在软件工程领域,随着挑战的不断演变,传统的基准测试方法显得力不从心。自由职业的软件工程工作复杂多变,远不止是孤立的编码任务。自由职业工程师需要处理整个代码库,集成多种系统,并满足复杂的客户需求。而传统的评估方法通常侧重于单元测试,无法充分反映全栈性能和解决方案的实际经济影响。因此,开发更为真实的评估方法显得尤为重要。

为此,OpenAI 推出了 SWE-Lancer,一个针对真实世界自由软件工程工作进行模型性能评估的基准测试。该基准测试基于来自 Upwork 和 Expensify 存储库的1400多个自由职业任务,总支付金额达到100万美元。这些任务从小的 bug 修复到大型功能实现应有尽有。SWE-Lancer 旨在评估个别代码补丁及管理决策,要求模型从多个选项中选择最佳提案。这种方法更好地反映了真实工程团队的双重角色。
SWE-Lancer 的一大优势在于使用端到端测试,而非孤立的单元测试。这些测试经过专业软件工程师精心设计和验证,能够模拟从问题识别、调试到补丁验证的整个用户工作流程。通过使用统一的 Docker 镜像进行评估,基准测试确保每个模型在相同的受控条件下进行测试。这种严格的测试框架有助于揭示模型解决方案是否足够稳健,适合实际部署。
SWE-Lancer 的技术细节设计巧妙,真实地反映了自由职业工作的实际情况。任务要求对多个文件进行修改,并与 API 集成,涉及移动和 Web 平台。除了生成代码补丁,模型还需要审查并选择竞争提案。这种对技术与管理技能的双重关注,体现了软件工程师的真实职责。同时,包含的用户工具模拟真实用户互动,进一步增强了评估,鼓励迭代调试和调整。
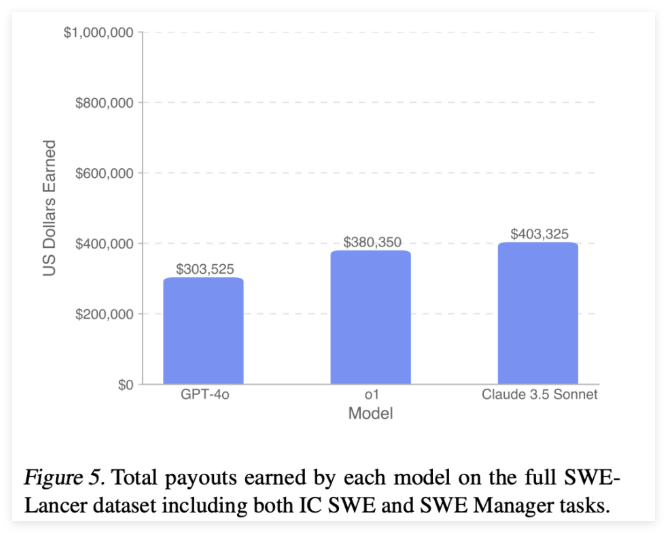
通过 SWE-Lancer 的结果,研究人员能够深入了解当前语言模型在软件工程领域的能力。在个体贡献任务中,像 GPT-4o 和 Claude3.5Sonnet 这样的模型的通过率分别为8.0% 和26.2%。而在管理任务中,表现最佳的模型达到了44.9% 的通过率。这些数据表明,尽管最先进的模型能够提供有希望的解决方案,但仍然有很大的提升空间。
论文:https://arxiv.org/abs/2502.12115
划重点:
💡 * 创新评估方法 *:SWE-Lancer 基准测试通过真实的自由职业任务,提供了更具真实性的模型性能评估。
📈 * 多维度测试 *:使用端到端测试代替单元测试,更好地反映软件工程师在真实工作中的复杂性。
🚀 * 提升潜力 *:现有模型虽然表现出色,但通过更多尝试和计算资源仍有提升的空间。