Cursor: 以每秒 1000 个 Token 的速度编辑文件
一种新的模型和推理方法,可在 1000 tokens/s 的速率下对整个文件进行高精度编辑。
当今的一些前沿模型(如 GPT-4o)在大规模编辑上表现不佳,主要问题在于懒惰、不准确以及高延迟。
在代码代理(coding agents)中,这种弱点尤为明显。需要准确编辑数百行代码时,往往需要多次调用模型,有时甚至会陷入无限循环。即使是小且隔离的编辑也同样可能出现许多错误:
https://web.archive.org/web/20240914081141o/https://ptht05hbb1ssoooe.public.blob.vercel-storage.com/sweagent.mp4
图 1:SWE-Agent 尝试进行一个简单的编辑,但连续七次都失败,最终因持续的语法错误而放弃。
最糟糕的是,现有模型在大规模编辑场景下速度过慢,容易打断程序员的工作思路。
我们专门针对一个名为fast apply的重要全文件代码编辑任务训练了一个模型。
对困难的代码编辑可以拆分为两个阶段:规划(planning)和应用(applying)。
在 Cursor 中,“规划”阶段表现为一个基于强大前沿模型的聊天界面;而“应用”阶段则应该简单且瞬时完成你对当前文件的修改。
 图 2:一个需要“应用”的变更的示例。它并不能直接简单复制粘贴,因为该修改会影响整个类的结构。
图 2:一个需要“应用”的变更的示例。它并不能直接简单复制粘贴,因为该修改会影响整个类的结构。
我们的 fast-apply 模型在准确性和速度上都超越了 GPT-4 和 GPT-4o,在准确度和延迟之间取得了 Pareto 前沿水平。我们对 70b 大小的模型使用了专门为代码编辑场景定制的speculative edits(推测式编辑)变体来进行推理,达到了约1000 tokens/s(大约 3500 字符/秒) 的速度。
相较于使用 Llama-3-70b 的普通推理,我们的做法实现了约13 倍的加速,同时较之前基于 GPT-4 的 speculative edits 部署也提升了约 9 倍。
图 3:上方是我们新的 70b 模型配合 speculative edits,下面则是 GPT-4 turbo 也配合 speculative edits。对一些更小的文件来说,速度提升通常在 4-5 倍左右。
在默认情况下,我们让语言模型在生成输出时,以当前文件、对话历史以及当前代码块为条件,生成完整的重写文件。
本文将解释我们如何训练并评估这个新模型,阐述为何要直接输出完整文件而不是使用 diff,以及介绍 speculative edits 如何实现极大的速度提升。
评估基于 Prompt 的重写
我们构建了一个由约 450 个完整文件编辑任务组成的评估集,每个文件不超过 400 行,然后使用 Claude-3 Opus 作为打分模型,对多个提示下的模型表现进行测试。
在数十个精心挑选的示例上,我们使用基于 Opus 的打分系统,发现它与我们对模型的主观评价更为一致,相比之下,GPT-4-Turbo 或 GPT-4o 打分的匹配度更低。
 图 4:用于打分准则的 Priompt 组件
图 4:用于打分准则的 Priompt 组件
这些分数可能会偏向 Claude 模型的输出,但它们与我们自身的质性评价(qualitative assessments)也一致。
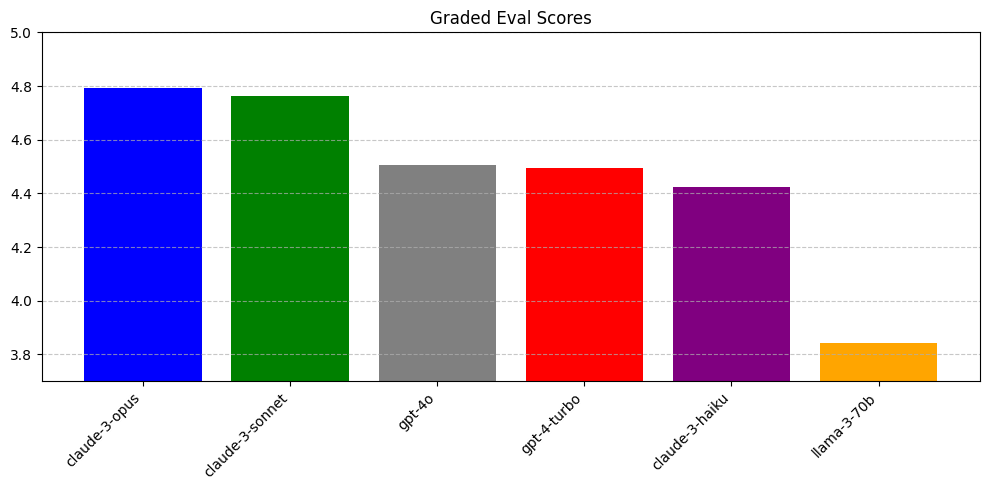 图 5:令人意外的是,claude-3-sonnet 的得分超过了 gpt-4-turbo,而 gpt-4o 的表现与 gpt-4-turbo 相近。
图 5:令人意外的是,claude-3-sonnet 的得分超过了 gpt-4-turbo,而 gpt-4o 的表现与 gpt-4-turbo 相近。
我们推测 Claude 出色的表现与后期训练有关。Claude 系列模型可以在一次回答中输出数千行代码,而 GPT-4 则倾向于省略代码并以...或注释替换一些区域。
GPT-4 表现较差的另一个原因是它常常进行不相关的修改。GPT-4 会删除被注释掉的代码或多余的空行,并倾向于对并非用户指定的部分做一些“修复/清理”。
速度测量
我们定义的速度度量方式为:
[ \text{speed} = \frac{\text{重写的字符数}}{\text{总重写耗时(秒)}} ]
这种做法有以下优势:
- 可以在不同 tokenizer 之间做归一化处理
- 给出了我们真正关心的一个单一指标(字符/秒),而无需分别统计提示(prompt)时延和生成时延
- 包含了从创建会话到完成生成的所有延迟,因此可视为生成速率的一个下界。对大多数 tokenizer 和文本而言,一个 token 往往包含 3-4 个字符,因此将字符/秒除以 4 就能得到一个保守的 tokens/s。
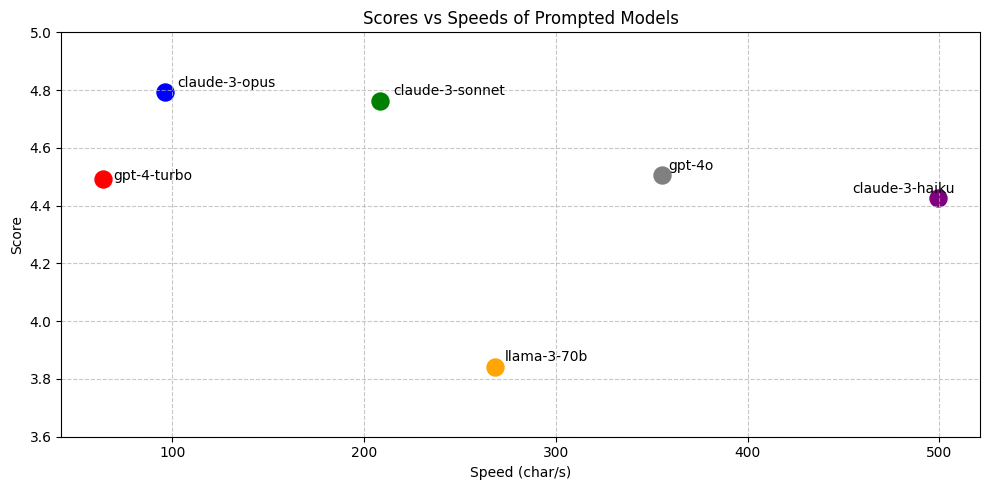 图 6:右上角代表更优。opus、sonnet、gpt-4o 和 haiku 位于 Pareto 前沿。
图 6:右上角代表更优。opus、sonnet、gpt-4o 和 haiku 位于 Pareto 前沿。
如果再加入 gpt-4-turbo 的 speculative edits 加速:
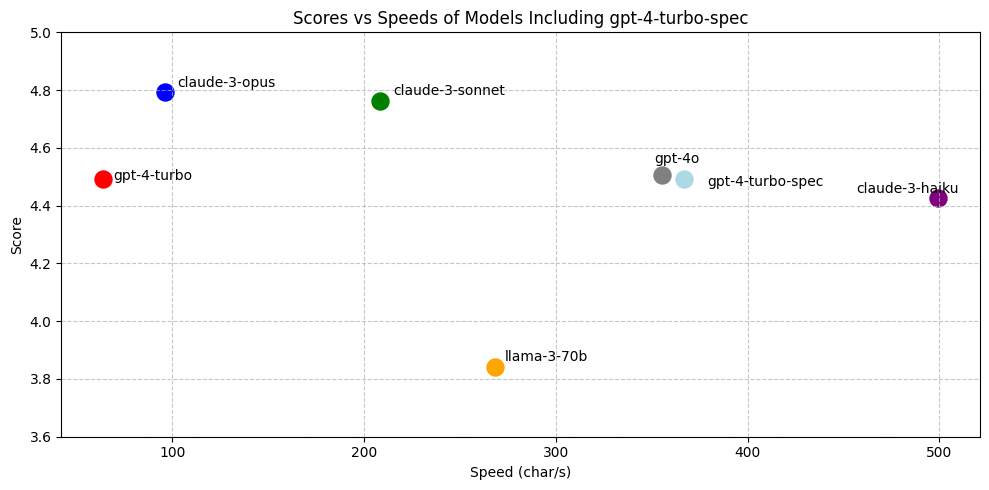 图 7:启用 speculative edits 后,gpt-4-turbo 与 gpt-4o 的表现相当。由于 gpt-4o 目前无法支持 speculative edits,否则 gpt-4o-spec 会在速度上占据领先地位。
图 7:启用 speculative edits 后,gpt-4-turbo 与 gpt-4o 的表现相当。由于 gpt-4o 目前无法支持 speculative edits,否则 gpt-4o-spec 会在速度上占据领先地位。
Diff 模型
为什么让模型重写整个文件,而不让它输出 diff?
我们发现,语言模型在处理 diff 格式时往往遇到困难,可能的原因如下:
更少的思考 Token
- 如果需要输出更多的 Token,模型实际上就有了更多前向传递机会去确定正确答案。而 diff 会强制模型在更少的 Token 内完成推理。¹
Diff 与模型已见分布差异较大
- 在预训练,尤其是后期训练(post-training)中,模型更多地见到的是完整文件形式的代码,而不是 diff 形式。
输出行号
- 如果 tokenizer 把一串数字(如 123)视为一个单独的 Token,那么模型必须在生成该单一 Token 时就“决定”正确的行号。此外,模型也常常不擅长数行号。
借鉴Aider的 diff 格式,我们可以减少行号问题:让模型在 diff 中输出类似搜索/替换块的格式,而非传统带行号的格式:
@@ ... @@
function binarySearch(arr, x) {
- let low = 0, high = arr.length - 1;
- while (low <= high) {
- let mid = Math.floor((low + high) / 2);
- if (arr[mid] === x) {
- return mid;
- }
- low += 1;
- }
- return -1;
+ let low = 0, high = arr.length - 1;
+ while (low <= high) {
+ let mid = Math.floor((low + high) / 2);
+ if (arr[mid] === x) {
+ return mid;
+ } else if (arr[mid] < x) {
+ low = mid + 1;
+ } else {
+ high = mid - 1;
+ }
+ }
+ return -1;
}
这里我们将所有以-开头的行替换为以+开头或空行,以让 diff 解析系统对少量模型失误有一定的鲁棒性。²
大多数模型在输出精确的 diff 方面都失败了,少数例外是 Claude Opus。
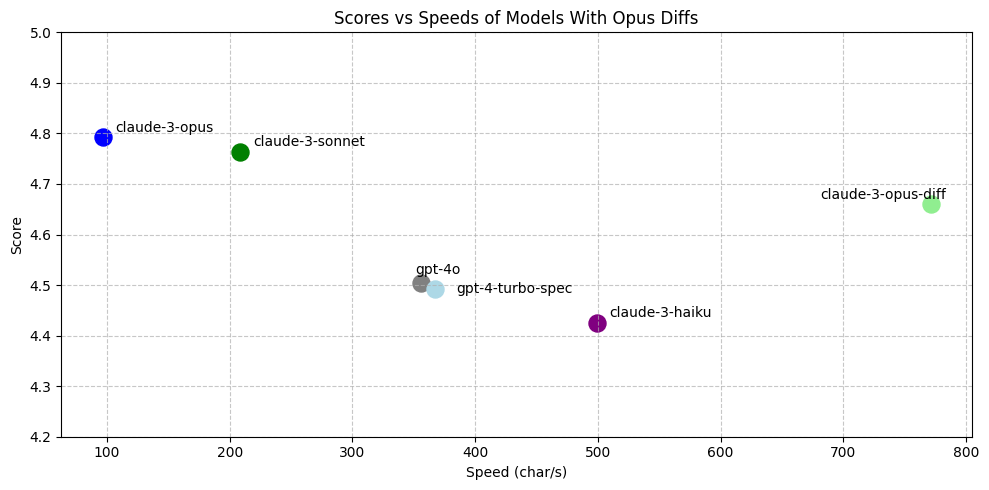 图 8:claude-3-opus-diff 是使用经过微调的 Aider diff 格式提示的 Claude Opus。它在速度和准确率上都超过了 gpt-4-turbo-spec。图中未显示 gpt-4o-diff(它的中位数速度为 2476 字符/秒,平均得分 4.18),也远不及 claude-3-haiku(4.18 的平均评估得分)。
图 8:claude-3-opus-diff 是使用经过微调的 Aider diff 格式提示的 Claude Opus。它在速度和准确率上都超过了 gpt-4-turbo-spec。图中未显示 gpt-4o-diff(它的中位数速度为 2476 字符/秒,平均得分 4.18),也远不及 claude-3-haiku(4.18 的平均评估得分)。
训练
虽然 claude-3-opus-diff 的速度和准确率都超过了 gpt-4-turbo-spec,但它依旧不够快。
由于无法在任何 Anthropic 模型上实现 speculative edits(推测式编辑),我们需要训练并部署一个高性能的自定义模型。
合成数据(Synthetic Data)
我们先收集到少量真正的“fast-apply”场景下的提示语料,以及大量cmd-k提示数据。
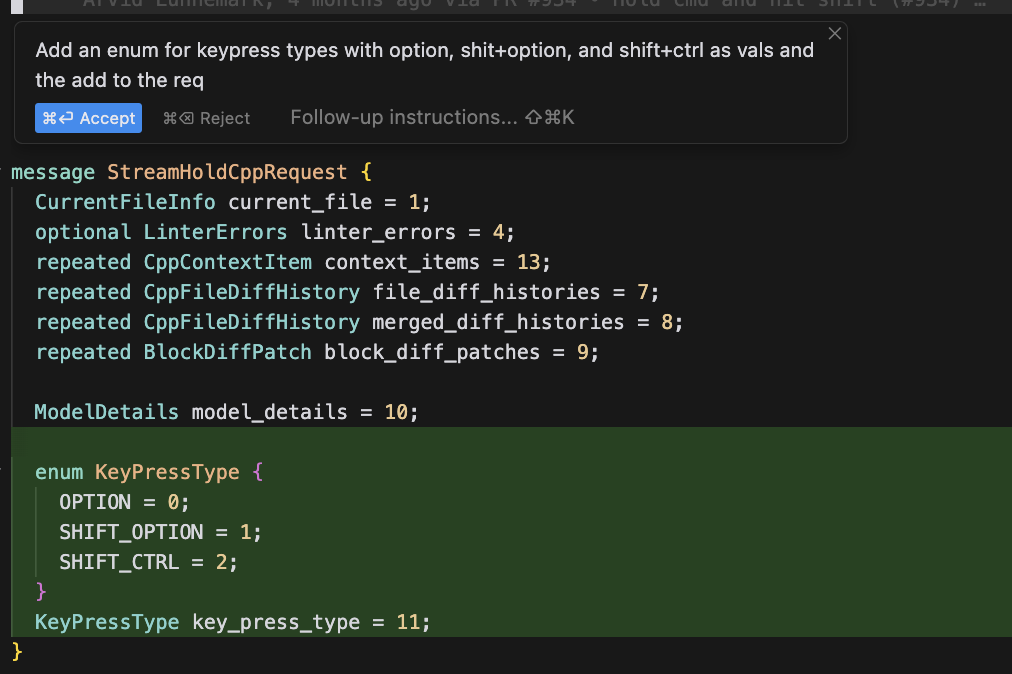 图 9:一个cmd-k提示的示例及其相应的模型生成结果。通过 cmd-k,你可以让模型只对所选区域进行编辑。
图 9:一个cmd-k提示的示例及其相应的模型生成结果。通过 cmd-k,你可以让模型只对所选区域进行编辑。
cmd-k 提示与我们在 fast-apply 需求中所需的数据形式较为接近:它包含一个编辑指令,以及当前文件的一个代码区块。
对于每个编辑指令,我们让 GPT-4 在给定当前文件的情况下生成一个聊天回复,然后再让另一个语言模型“应用”该变更。通过这种方式,我们在小规模的真实“apply”数据集上,额外生成了更多高质量的“apply”数据。最后,我们将完全合成的数据与这些衍生的高质量数据按 80/20 的比例混合得到我们的微调数据集。
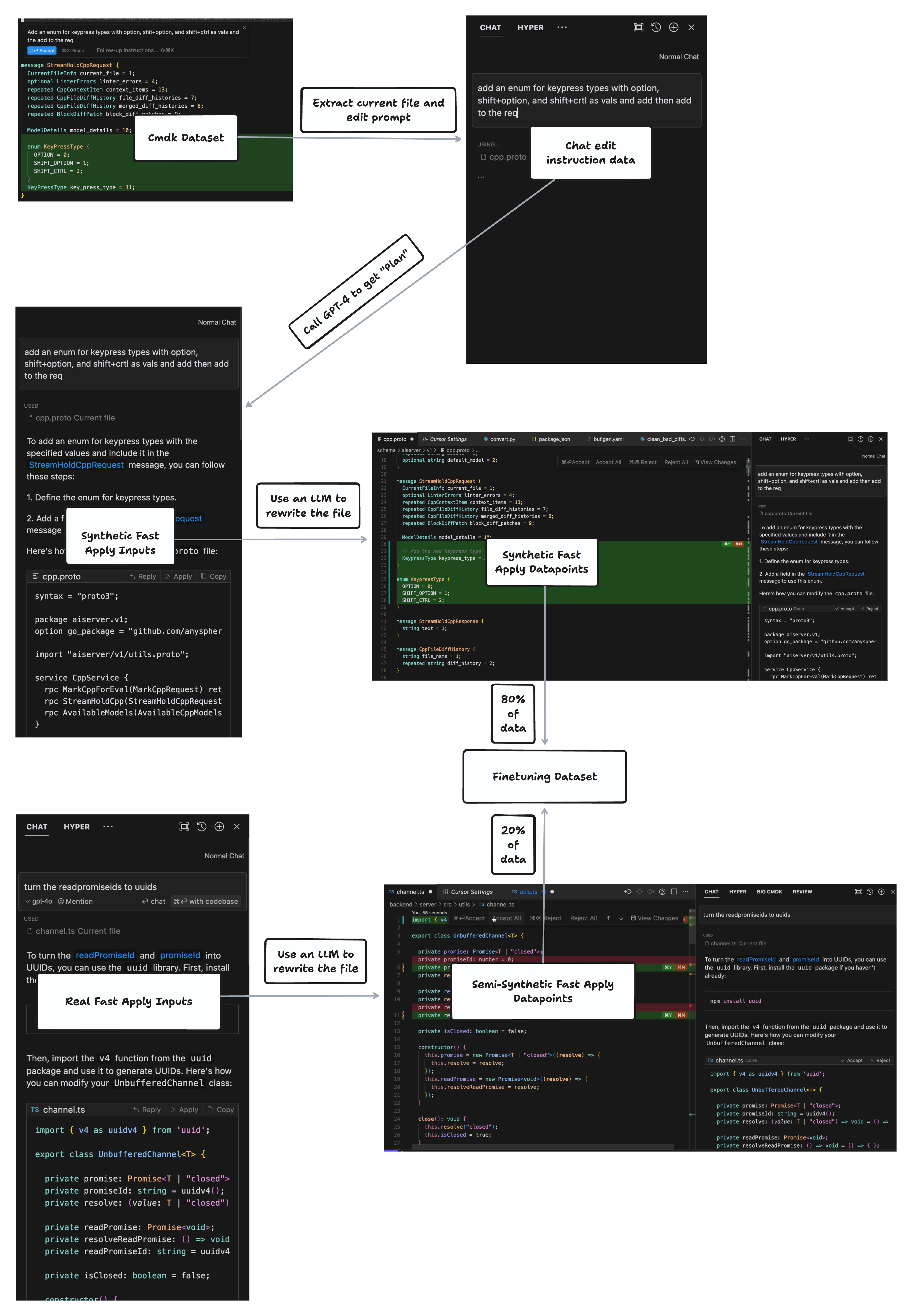 图 10:我们生成 fast-apply 微调数据集的数据管线。完全合成的数据质量较低,比如上图所示示例,所丢弃的选区(selection range)信息在真实编辑中其实很关键。
图 10:我们生成 fast-apply 微调数据集的数据管线。完全合成的数据质量较低,比如上图所示示例,所丢弃的选区(selection range)信息在真实编辑中其实很关键。
模型训练
我们在 Deepseek Coder Instruct 和 Llama 3 模型系列上进行微调。为了进一步完善训练集,我们还对数据进行了如下处理:
- 对文件行数较少(< 100 行)的样本进行降采样,以减少它们在训练集中的比例。
- 对同一文件生成的多个编辑样本也进行降采样。
- 对那些最终没进行任何修改(no-op)的数据进行降采样。³
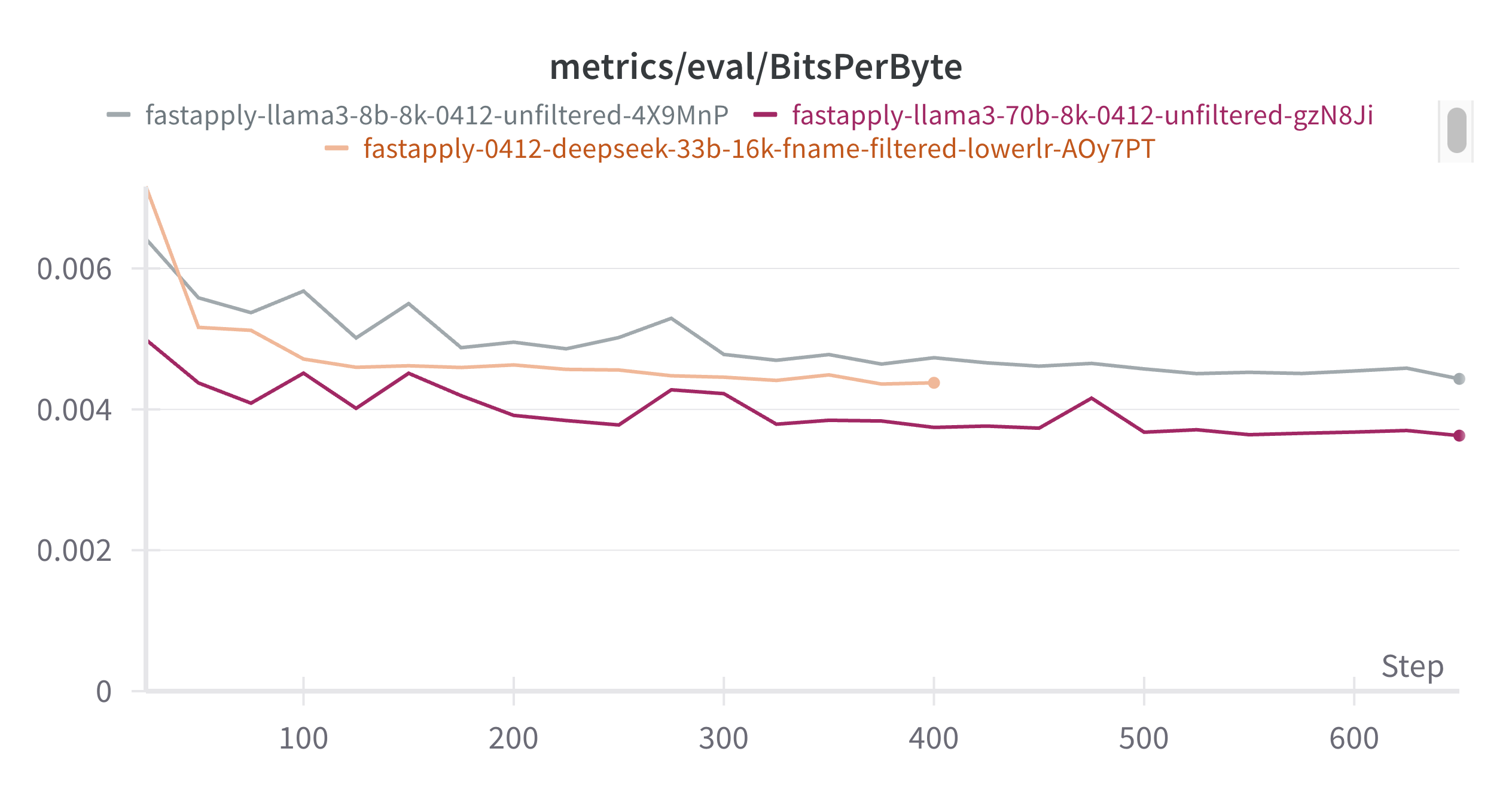 图 11:我们用 bits-per-byte(BPB)来在不同 tokenizer 之间做损失的归一化。Deepseek 模型在按文件名过滤数据上更积极。
图 11:我们用 bits-per-byte(BPB)来在不同 tokenizer 之间做损失的归一化。Deepseek 模型在按文件名过滤数据上更积极。
我们发现,最优的模型(llama-3-70b-ft)几乎可以达到或优于 claude-3-opus-diff,同时超越了 gpt-4-turbo 和 gpt-4o。
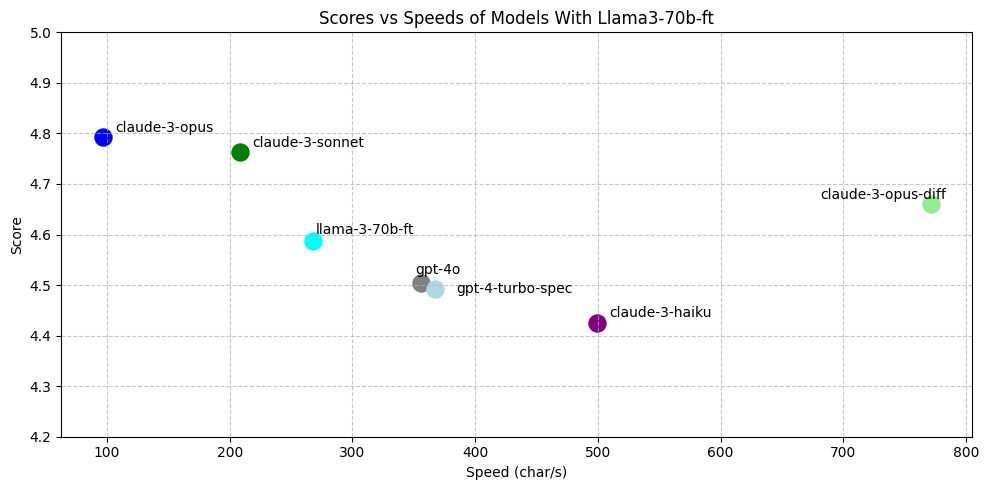 图 12:Llama-3-70b-ft 在性能上优于 gpt-4-turbo-spec
图 12:Llama-3-70b-ft 在性能上优于 gpt-4-turbo-spec
在我们的评测中,所有经过微调的模型都比 gpt-4-turbo 表现更好,但从使用感受上看,finetuned 的 deepseek-33b 和 llama-3-70b 之间还是明显有差距。⁴ llama-3-70b 感觉比其他微调模型和 gpt-4-turbo 整体更好,而其他一些微调模型则仍不够好,甚至可能不如 GPT-4。
Speculative edits(推测式编辑)
我们最大的提升来自自研的推测式解码算法 “speculative edits”。它实际上等价于一次性重写整个文件,但可带来最高 9 倍的速度提升。
在代码编辑场景中,由于对候选 Token 有较强的先验,我们可以使用一种确定性的算法(而不是一个草稿模型)来对未来 Token 进行推测。
我们与Fireworks合作,将我们的 fast-apply 模型搭配他们强大的推理引擎,并为我们定制了推测式编辑的 API 支持。
对于 Llama-3 来说,speculative edits 的速度提升比 GPT-4 更大,整体可达现有最快模型的 4-5 倍。
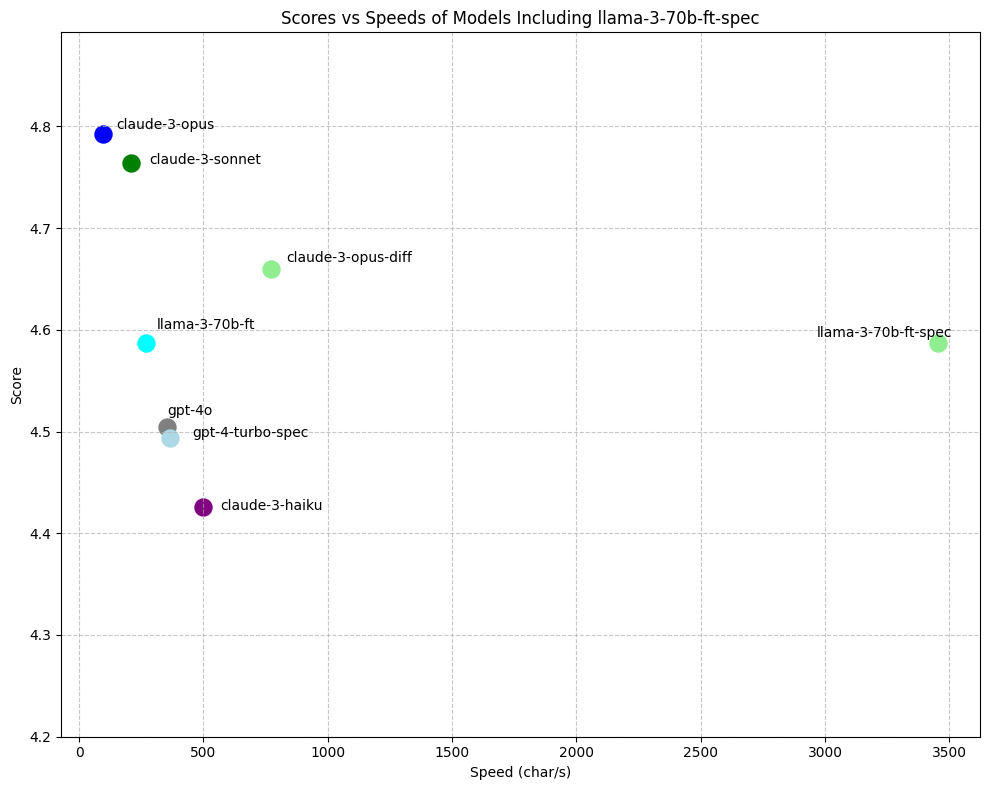 图 13:推测式编辑让我们微调后的模型获得了巨大的加速。
图 13:推测式编辑让我们微调后的模型获得了巨大的加速。
未来方向
长上下文训练我们正在研究长上下文训练,以便支持对最多 2500 行代码的文件进行重写。对 RoPE position id 进行简单的线性扩展效果并不好,当前社区对 Llama 3 70b 的长上下文微调也并不理想。
知识蒸馏我们还希望将“fast apply”能力从现有的大模型蒸馏到更小的模型(例如 llama-3-8b),因为当文件更大时,模型尺寸的减小意味着更低的推理延迟会变得更加重要。
进一步提高准确率通过在实际使用中收集数据并进行 on-policy RL(基于当前策略的强化学习),我们或许能取得更高的性能提升。
对于聊天机器人来说,fast-apply 也许只是一个小功能,但它却是构建更复杂代码生成系统的重要积木。随着模型在推理和规划上的能力不断提升,低延迟的修改应用将带来更显著的好处!
如果你还没用过,强烈推荐在Cursor体验一下这个功能!这是我们在产品中打磨深度和细节的一个小例子。
这篇博客也代表了 Anysphere 在做的应用研究的一个缩影。⁵ 我们不仅对模型进行特定任务的推理速度优化(例如 speculative edits),还会针对任务对模型进行专门的训练和评估,并最终把这些成果打包成对用户有用的功能。
我们正在招聘研究工程师和软件工程师!想了解更多信息,可以访问Anysphere。
彩蛋挑战
我们虽然概述了 speculative edits 的原理,但并没有详细解释它的完整算法。
如果你感兴趣,可以尝试在 openai 的 API 中实现 speculative edits。(提示:对于大多数 openai 账号,目前只能在 davinci-002 或 babbage-002 上实现,所以你的解决方案应该面向这些模型。)
如果想挑战更高难度,可以尝试在 vllm 中实现 speculative edits;而如果你想要难上加难,那就尝试在 TensorRT-LLM 中实现吧。
如果你实现了,欢迎通过Twitter告诉我们你的成果!我们非常期待看到你的解决方案。