斯坦福大学和华盛顿大学的研究团队近日联合发布了一项突破性的AI训练方法,该方法名为S1,其核心理念在于利用极简的测试时缩放技术来显著提升语言模型的推理能力。与以往依赖庞大算力或复杂算法不同,S1方法巧妙地通过控制模型在测试时的计算资源分配,实现了性能的飞跃。
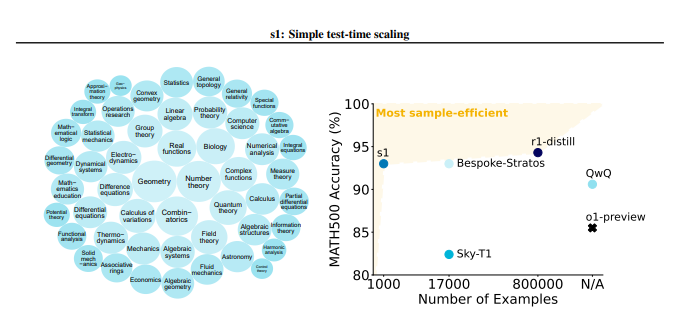
S1方法首先精心构建了一个名为s1K的小型数据集,其中包含1000个高质量的推理问题。该数据集的筛选标准非常严格,必须同时满足难度高、多样性强、质量优良三个条件。研究团队通过详尽的消融实验验证了这三个标准的重要性,结果表明,随机选择或仅关注单一标准都会导致性能大幅下降。值得一提的是,即使使用包含5.9万个样本的超集进行训练,其效果也远不如精心挑选的1000个样本,这突显了数据选择的关键性。
在模型训练完成后,研究人员采用一种名为“预算强制”的技术来控制测试时计算量。简单来说,这种方法通过强制终止模型的思考过程或添加“等待”指令来延长模型的思考时间,从而引导模型进行更深入的探索和验证。通过这种方式,模型能够反复检查推理步骤,有效纠正错误。
实验结果表明,经过在s1K数据集上的微调和“预算强制”技术的加持,s1-32B模型在竞赛级数学问题上的表现超越了OpenAI的o1-preview模型高达27%。更令人惊喜的是,通过“预算强制”进行缩放,s1-32B模型还展现出了超出自身训练水平的泛化能力,在AIME24测试集上的得分从50%提升至57%。

该研究的核心贡献在于,它提供了一套简单高效的方法,用于创建具有高推理能力的数据集,并实现测试时的性能缩放。基于此,研究团队打造了s1-32B模型,其性能完全可以媲美甚至超越闭源模型,同时做到了开源、高样本效率。该研究的代码、模型和数据已在GitHub上开源。
研究人员还对数据的细微之处以及测试时缩放技术进行了深入的消融实验。在数据方面,他们发现同时考虑难度、多样性和质量是至关重要的。在测试时缩放方面,“预算强制”方法展现出极佳的可控性和性能提升。该研究还探讨了并行缩放和顺序缩放两种不同的方法,并引入了REBASE等高级技术,为未来的研究方向提供了重要的启示。
这项研究不仅为AI训练领域带来了一种低成本、高效益的新思路,也为更广泛的AI应用奠定了坚实的基础。
论文地址:https://arxiv.org/pdf/2501.19393