fill top row
for(int j=0;j<N;j+++) {
A[0*N+j]=X[j];
}
// fill left column
for(inti=0; i<N;i++){
ADA[i*N+0]=Y[i];
}
// fill rest
for(inti=1;i<N;i++){
for(intj=1;;j<N;j++)t
A[iN+j]==(1-A[(i-1)N+j])(1-A[iN+j-1])
}
}
//Step 2: compute prefix sums in P(N+1)*(N+1) array
vector<int> P;
$P . r e s i z e ( ( s i z e _ { - } t ) ( N + 1 ) * ( s i z e _ { - } t ) ( N + 1 ) ) ;$
// initialize P with 0's
std::fill(P.beginstd::fill(P.begin(),P.end(),P.end(),0);()
for(inti=0;i<N;i++)
$\int ( 1 ) t b a s e R o w = ( i + 1 ) * ( N + 1 ) ;$
$\int p t p x e v R o w = 1 * ( N + 1 ) ;$
for(intj=0;j<N;j++){
P[baseRow+(j+1)]=P[preopaoi+(j+1)]+P[baaseRooz+j]-P[prevRovt+j]+(A[i+2i)+
j]);
}
}
// Step 3: answer queries using P
vector<long long> C;
C.resize(Q);
for(intk=0;k<0;k++) {
inttop=T[k];
int bottom=B[k];
int1eft=L[k];
$\int ( x ) d x = R [ k ] ;$
long long blackCount = (long long)P[(bottom+1)*(N+1)+(right+1)]
-(10n10n)P[(∘p)*(N+1)+(rih+1)
,(1ong 1ong)P[(bottom+1)*(N+N+1)eft]
(0n0n)P[(top)*()eft];
C[k]=b1ackCount;
}
return C;
}
C.5.2 Submission 2
The model scored 20 points in the second submission on subtasks 1,3,and 5.
include "mosaic.h"
include <bits/stdc++.h>
using namespace std;
// We'11 implement the mosaic function as specified.
std::vector<long long> mosaic(std::vector<int> X, std::vector<int> Y,
std::vector<int> T, std::vector<int> B,
std::vector<int> L, std::vector<int> R)
{
int N=X.size();
int Q=T.size();
// If N=1, the mosaic is just tile(0,0), queries are easy.
if (N=1) {
vector<long long> result(Q);
for (int q=0;q<0;$q ^ { + + } )$ {
// subrectangle T..B x L..R is always T=0,B=0,L=0,R=0 if we have queries.
if (T[q]=0&&B[q]=0&& L[q]= 0 && R[q]=0){
// black tile count is 1 ifx[0]=1orY[0]=1, andX[0]=Y[0], else 0.
// The problem states X[0] = Y[0], so tile(0,0) is black if X[0]=1.
if (X[0]⋯1)xesu1t[q]=1;elseresu1t[q]=0;
} else {
// no other queries are possible if N=1, but if they are, the subrectangle is empty or out of range.
resu1t[q]=0;
}
}
return result;
}
// Precompute prefix sums for X and Y.
vector<long long> prefixX(N+1, 0), prefixY(N+1, 0);
for (int i=1; i<=N;i++){
prefixx[i]=prefixX[i-1]+X[i-1];
prefixY[i]=prefixY[i-1]+Y[i-1];
}
// Determine alpha mod 2 and beta mod 2 from tile(1,1).
// C[1,1] = 1 if X[1] and Y[1] are 0, else 0.
intc11=0;
if (N > 1) {
if (X.size() > 1数数Y.sinize()>1 && X[1]=0 &&Y[1]=0)c11=1; else c11=0;} else {
c11=0; // but N=1 scenario is handled above.
}
int alphaMod2, betaMod2;
if (c11 ⋯1){
alphaMod2 = 0;
betaMod2=0;
} else {
alphaMod2=0;
betaMod2=1;
}
// define functions to count even and odd in a range.
auto countEvenInRange = &{
if (b<a) return 0LL;
long long A=a; long long B=b;
12-(10ng1ong)A+1)/2;
return evenCount;
};
auto countOddInRange = &{
if (b<a) return 0LL;
long long A=a; long long B=b;
long long oddCount=((10ng10ng)B+1) / 2 - (long long)A / 2;
return oddCount;
};
// Now for each query, compute the black tile count.
std::vector<long long> result(Q);
for (int q=0;q<0;q++) {
long long t=T[q];
long long b=B[q];
long long 1=L[q];
long long x=R[q]
long long count = 0;
// ifT=0, add black tile from row0 and columns L..R.
if (t=00 && x>=1) {
long long sumRow0 = prefixX[r+1] - prefixX[(int)l]; // sum of X[L..R]
count += sumRow0;
}
// if L=0, add black tile from column0 and rows T..B.
if (l⋯0 && b>=t) {
long long sumCol0 = prefixY[b+1] - prefixY[(int)t]; // sum of Y[T..B]
count += sumCol0;
}
// if T=0 andL=0, subtract tile(0,0) if black.
if (t == 0 && l=0&&x>=0 && b>=0) {
(x[0]==1)
cott-=1;
}
}
// add black tile from the interior submatrix $T ^ { \prime } = \max ( T , 1 ) . B$x$L ^ { \prime } = \max ( L , 1 ) .$.R.
int Tprime = max((int)t, 1);
int Lprime = max((int)l, 1);
if (Tprime<=b && Lprime<=x){
long long evenI = countEvenInRange(Tprime, (int)b);
long long oddI = countOddInRange(Tprime, (int)b);
long long evenJ = countEvenInRange(Lprime, (int)r);
long long oddJ = countOddInRange(Lprime, (int)r);
long long interiorCount = 0;
if (alphaMod2 == betaMod2) {
// black tile appear when i%
interiorCount = evenI evenJ+oddIoddJ;
} else {
// black tile appear when i%
interiorCount = evenI * oddJ + oddI * evenJ;
}
count += interiorCount;
}
result[q] = count;
}
return result;
} ```
C.6 Sphinx
A total of 71.5 points were scored on Sphinx across two separate submissions.
C.6.1 Submission 1
The frst submission achieved a score of 50 out of 100, with 50% partial credit earned on all subtasks.
```
include "sphinx.h"
include <bits/stdc++.h>
int perform_experiment(std::vector<int> E);
std::vector<int> find_colours(int Nx, std::vector<int> Xx, std::vector<int> Yx) {
intN=Nx;
std::vector<std::vector<int>> adj(N);
int M = Xx.size();
for (inti=0;i<M;i++)i
int u=Xx[1],v=Yx[1];
adj[u].push_back(v);
adj[v].push_back(u);
}
struct UnionFind {
std::vector<int> parent, rank;
UnionFind(int n) : parent(n), rank(n, 0) {
for (int i = 0; i < n; i++) parent[i]=i;
}
int findp(int x) {
if (parent[x] == x) return x;
parent[x] = findp(parent[x]);
return parent[x];
}
void unite(int x, int y) {
x = findp(x); y = findp(y);
if (x==y) return;
if (rank[x] < rank[y]) parent[x]=y;
else if (rank[x] > rank[y]) parent[y] = x;
else {parent[y]=x; rank[x]++;}
}
} uf(N);
auto connectedComponentsInSubset = & {
static std::vector<int> visited;
visited.assign(N, -1);
for (int v : subset) visited[v] = 0;
int count = 0;
for (int v : subset) if (visited[v]==0){
count++;
std::queue<int> q;
q.push(v);
visited[v]=1;
while(!q.empty()) {
int u=q.frontu=q.front();q⋅pop() ();
for (int w : adj[u]) {
if (visited[w]==0) {
visited[v]=1;
q.push(w);
}
}
}
}
return count;
};
auto queryMonochromComps = & {
std::vector<int> Earr(N);
static std::vector<int> visited2;
visited2.assign(N, -1);
std::vector<int> Sset(N, 0);
for (int v : S) Sset[v] = 1;
for (int i=0;i<N;i++) Earr[i] = (Sset[i] == 1) ? -1 : N;
int res = perform_experiment(Earr);
std::vector<int> compInput; compInput.reserve(N - S.size());
for (int i=0;i<N;i++) if (Sset[i]=-) compInput.push_back(i);
int compCount=0;
if (!compInput.empty()) compCount=connectedComponentsInSubset(compInput);
else compCount = 0;
int monos = res - compCount;
return monos;
};
std::vector<int> c(N+1,0);
c[0]=0;11 no vertices, #connectedComponents(0) = 0.
K=1;K<N;k++2
std::vector<int> S; S.reserve(k);
for (int i=0;i<k;i++S.push_back(i);
c[k] = queryMonochromComps(S);
}
for (intk=1;k<=k<=N;k++2t
intv=k-1;
intmerges=c[k-1]+1-c[k];
if (merges < 0) merges=0;。11safety.
auto findMerges = & -> void {
if (merges == 0) return;
if (merges == (int)roots.size()) {
for (int r : roots) {
uf.unite(v, r);
}
return;
} else {
if (roots.size() == merges) {
for (int r : roots) {
uf.unite(v, r);
}
return;
} else {
int half = roots.size()/2;
std::vector<int> left(roots.begin(), roots.begin() + half);
std::vector<int> right(roots.begin() + half, roots.end());
std::vector<int> S2; S2.reserve(1 + v);
S2.push_back(v);
for (int r : left) {
for (int i=0;i<v;i++λ{
if (uf.findp(i)=x)t
S2.push_back(i);
}
}
}
std::vector<int> Earr(N);
std::vector<int> Sset2(N, 0);
for (int i : S2) Sset2[i] = 1;
for (inti=0;i<N;i++) Earr[i]=(Sset2[i]=1)?-1:W;
int res = perform_experiment(Earr);
std::vector<int> compInput; compInput.reserve(N - S2.size());
static std::vector<int> visited2; visited2.assign(N, -1);
for (int i = 0; i < N; i++) visited2[i] = 0;
for (int i : S2) visited2[i]=-1;
compInput.clear();
for (int i=0;i<N;i++) if (visited2[i]⋯0) compInput.push_back(i);
int compCount = 0;
if (!compInput.empty()) {
for (int ip : compInput) visited2[ip]=0;// re-mark for BFS.
for (int ip : compInput) if (visited2[ip]⋯0) {
compCount++;
std::queue<int> q;
q.push(ip);
visited2[ip] = 1;
while(!q.empty()) {
int u=q.front(); q.pop();
for (int w : adj[u]) {
if (visited2[w]==0){
visited2[v]=1;
q.push(w);
}
}
}
}
} else compCount = 0;
int monos2 = res - compCount;
int mergesInLeft-1eft.sinze()+1-monoz2;
self(self, left, mergesInLeft);
self(self, right, merges - mergesInLeft);
}
}
};
std::set<int> distinctRoots;
for (int i=0;i<v;i++) distinctRoots.insert(uf.findp(i));
std::vector<int> rootsVec(distinctRoots.begin(), distinctRoots.end());
findMerges(findMerges, rootsVec, merges);
}
std::vector<int> rootID(N, -1);
std::vector<int> colorID(N, -1);
int nextID = 0;
for (inti=0;i<N;i++){
int r=uf.f∈dp(i);
if(xootID[x]=-1)
rootID[r]=nextTD++;
}
colorID[i]=rootTD[x];
}
return colorID;
}
C.6.2Submission 2
Submission 2 achieved 43 points on subtasks 1, 2, and 3.
include "sphinx.h"
include <bits/stdc++.h>
using namespace std;
int perform_experiment(vector<int> E);
vector<int> find_colours(int N, vector<int> X, vector<int> Y) {
// We’ll store adjacency.
vector<vector<int>> adj(N);
vector<vector<bool>> adjMatrix(N, vector<bool>(N, false));
for (int i = 0; i < (int)X.size();i++) {
int u = X[i];
int v = Y[i];
adj[u].push_back(v);
adj[v].push_back(u);
adjMatrix[u][v]-adjMatrix[v][u] = true;
}
vector<int> final_colors(N, -1);
vector<int> unassigned; for (int i=0;i < N; i++) unassigned.push_back(i);
// define group testing functions.
// function querycountin_T: how many in T have color x.
auto querycountin_T = & {
vector<int> E(N, x);
vector<int> inT(N, 0);
for (int v : T) {
E[v]=-1;
∈T[v]=1;
}
int R = perform_experiment(E);
// number c of connected components in the rest.
vector<int> complement;
for (int i = 0; i < N; i++) if (!inT[i]) complement.push_back(i);
// BFS for c.
vector<int> visited(N, 0);
int ccount = 0;
for (int v : complement) {
if (!visited[v]) {
ccount++;
stack<int> st;
st.push(v);
visited[v] = 1;
while (!st.empty()) {
int node = st.top(); st.pop();
for (int nb : adj[node]) {
if (!inT[nb] && !visited[nb]) {
visited[nb] = 1;
st.push(nb);
}
}
}
}
}
intc=ccoumt;
countz=(∈t)T.sinze()-(R-c);
return countx;
};
// function find vertices in T with color x.
$a u t o f \in d . v e r t i c e s _ { - 1 } \in T _ { - w i t h _ { - } c o l o r _ { - } x = [ A ]$(vector<int> T, int x) {
vector<int> result;
vector<int>S=T;
int $c o u n t = q u e r y _ c c o u n t _ { - } \in _ { - } T ( S , x ) ;$
while (count > 0) {
int1=0;intx=S.sinxe()-1;
(1<x)
intminid=(1+x)/2;
vector<∈t>Part(S.beg∈()+1,S.beg∈()+min+1);
int cpart=cquerycountin_T(part, x);
if (cpart>0) {
x=mind;
} else {
1=mind+1;
}
}
int found = S[l];
result.push_back(found);
// remove found from S.
auto it=f∈d(S,beg∈f∈d(S,beg∈(),S,end() (), found);
if(it!=S.end())S.erase(it);
$c o u n t = q u e r y _ c o u n t _ \in _ { - } T ( S , x ) ;$
}
return result;
};
auto findindependentset_heuristic = & {
vector<int> best;
// We’ll use a random approach.
for (int rep = 0; rep < 10; rep++) {
vector<int> attempt;
vector<int> local = verts;
random_shuffle(local.begin(), local.end());
for (int v : local) {
bool can = true;
for (int u : attempt) {
if (adjMatrix[u][v]) {
can = false;
break;
}
}
if (can) attempt.push_back(v);
}
if (attempt.size() > best.size()) best = attempt;
}
return best;
};
vector<int> U = unassigned;
while (!U.empty()) {
vector<int>T=findindependentset_heuristic(U);
vector<int> assignedInT;
vector<int> S = T;
while (!S.empty()) {
bool foundX = false;
for (intx=0;x<N;x++)
if (S.empty()) break;
int countx = querycountin_T(S, x);
if (countx > 0) {
vector<int> found = findverticesinTwithcolorx(S, x);
for (int v : found) {
final_colors[v]=x;
assignedInT.push_back(v);
}
for (int v : found) {
autoit=f∈d(S.beg∈(),S.end(),v);
if (it != S.end()) S.erase(it);
}
foundX=true;
}
}
if (!foundX) {
// If no color found for S, we can’t assign those vertices.
// But maybe it’s impossible.
break;
}
}
// remove T from U.
set<int> assignedSet(assignedInT.beginset<int> assignedSet(assignedInT.begin(), assignedInT.end() ());
vector<int> newU;
for (int v : U) {
if (assignedSet.find(v) == assignedSet.end()) newU.push_back(v);
U=new;
}
return final_colors;
} ```
References
[1] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan,Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
[2] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al.Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
[3] DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, et al.Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[4] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024.
[5] Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofr Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023.
[6] Leblond, R´emi and Gimeno, Felix and Altch´e, Florent and Saade, Alaa and Ruddock, Anton and Tallec, Corentin and Powell, George and Grill, Jean-Bastien and Miku la, Maciej and Lochbrun ner, Matthias and others.Alphacode 2 technical report.https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2TechReport.pdf, December 2023.Accessed: 202501-14.
[7] Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R´emi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science, 378(6624):1092–1097, 2022.
[8] Mike Mirzayanov. Codeforces rating system.https://codeforces.com/blog/entry/102, 2010.
[9] Mike Mirzayanov. Open codeforces rating system.https://codeforces.com/blog/entry/20762,2016.
[10] Mike Mirzayanov. Codeforces: Soon we will change the rating calculation for new accounts.https://codeforces.com/blog/entry/77890, 2020.
[11] OpenAI.Introducingswe-benchverifed.https://openai.com/index/introducing-swe-bench-verified/, August 2024. Accessed: 2025-01-14.
[12] OpenAI.Learningtoreasonwithllms.https://openai.com/index/learning-to-reason-with-llms/, September 2024. Accessed: 2025-01-14.
[13] OpenAI. Openai o3 system card. Technical Report, 2025.
[14] Timo Schick, Jane Dwivedi-Yu, Roberto Dess`ı, Roberta Raileanu, Maria Lomeli, Eric Hambro,Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36:68539–68551, 2023.
[15] Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, et al. Kimi k1.5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599,2025.
[16] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.