声明:本文来自于微信公众号量子位 | 公众号 QbitAI,作者:衡宇,授权Soraor转载发布。
GPT-4.5将在未来几个周/月内发布!
GPT-5也快了,且是免费用户也能无限聊的那种!
这是奥特曼刚刚在最新推文中放出的豪言。
这篇推文短短216个单词,但包含了巨大的信息量:
GPT-4.5/5将很快陆续发布,ChatGPT免费用户能享受GPT-5的无限制聊天;
几周/月内发布的GPT-4.5,是OpenAI最后一个非推理模型;
o3不会作为独立模型发布;
GPT-5起,o系列模型将和GPT系列模型集成统一;
以后使用OpenAI的模型时,模型会根据prompt自动选择调用哪个/些自家模型;
……
OpenAI官推这边也有动作,接连宣布新消息:
从现在起,所有Pro用户都可以在移动和桌面应用程序(iOS、Android、macOS 和 Windows)上使用深度研究。
从现在起,ChatGPT中选择o1和o3-mini,可上传文件和图像。
从现在起,Plus用户每天可与o3-mini-high的对话次数多了50个(提高了7倍)。
与此同时,OpenAI官网也发布了一篇博文,详细阐述了OpenAI最新版模型规范。
博文不仅“定义了我们希望AI模型的行为方式”,还分享了OpenAI按此前模型计划执行后的结果,随着时间的推移和对现实情况的观察,OpenAI对未来旗下模型版图有了改进版规划。
为了支持广泛的使用和协作,我们将在Creative Commons CC0许可下将此版本的模型规范发布到公共领域。
这意味着开发人员和研究人员可以在自己的工作中自由使用、适应和构建它。
有意思的是,第一个留言的网友直接贴脸留言:
好棒棒!
但问题摆在这儿,它能超过中国的DeepSeek不?

“We want AI to ‘just work’ for you。”
在推文中,奥特曼一上来就承认:OpenAI已经意识到自家的模型和产品供应已经变得非常复杂。
对此,OpenAI将采取一系列措施。
第一步,是在几周/月内,发布GPT-4.5,也就是此前多次曝光过的Orion(猎户座)。
奥特曼表示,这将是OpenAI的最后一个非推理模型。
前情提要,Orion从去年8月浮出水面,它的定位是OpenAI新旗舰,也就是GPT-4的下一代。
现在奥特曼也确定它就是GPT-4.5。
在此之前,Orion的最后一次消息来自去年12月月底。
当时,华尔街日报曾透露了他们掌握的信息,“最好的情况下,Orion比OpenAI目前的产品表现都要好。但与所消耗的成本相比,这种提升并不明显”。
不知就快发布的Orion会带来什么表现,搬个小板凳坐等。
第二步,不再让用户们在模型间选来选去,转而着手创建可以使用OpenAI所有工具的系统。
我们和您一样讨厌模型选择器,并希望回归魔法般的统一智能(Magic Unified Intelligence)。
具体来说,OpenAI会统一o系列模型和GPT系列模型,然后以GPT-5为始发布新系列模型们。
新系列模型被纳入「可以使用OpenAI所有工具的系统」,系统知道何时需要长时间思考或不思考,“并且通常对非常广泛的任务很有用”。
有OpenAI员工激情感慨:“很高兴能够大大简化我们的产品,让更多人都能用上AI、多用AI。”

不过,由于没有提及GPT-5的技术迭代点,有人追问道:
我可不可以理解为,GPT-5本身只是对o系列和GPT系列进行了产品包装,而不是在技术能力上有跃升?
然后,基于以上计划,o3模型将不会作为独立模型发布了。
奥特曼文中提到,在ChatGPT和OpenAI的API中,GPT-5将作为一个集成了诸多自家技术的系统发布。
这个系统中包括o3,这表明OpenAI不会将o3作为独立模型提供给外界。
(BTW,按照原本计划,微软是想在2024年年中看到GPT-5的;OpenAI是预备在今年2月或3月发布o3的)
作为新系统发布的GPT-5,其功能将包含语音、画布、搜索、深入研究等等。
得知GPT-5就要被端上桌了,网友们热切地想知道的就一件事:
GPT-4.5/5发布后,会开源不?会开源不?会开源不?

再然后,在不滥用的前提下,GPT-5预计将对所有ChatGPT免费用户开放。
他的原话是:
在标准智能设置 (!!)下,ChatGPT免费用户将获得对GPT-5的无限制聊天访问权限,但要遵守滥用阈值。
但氪金用户也不用拍大腿觉得钱给早了——
Plus用户能用上更高智能水平的GPT-5。
Pro用户能用上更更更高智能水平的GPT-5。
看完这条推文,Google AI studio的高级产品经理激情留言:
Nice!
这一直是我们对Gemini的计划,确保推理能力是基本模型的一部分,而不是支线任务。
(这也是为什么我们搞了2.0Flash Thinking)。

与此同时,OpenAI官方发布了一条博客,名为《Sharing the latest Model Spec》,内文涵盖OpenAI塑造所需模型行为的方法。
OpenAI表示,自己的目标是创建有用、安全且符合用户和开发人员需求的模型,同时推进使命,即确保AGI造福全人类。
为了实现这一目标,OpenAI需要干以下这些事,包括:
迭代和部署模型
为开发者和用户提供服务
防止模型被恶意使用造成严重伤害
维护OpenAI的运行许可
实际进程中,上述目标之间可能会发生冲突。
这就是模型规范存在的意义——通过指示模型遵循明确定义的命令链,以及为各种场景设置边界和默认行为的附加原则,以此权衡轻重利弊,最终达到平衡。
特别指出,该规范优先考虑用户和开发人员的控制,同时保持在清晰、定义明确的边界内。
定义模型如何按顺序确定来自OpenAI、开发人员和用户的指令的优先级。
模型规范的大部分内容都包含OpenAI认为在许多情况下有帮助的准则,但用户可以和开发人员覆盖这些准则。
这使用户能够和开发人员在平台级规则设置的边界内完全自定义模型行为。
就像一个高度的、完整的人类助手一样,OpenAI的模型应该使用户能够做出自己的最佳决策。
这涉及到:
(1) 避免用议程引导用户,在愿意从任何角度探索任何主题的同时保持客观性;
(2) 努力了解用户的目标,澄清假设和不确定的细节,并在适当的时候提供关键反馈。
OpenAI表示,官方已经听到并改进了这些请求。
设定能力的基本标准,包括事实准确性、创造力和编程使用。
说明模型如何平衡用户自主权与预防措施,以避免促进伤害或滥用。
这个新版本旨在全面,完全涵盖OpenAI打算让模型拒绝用户或开发人员请求的所有原因。
描述模型的默认对话风格——热情、善解人意和乐于助人——以及如何调整这种风格。
提供有关格式设置和交付的默认指导。
无论是整洁的要点、简洁的代码片段还是语音对话,OpenAI的目标都是确保清晰度和可用性。
除上述外,这份更新版的模型规范还指出明确支持知识自由、以及随时衡量模型进度。
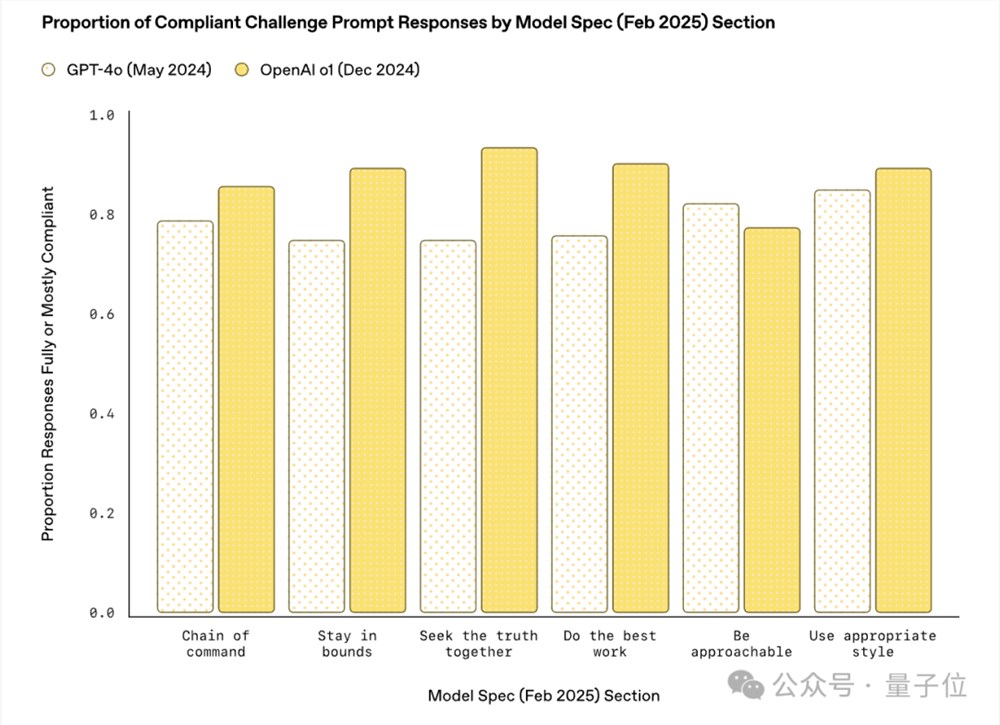
初步结果表明,与去年5月的最佳系统相比,到今天,OpenAI模型对模型规范的依从性有了显著提高。
官方认为这大概率归功于模型一致性的增强。
总的来说,博文重点有二。
一是分享对模型规范的重大更新。
在去年5月版本的基础上,加强了对于可定制性、透明度以及探索、辩论和创造人工智能的知识产权自由的承诺——同时确保保留护栏以减少真实伤害的风险。
二是分享一些早期在广泛场景下,OpenAI模型遵循模型规范原则的结果。
这主要突出了时间进展、用户需求变化、技术改进以及模型厂商可以改进的领域。
OpenAI表示,为了支持广泛的使用和协作,新版模型规范会以创造性公共领域CC0许可发布到公共领域,开发者和研究者可以自由地使用、适应并在他们自己的工作中构建它。

更详细的内容,可以参见文末博文直通车,自行查询浏览。
一夜之间,OpenAI的接连举动,很难不让人想起去年12月连续12天直播的挤牙膏行为。
有网友认为,仅“免费用户无限使用GPT-5”这件事,就能看出开源模型迎头赶超对OpenAI的压力。
当能够本地部署的免费模型如此出色时,AI公司就觉得免费为大众提供自家模型变得有必要了——毕竟人人都担心失去市场份额。
“每个人都可以免费无限制地访问GPT-5”这个想法,倒回去一年,一定让人觉得是荒谬的天方夜谭。
但,对用户来说,这是件大好事~
最后再放一个有意思的。
当奥特曼和OpenAI疯狂行动,向市场放出各种信号时,斯坦福NLP团队的官推默默转发了相关推文,并配字:
看吧,承认了!
OpenAI、Anthropic等在2023年战略,即“简单地扩大模型大小、数据、计算和花费的资金将使我们达到 AGI/ASI”,现在起不再有效!

模型规范博文:
https://openai.com/index/sharing-the-latest-model-spec/
https://model-spec.openai.com/2025-02-12.html#structure
参考链接:
[1]https://x.com/sama/status/1889755723078443244
[2]https://x.com/OpenAI/status/1889812348581634146
[3]https://x.com/OpenAI/status/1889822643676913977
[4]https://x.com/kimmonismus/status/1889773910817738872
[5]https://x.com/stanfordnlp/status/1889768783834976431
—完—