近日,英伟达开源了一款名为 Sana 的图像生成模型,这一模型仅有0.6亿个参数,极大降低了运行门槛。

据了解,Sana 能够生成4096×4096分辨率的图像,并且可以在16GB 的显卡上运行,不到1秒的时间内生成1024×1024分辨率的高质量图片,这一速度在同类模型中表现突出。
研究团队引入了一种深度压缩自编码器(DC-AE),相比于传统的自编码器,Sana 的压缩比高达32倍,大大减少了潜在标记的数量,这对于生成超高分辨率图像至关重要。其次,Sana 采用了线性扩散变换器(DiT),用线性注意力取代了传统的二次注意力,从而将复杂度降低到 O (N),并通过3×3深度卷积提升了局部信息的捕捉能力。这样的设计使得 Sana 在生成4K 图像时延迟提高了1.7倍。
在文本编码方面,Sana 选择了小型的解码器专用大语言模型 Gemma,取代了传统的 T5模型。Gemma 在理解和执行复杂指令方面表现更为出色,增强了图像与文本之间的对齐能力。此外,Sana 还优化了训练和推理策略,通过自动标记和选择高 CLIP 评分的描述,提升了文本与图像的一致性。新提出的 Flow-DPM-Solver 算法将推理步骤减少到了14-20步,显著提高了性能。
综合性能方面,Sana 在多个先进的文本到图像扩散模型中表现优异。在512×512分辨率下,Sana-0.6的吞吐量是 PixArt-Σ 的5倍,并且在图像生成质量方面表现出色。而在1024×1024分辨率下,Sana-0.6B 在小于3亿参数的模型中也有着显著的优势。
Sana-0.6B 不仅性能强劲,还可以在16GB 的笔记本 GPU 上快速生成图像,助力内容创作者高效地实现创作目标。据称,Sana0.6B性能上和Flux-12B也具备竞争力,参数量只有其1/20,速度却是整整快100倍。
有趣的是,Sana提示词支持英文、中文和 emoji。用户可以输入中文诗句,生成与之相关的艺术图像。此外,Sana 还具有一定的安全性,当用户输入不当词汇时,系统会自动用红心图案❤️替代,从而避免不适内容的生成。
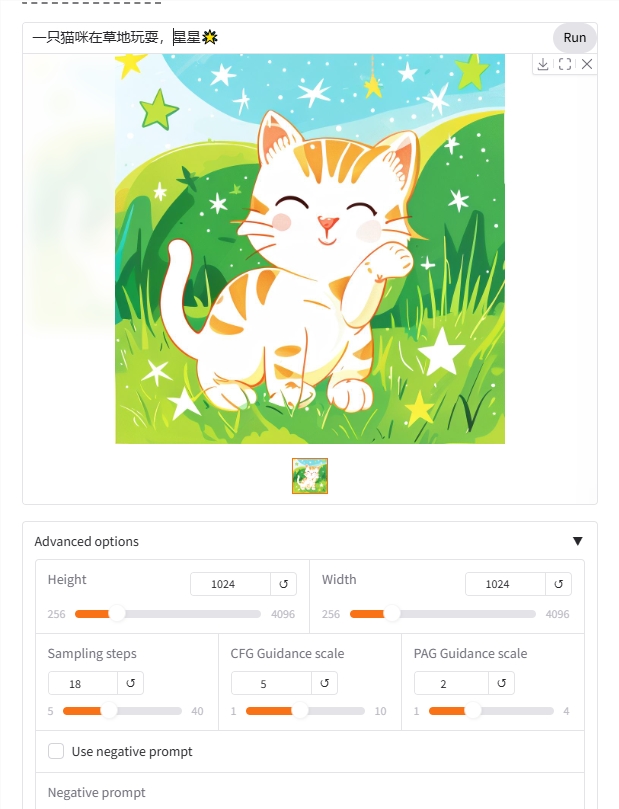
比如AIbase输入提示词“一只猫咪在草地玩耍,星星🌟”,生成速度很快,效果也特备不错。
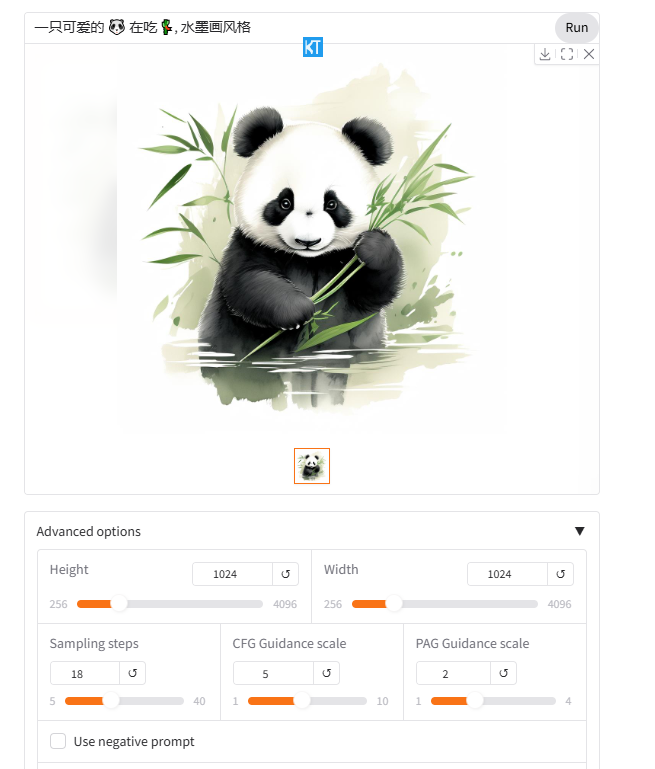
又比如给出提示词“一只可爱的 🐼 在吃 🎋, 水墨画风格”,可以看到模型能精准识别emoji。
值得一提的是,Sana 已获得官方对 ComfyUI 的支持,并配备了 Lora 训练工具。这使得用户在使用过程中更加便捷,实用性也大幅提升,感兴趣的朋友可以自己试试。
项目入口:https://nv-sana.mit.edu/
划重点:
🌟 * 高效生成 *:Sana 能够快速生成高达4096×4096分辨率的高质量图像,适合在普通笔记本 GPU 上使用。
⚙️ * 创新设计 *:深度压缩自编码器和线性扩散变换器大幅提升了生成速度和质量。
🚀 * 卓越性能 *:Sana 在多项测试中表现优异,吞吐量显著高于其他先进模型,支持快速内容创作。