在一篇聚焦医疗AI评测的研究论文中,微软似乎再次"不经意"地披露了业界多个顶级大语言模型的参数规模。这份发布于12月26日的论文不仅揭示了包括OpenAI、Anthropic在内的多家公司的模型参数数据,还引发了业内对模型架构和技术实力的热议。
根据论文披露,OpenAI的o1-preview模型约有300B参数,GPT-4o约200B,而GPT-4o-mini仅有8B参数。这与英伟达今年初公布的GPT-4采用1.76T MoE架构的说法形成鲜明对比。同时,论文还透露了Claude3.5Sonnet的参数规模约为175B。

这已经不是微软第一次在论文中"泄露"模型参数信息。去年10月,微软曾在一篇论文中披露GPT-3.5-Turbo的20B参数规模,随后又在更新版本中删除了这一信息。这种反复出现的"泄露"让业内人士对其是否存在某种特定意图产生猜测。
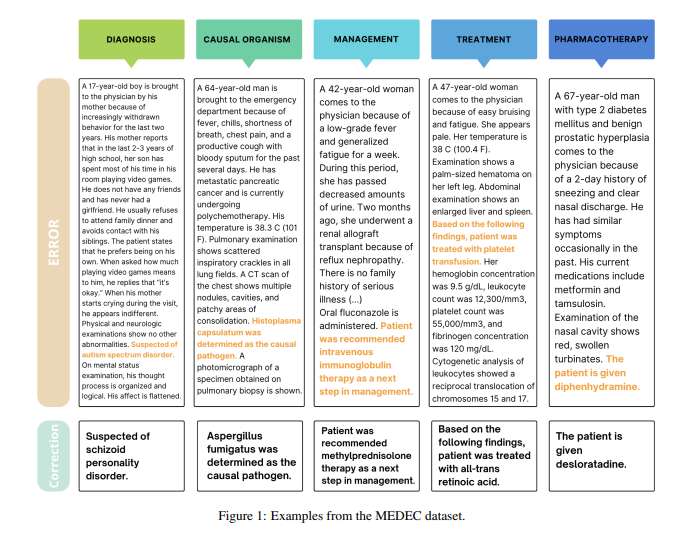
值得注意的是,这篇论文的主要目的是介绍一个名为MEDEC的医疗领域基准测试。研究团队分析了来自三家美国医院的488份临床笔记,评估了各大模型在识别和纠正医疗文档错误方面的能力。测试结果显示,Claude3.5Sonnet在错误检测方面以70.16的得分领先其他模型。
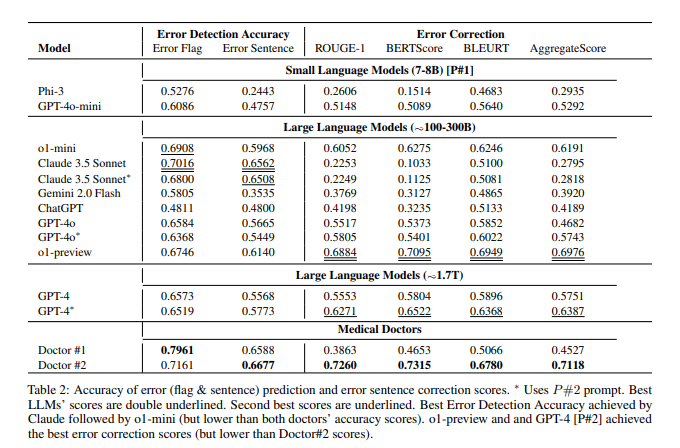
业内对这些数据的真实性展开了热烈讨论。有观点认为,如果Claude3.5Sonnet确实以更小的参数量达到优秀性能,这将凸显Anthropic的技术实力。也有分析人士通过模型定价反推,认为部分参数估计具有合理性。
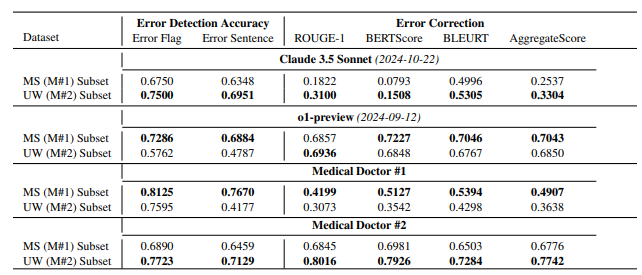
特别引人注意的是,论文仅对主流模型参数进行估计,却独独没有提及谷歌Gemini的具体参数。有分析认为,这可能与Gemini使用TPU而非英伟达GPU有关,导致难以通过token生成速度进行准确估算。
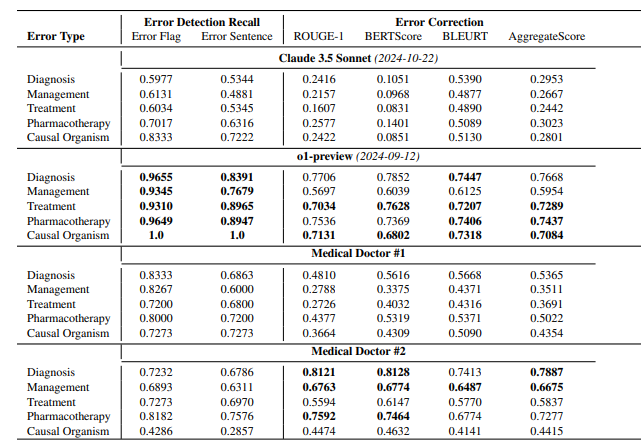
随着OpenAI逐渐淡化开源承诺,模型参数等核心信息可能会继续成为业界持续关注的焦点。这场意外泄露再次引发了人们对AI模型架构、技术路线以及商业竞争的深入思考。
参考资料:
https://arxiv.org/pdf/2412.19260
https://x.com/Yuchenj_UW/status/1874507299303379428
https://www.reddit.com/r/LocalLLaMA/comments/1f1vpyt/whygpt4ominiisprobablyaround8bactive/