斯坦福大学在人工智能领域再次取得重大进展,他们最新开发的STORM&Co-STORM系统已经开源,这一系统能够通过简单的主题输入,全面整合多源信息,生成高质量的长篇文章。这一创新不仅能够避开信息盲点,还能大幅提升科研写作的效率和质量。
STORM&Co-STORM系统的核心技术包括必应搜索和GPT-4o mini的支持。STORM部分通过“LLM专家”与“LLM主持人”之间的多角度问答,迭代式地生成提纲、段落和文章。而Co-STORM则通过多智能体之间的对话生成可交互的动态思维导图,确保不遗漏用户可能未注意到的信息需求。
用户只需输入英文主题词,系统便能生成整合了多源信息的高质量长文,类似于维基百科的文章。体验STORM系统,用户可以自由选择STORM和Co-STORM模式。给定主题后,STORM能在3分钟内形成一篇结构化高质量长文。
此外,用户还可以通过点击“See BrainSTORMing Process”来查看不同LLM角色的头脑风暴过程。在“发现”栏中,用户可以参考其他学者生成的文章和聊天示例,个人生成的文章和聊天记录也可以在侧边栏“My Library”中找到。
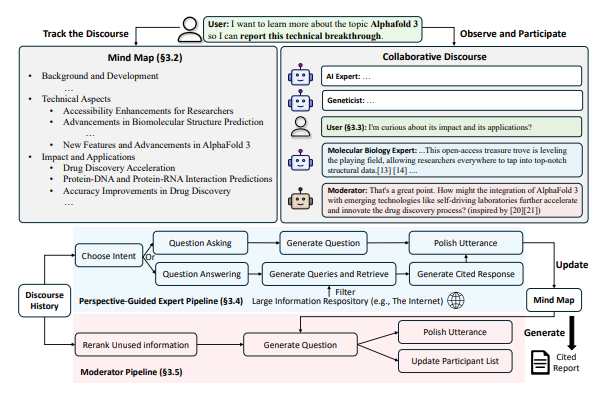
STORM系统的自动化写作流程分为三大阶段:多视角问题生成、大纲生成与完善、全文生成。系统通过查阅相关的维基百科文章来确定涵盖该主题的各种视角,然后模拟一场对话,一方是维基百科撰写者,另一方是基于可靠网络来源的专家。根据LLM的固有知识,从不同视角收集到的对话内容,最终精心编排写作大纲。
尽管STORM在研究给定主题时发现了不同的视角,但收集的信息可能仍然倾向于互联网的主流来源,并可能包含促销内容。研究的另一个局限性是,尽管研究者专注于从零开始生成类似维基百科文章,但他们也仅考虑生成自由组织的文本。而人工撰写的高质量维基百科文章通常包含结构化数据和多模态信息。
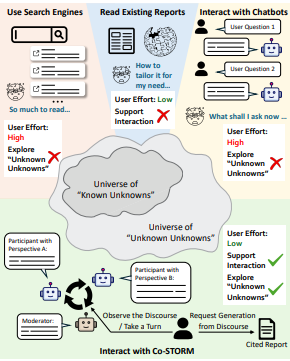
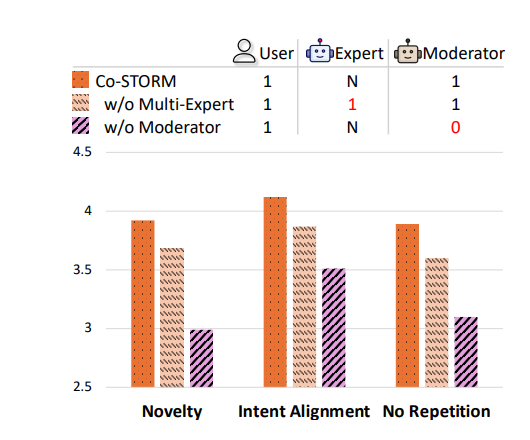
Co-STORM旨在改善信息搜集整合中的信息遗漏问题,以大幅促进学习效率。它通过多智能体协作对话、动态思维导图和报告生成模块,帮助用户理解和参与信息的组织。研究者对20名志愿者进行了人类评估,比较了Co-STORM与传统搜索引擎和RAG Chatbot的表现。结果显示,Co-STORM显著提升了信息的深度和广度,70%的用户更喜欢Co-STORM,认为其显著减少了认知负担。
目前,STORM&Co-STORM系统仅支持英语交互,未来可能会扩展至多语言交互能力。这一系统的开源,标志着我们正生活在一个信息获取方式可以完全根据个人水平量身定制的非凡时代,让学习任何东西都成为可能。
论文地址:https://www.arxiv.org/pdf/2408.15232