英伟达在GB200和B200发布仅6个月后,再次推出全新GPU——GB300和B300。这看似只是小幅升级,实则蕴含着巨大的变革,尤其是推理模型性能的显著提升,将给整个行业带来深远的影响。
B300/GB300:推理性能的巨大飞跃
B300GPU采用台积电4NP工艺节点,针对计算芯片进行了优化设计。这使得B300的FLOPS性能比B200提升了50%。部分性能提升来自TDP的增加,GB300和B300HGX的TDP分别达到1.4KW和1.2KW(GB200和B200分别为1.2KW和1KW)。其余的性能提升则来自架构增强和系统级优化,例如CPU和GPU之间的动态功率分配。

除了FLOPS的提升,内存也升级为12-Hi HBM3E,每个GPU的HBM容量增加到288GB。然而,引脚速度保持不变,因此每个GPU的内存带宽仍为8TB/s。值得注意的是,三星未能进入GB200或GB300的供应链。
此外,英伟达在定价方面也做出了调整。这将在一定程度上影响Blackwell产品的利润率,但更重要的是,B300/GB300的性能提升将主要体现在推理模型方面。
为推理模型量身打造
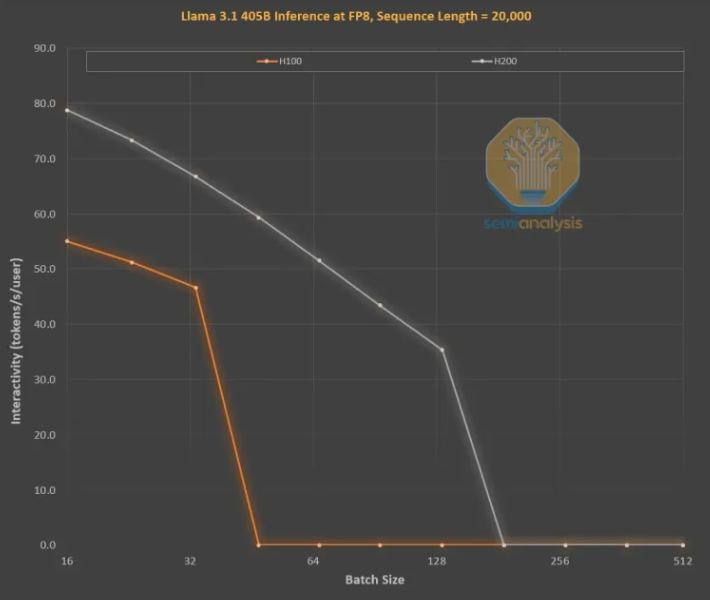
内存的改进对于OpenAI O3风格的LLM推理训练至关重要,因为长序列会增加KVCache,从而限制关键批处理大小和延迟。从H100到H200的升级(主要是内存的增加),带来了以下两方面的改进:
更高的内存带宽(H200为4.8TB/s,H100为3.35TB/s)使得所有可比较的批处理大小的交互性普遍提高了43%。
由于H200运行的批处理大小比H100更大,每秒生成的token数增加了3倍,成本降低了约3倍。这种差异主要是由于KVCache限制了总批处理大小。
更大的内存容量对性能的提升是巨大的。两款GPU之间的性能和经济差异远大于其参数规格所显示的:
推理模型的用户体验可能较差,因为请求和响应之间存在明显的等待时间。如果能够显著加快推理时间,将提高用户的使用意愿和付费意愿。
硬件通过中代内存升级实现3倍的性能提升是惊人的,远超摩尔定律、黄氏定律或我们所见过的任何其他硬件改进速度。
最强大的模型能够收取比性能稍差的模型高得多的溢价。前沿模型的毛利率超过70%,而开源竞争的落后模型的利润率则低于20%。推理模型不必只进行一个链式思考。搜索功能可以扩展来提高性能,就像在O1Pro和O3中所做的那样。这使得更智能的模型能够解决更多问题,并为每个GPU产生更多的收入。
当然,英伟达并非唯一可以增加内存容量的公司。ASIC也可以做到这一点,事实上,AMD可能处于更有利的地位,因为其MI300X、MI325X和MI350X的内存容量通常比英伟达更高,分别为192GB、256GB和288GB,但英伟达拥有名为NVLink的秘密武器。
NVL72的重要性在于,它允许72个GPU在同一问题上协同工作,共享内存,且延迟极低。世界上没有其他加速器具有全互连的交换能力。
英伟达的GB200NVL72和GB300NVL72对于实现许多关键功能至关重要:
更高的交互性,降低了每个思维链的延迟。
72个GPU可以分散KVCache,从而实现更长的思维链(提高智能)。
批处理大小的可扩展性比典型的8GPU服务器好得多,从而降低了成本。
在同一问题上工作以提高准确性和模型性能的样本量更多。
因此,NVL72的tokenomics提高了10倍以上,尤其是在长推理链上。KVCache占用内存对经济效益是致命的,但NVL72是唯一将推理长度扩展到10万个以上token的方法。
GB300:供应链重塑
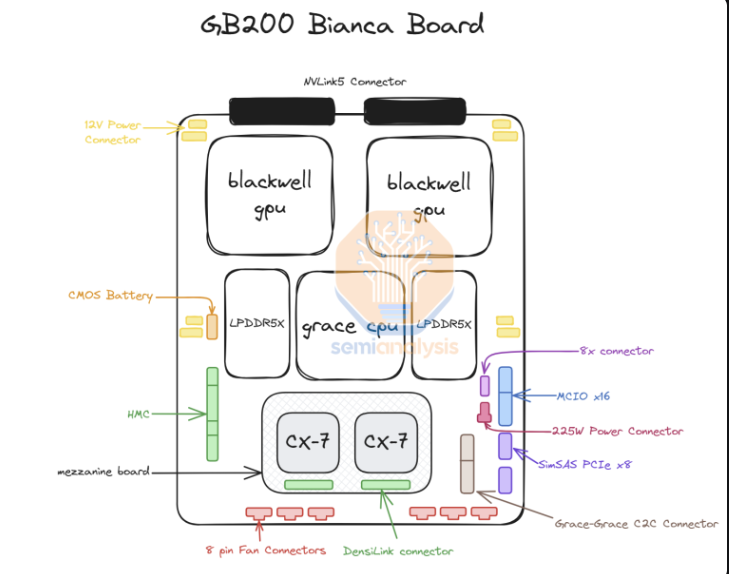
对于GB300,英伟达提供的供应链和内容发生了巨大变化。对于GB200,英伟达提供整个Bianca板(包括Blackwell GPU、Grace CPU、512GB LPDDR5X、VRM内容),以及交换托盘和铜背板。
对于GB300,英伟达只提供“SXM Puck”模块上的B300、BGA封装的Grace CPU,以及HMC,后者将来自美国初创公司Axiado,而不是GB200的Aspeed。终端客户现在将直接采购计算板上的剩余组件,第二层内存将使用LPCAMM模块,而不是焊接的LPDDR5X。美光将成为这些模块的主要供应商。交换托盘和铜背板保持不变,英伟达完全供应这些组件。
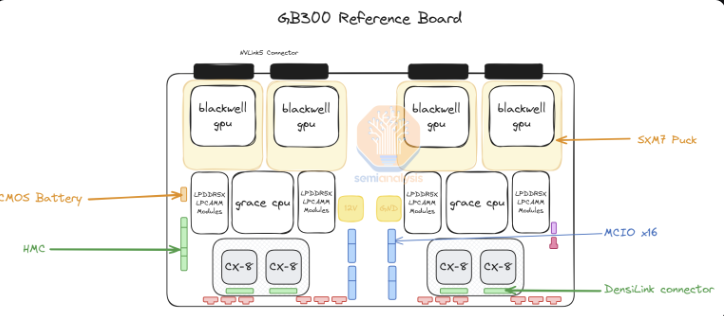
转向SXM Puck为更多OEM和ODM参与计算托盘提供了机会。以前只有纬创和富士康可以制造Bianca计算板,而现在更多的OEM和ODM可以参与其中。纬创是ODM形式的最大输家,因为他们失去了Bianca板的份额。对于富士康来说,Bianca板份额的损失被他们是SXM Puck和SXM Puck的插槽的独家制造商这一事实所抵消。英伟达正试图为Puck和插槽引入其他供应商,但尚未下达任何其他订单。
另一个重大变化是VRM内容。虽然SXM Puck上有一些VRM内容,但大部分板载VRM内容将由超大规模公司/OEM直接从VRM供应商处采购。由于业务模式的转变,Monolithic Power Systems将会失去市场份额。
英伟达还在GB300平台上提供800G ConnectX-8NIC,在InfiniBand和以太网上提供双倍的扩展带宽。英伟达之前由于上市时间复杂性和在Bianca板上放弃启用PCIe Gen6而取消了GB200的ConnectX-8。
ConnectX-8与ConnectX-7相比有了巨大的改进。它不仅具有2倍的带宽,还具有48个PCIe通道,而不是32个PCIe通道,从而实现了独特的架构,例如风冷式MGX B300A。此外,ConnectX-8具有SpectrumX能力,而在之前的400G产品中,SpectrumX需要效率较低的Bluefield3DPU。
GB300对超大规模公司影响
GB200和GB300的延迟对超大规模公司的影响意味着,许多从Q3开始的订单将转移到英伟达新的、更昂贵的GPU上。截至上周,所有超大规模公司都决定采用GB300。部分原因是GB300的性能更高,但也有一部分原因是由于他们能够掌控自己的命运。
由于上市时间挑战以及机架、冷却和电源供应/密度的重大变化,超大规模公司不允许在服务器级别对GB200进行过多更改。这导致Meta放弃了从博通和英伟达多来源NIC的希望,转而完全依赖英伟达。在其他情况下,如谷歌,他们放弃了内部NIC,转而只使用英伟达。
对于超大规模公司中习惯于优化从CPU到网络,再到螺丝和金属板的所有成本的数千人组织来说,这简直是不可思议的。
最令人震惊的例子是亚马逊,他们选择了一种非常不理想的配置,其TCO比参考设计更差。亚马逊由于使用PCIe交换机和效率较低的200G弹性光纤适配器NIC,需要风冷,因此无法像Meta、谷歌、微软、Oracle、X.AI和Coreweave那样部署NVL72机架。由于其内部NIC,亚马逊不得不使用NVL36,由于更高的背板和交换机内容,每个GPU的成本也更高。总而言之,由于其围绕定制的限制,亚马逊的配置并不理想。
现在有了GB300,超大规模公司可以定制主板、冷却等更多组件。这使得亚马逊能够构建自己的定制主板,该主板采用水冷,并集成了以前风冷的组件,如Astera Labs PCIe交换机。随着更多组件采用水冷,以及在25年第三季度终于在K2V6400G NIC上实现HVM,这意味着亚马逊可以回归NVL72架构,并大大提高其TCO。
虽然超大规模公司必须设计、验证和确认更多内容,这是最大的缺点。这很容易成为超大规模公司有史以来必须设计的最复杂的平台(谷歌的TPU系统除外)。某些超大规模公司将能够快速设计,但其他团队速度较慢的公司则落后。尽管市场报告有取消情况,但我们认为微软由于设计速度较慢,是部署GB300最慢的公司之一,他们仍在第四季度购买一些GB200。
客户支付的总价格差异很大,因为组件从英伟达的利润堆叠中被提取出来,转移到ODM。ODM的收入受到影响,最重要的是,英伟达的毛利率也会在全年发生变化。
参考资料:https://semianalysis.com/2024/12/25/nvidias-christmas-present-gb300-b300-reasoning-inference-amazon-memory-supply-chain/