长期以来,如何仅凭单张图像高效生成高质量、广阔视角的3D场景一直是研究人员面临的挑战。传统方法往往依赖多视角数据,或需要耗时的逐场景优化,并且在背景质量和未见区域的重建上存在不足。现有技术在处理单视图3D场景生成时,常因信息不足而导致遮挡区域的错误或扭曲,背景模糊,以及难以推断未见区域的几何结构。而基于回归的模型虽然可以前馈方式进行新视角合成,但它们在处理复杂场景时面临巨大的内存和计算压力,因此大多局限于物体级别的生成或窄视角场景。

为了克服这些限制,研究人员推出了一项名为Wonderland的新技术。Wonderland能够仅凭单张图像,以前馈方式高效生成高质量、基于点云的3D场景表示 (3DGS)。该技术利用视频扩散模型中蕴含的丰富3D场景理解能力,并直接从视频潜在空间构建3D表示,显著降低了内存需求。3DGS通过前馈方式从视频潜在空间回归,从而显著加快了重建过程。Wonderland的关键创新点包括:
利用相机引导的视频扩散模型的生成先验知识:与图像模型不同,视频扩散模型在大量视频数据集上进行训练,捕获了场景中跨多个视角的全面空间关系,并在其潜在空间中嵌入了一种“3D感知”形式,从而可以在新视角合成中保持3D一致性。
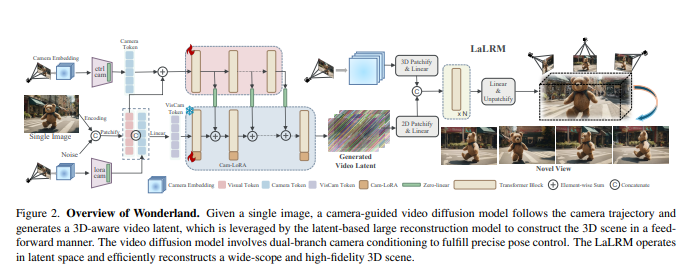
通过双分支条件机制实现精确的相机运动控制:该机制有效地将期望的各种相机轨迹整合到视频扩散模型中,使其能够将单张图像扩展为具有精确姿态控制的3D场景的多视角一致捕捉。
直接将视频潜在空间转换为3DGS以实现高效的3D重建:一种新型的基于潜在空间的大型重建模型(LaLRM)以前馈方式将视频潜在空间提升到3D。与从图像重建场景相比,视频潜在空间提供了256倍的时空压缩,同时保留了必要的、一致的3D结构细节。这种高度压缩对于使LaLRM能够在重建框架内处理更广泛的3D场景至关重要。

Wonderland通过利用视频扩散模型的生成能力,实现了高质量、广阔视角和更多样化场景的渲染,甚至可以处理超出对象级别重建的场景。其双分支相机条件策略,使视频扩散模型能够以更精确的姿态控制生成3D一致的多视角场景捕捉。在零样本新视角合成设置下,Wonderland使用单张图像作为输入进行前馈3D场景重建,其性能在多个基准数据集(如RealEstate10K,DL3DV和Tanks-and-Temples)上均优于现有方法。
Wonderland的整体流程是:首先,给定一张单张图像,一个相机引导的视频扩散模型会根据相机轨迹生成一个具有3D感知能力的视频潜在空间。然后,基于潜在空间的大型重建模型(LaLRM)以前馈方式利用该视频潜在空间构建3D场景。视频扩散模型采用双分支相机条件机制来实现精确的姿态控制。LaLRM在潜在空间中运行,并高效重建广阔且高保真的3D场景。
Wonderland的技术细节如下:
相机引导的视频潜在空间生成:为了实现精确的姿态控制,该技术使用像素级的Plücker嵌入丰富条件信息,并采用双分支条件机制,将相机信息融入到视频扩散模型中,以生成静态场景。
基于潜在空间的大型重建模型(LaLRM):该模型将视频潜在空间转换为3D高斯飞溅(3DGS),用于场景构建。LaLRM通过使用transformer架构回归高斯属性,以像素对齐的方式进行大规模重建,与图像级逐场景优化策略相比,大大降低了内存和时间成本。
渐进式训练策略:为了应对视频潜在空间和高斯飞溅之间的巨大差异,Wonderland采用渐进式训练策略,在数据源和图像分辨率方面逐步提高模型性能。
研究人员通过广泛的实验验证了Wonderland的有效性。在相机引导的视频生成方面,Wonderland在视觉质量、相机引导精度和视觉相似度方面均优于现有技术。在3D场景生成方面,Wonderland在RealEstate10K、DL3DV和Tanks-and-Temples等基准数据集上的表现也明显优于其他方法。此外,Wonderland在野外场景生成方面也展现了强大的能力。在延迟方面,Wonderland仅需5分钟即可完成场景生成,远超其他方法.
Wonderland通过在潜在空间中操作,并结合双分支相机姿态引导,不仅提高了3D重建的效率,还保证了高质量的场景生成,为单张图像生成3D场景带来了新的突破。
论文地址:https://arxiv.org/pdf/2412.12091