快科技2月9日消息,据媒体报道,一名图书作者对Meta提起诉讼,指控该公司未经授权下载了大量盗版电子书,用于训练其AI模型。
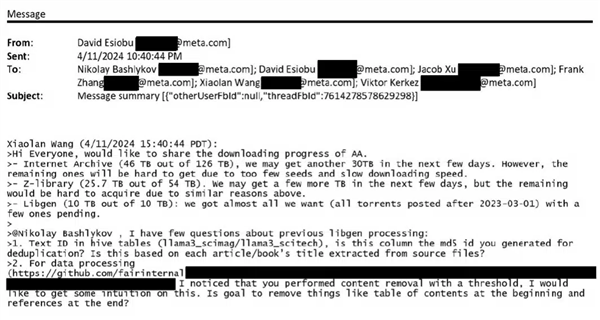
最新泄露的邮件显示,Meta承认下载了一个有争议的大型数据集LibGen,其中包括数千万本盗版书籍。
根据法庭文件,Meta通过名为安娜的档案”(Annas Archive)的渠道下载了至少81.7TB的数据,其中包括来自知名盗版网站Z-Library和LibGen的至少35.7TB的内容,Meta还被指此前从LibGen下载了额外的80.6TB数据。
作者指出,Meta的这一行为构成了非法的电子书库种子下载,且这一数字可能只是其盗版行为的冰山一角。
作者估计,这些盗版电子书库可能仅占Meta盗版版权作品总量的0.008%,这表明Meta的盗版规模可能远超目前所揭露的。
邮件还显示,Meta公司员工也意识到其行为的法律风险,2023年4月,Meta的研究工程师尼古拉巴什利科夫在邮件中表示:用公司的笔记本电脑下BT感觉不妥。”
到2023年9月,巴什科夫加大了抗议力度,并咨询了法律团队,他指出,使用Torrents意味着对文件进行播种”,即对外共享内容,这在法律上是不允许的。
但Meta仍决定继续,并试图通过将数据集下载到非Meta服务器来避免被追溯的风险。