声明:本文来自于微信公众号AIGC开放社区,授权Soraor转载发布。
今天凌晨,微软研究院开源了目前最强小参数模型——phi-4。
去年12月12日,微软首次展示了phi-4,参数只有140亿性能却极强,在GPQA研究生水平、MATH数学基准测试中,超过了OpenAI的GPT-4o,也超过了同类顶级开源模型Qwen2.5-14B和Llama-3.3-70B。
在美国数学竞赛AMC的测试中phi-4更是达到了91.8分,超过了Gemini Pro1.5、GPT-4o、Claude3.5Sonnet、Qwen2.5等知名开闭源模型,甚至整体性能可以与4050亿参数的Llama-3.1媲美。
当时很多人就希望微软开源这款超强的小参数模型,甚至还有人在HuggingFace上传盗版的phi-4权重。现在,终于开源了,并且支持MIT许可证下商业用途。
开源地址:https://huggingface.co/microsoft/phi-4/tree/main
连HuggingFace官推都来祝贺,phi-4面子不小。
2025年美好的开始!有史以来最好的14B模型!!!

140参数的模型在MMLU获得84.8分,太疯狂了。恭喜!

谢谢你的模型和许可证变更!真棒。

你们都是英雄,赶紧下起来吧!

我期待Phi-4在Azure上实现无服务器功能。什么时候会可用?

小参数模型非常好。

Phi的小参数对于创意写作来说是非常惊人的。

哇,phi-4模型能在苹果的M4Pro笔记本上,以每秒约12个tokens的速度流畅运行,这太棒了,感谢!

phi-4简单介绍
phi-4能以如此小的参数在众多测试基准中打败著名开闭源模型,高质量的合成数据发挥了重要作用。
与传统的从网络爬取的有机数据相比,高质量的合成数据更具优势。合成数据能够提供结构化、逐步的学习材料,使得模型能够更加高效地学习语言的逻辑与推理过程。例如,在数学问题的解答中,合成数据可以按照解题步骤逐步呈现,帮助模型更好地理解问题的结构与解题思路。
此外,合成数据能够更好地与模型的推理上下文对齐,更接近于模型在实际应用中需要生成的输出格式,这有助于模型在预训练阶段就适应实际应用场景的需求。例如,将网络论坛中的事实信息改写成类似 大模型交互的风格,使得这些信息在模型生成的对话中更加自然、合理。
phi-4的合成数据生成遵循多样性、细腻性与复杂性、准确性和推理链等原则。涵盖了50多种不同类型的合成数据集,通过多阶段提示流程、种子策划、改写与增强、自我修订等多种方法,生成了约4000亿个未加权的 tokens。
除了合成数据,phi-4还对有机数据进行了严格的筛选与过滤。研究团队从网络内容、授权书籍和代码库等多渠道收集数据,并通过两阶段过滤过程,提取出具有高教育价值和推理深度的种子数据。

这些种子数据为合成数据的生成提供了基础,同时也直接用于预训练,进一步丰富了模型的知识储备。在筛选过程中,微软采用了基于小分类器的过滤方法,从大规模网络数据中挑选出高质量的文档。还针对多语言数据进行了专门的处理,确保模型能够处理包括德语、西班牙语、法语、葡萄牙语、意大利语、印地语和日语在内的多种语言。
预训练方面,phi-4主要使用合成数据进行训练,同时辅以少量的高质量有机数据。这种数据混合策略使得模型能够在学习推理和问题解决能力的同时,也能够吸收丰富的知识内容。
在中期训练阶段,phi-4将上下文长度从4096扩展到16384,以提高模型对长文本的处理能力。帮助模型进一步增加了对长文本数据的训练,包括从高质量非合成数据集中筛选出的长于8K 上下文的样本,以及新创建的满足4K 序列要求的合成数据集。
后训练阶段是 phi-4优化模型的关键。微软采用了监督微调(SFT)和直接偏好优化(DPO)技术。在 SFT 阶段,使用来自不同领域的高质量数据生成的约8B tokens对预训练模型进行微调,学习率为10-6,并添加了40种语言的多语言数据,所有数据均采用 chatml 格式。
DPO 技术则通过生成偏好数据来调整模型的输出,使其更符合人类偏好。微软还引入了关键tokens搜索(PTS)技术来生成DPO 对,该技术能够识别对模型回答正确性有重大影响的关键tokens,并针对这些tokens创建偏好数据,从而提高模型在推理任务中的性能。
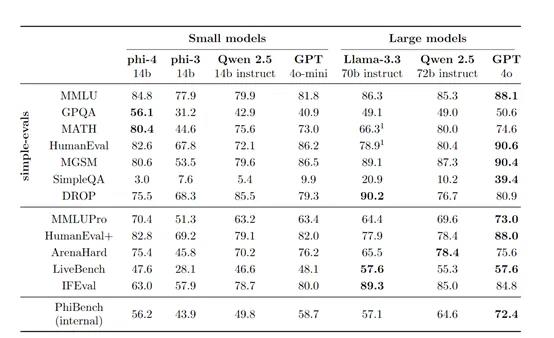
为了评估 phi-4的性能,微软在多个基准测试上进行了测试。在学术基准测试方面,如 MMLU、GPQA、MATH、HumanEval 等,phi-4表现出色。
在 MMLU测试中,phi-4取得了84.8的高分,在 GPQA 和 MATH 测试中,甚至超越了GPT -4o,在数学竞赛相关的任务中展现出强大的推理能力。在与其他类似规模和更大规模的模型比较中,phi-4在12个基准测试中的9个上优于同类开源模型 Qwen -2.5-14B - Instruct。