AI 图像生成技术正在飞速发展,但模型体积越来越大,对普通用户来说,训练和使用成本都非常高。现在,一种名为 “Sana” 的新型文本到图像框架横空出世,它能够高效生成高达4096×4096分辨率的超高清图像,而且速度惊人,甚至可以在笔记本电脑的 GPU 上运行。

Sana 的核心设计包括:
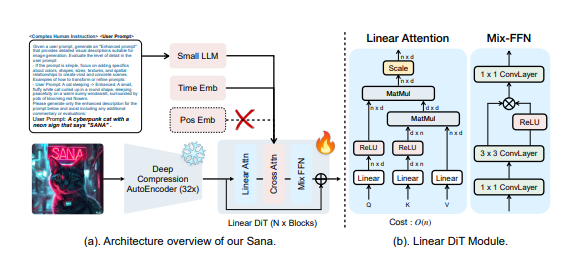
深度压缩自编码器:与传统自编码器仅压缩图像8倍不同,Sana 使用的自编码器可以将图像压缩32倍,从而有效地减少了潜在的 tokens 数量。这对于高效训练和生成超高分辨率图像至关重要。
线性 DiT:Sana 用线性注意力取代了 DiT 中的所有传统注意力机制,这在不牺牲质量的前提下,提高了高分辨率图像的处理效率。线性注意力将计算复杂度从 O(N²) 降低到 O(N)。此外,Sana 还采用了 Mix-FFN,将3x3深度卷积整合到 MLP 中,以聚合 tokens 的局部信息,并且不再需要位置编码。
解码器式文本编码器:Sana 使用了最新的解码器式小型 LLM(如 Gemma)作为文本编码器,替代了以往常用的 CLIP 或 T5。这种方式增强了模型对用户提示的理解和推理能力,并通过复杂的人工指令和上下文学习来提高图像文本的对齐度。
高效的训练和采样策略:Sana 采用了 Flow-DPM-Solver 来减少采样步骤,并使用高效的标题标注和选择方法来加速模型收敛。Sana-0.6B 模型比大型扩散模型(如 Flux-12B)小20倍,速度快100多倍。
Sana 的创新之处在于,它通过以下方法显著降低了推理延迟:
算法和系统的协同优化:通过多种优化手段,Sana 将4096x4096图像的生成时间从469秒缩短到9.6秒,比当前最先进的模型 Flux 快106倍。
深度压缩自编码器:Sana 使用 AE-F32C32P1结构,将图像压缩32倍,显著减少了 tokens 数量,加快了训练和推理速度。
线性注意力:用线性注意力取代传统的自注意力机制,提高了高分辨率图像的处理效率。
Triton 加速:使用 Triton 来融合线性注意力模块的前向和后向过程的内核,进一步加速训练和推理。
Flow-DPM-Solver:将推理采样步骤从28-50步减少到14-20步,同时获得更好的生成效果。
Sana 的性能表现非常出色。在1024x1024分辨率下,Sana-0.6B 模型的参数只有5.9亿,但整体性能却达到了0.64GenEval,与许多更大的模型相比毫不逊色。而且,Sana-0.6B 可以在16GB 笔记本电脑 GPU 上部署,生成1024×1024分辨率的图像仅需不到1秒。对于4K 图像生成,Sana-0.6B 的吞吐量比最先进的方法(FLUX)快100倍以上。Sana 不仅在速度上取得了突破,在图像质量方面也具有竞争力,即使是复杂的场景,如文字渲染和物体细节,Sana 的表现也令人满意。
此外,Sana 还具备强大的零样本语言迁移能力。即使只用英文数据进行训练,Sana 也能理解中文和表情符号的提示并生成相应的图像。
Sana 的出现,降低了高质量图像生成的门槛,为专业人士和普通用户提供了强大的内容创作工具。Sana 的代码和模型将公开发布。
体验地址:https://nv-sana.mit.edu/
论文地址:https://arxiv.org/pdf/2410.10629
Github:https://github.com/NVlabs/Sana