在人工智能的浩瀚宇宙中,数学曾被视为机器智能最后的堡垒。如今,一个名为FrontierMath的全新基准测试横空出世,将AI的数学推理能力推向了前所未有的极限。
Epoch AI携手60多位数学界顶级大脑,共同打造了这个堪称"数学奥林匹克"的AI挑战场。这不仅仅是一次技术测试,更是对人工智能数学智慧的终极拷问。
想象一个充满了世界顶级数学家的实验室,他们精心设计出数百道超越常人想象的数学难题。这些问题横跨数论、实分析、代数几何和范畴论等最前沿的数学领域,复杂程度令人咋舌。即便是拥有国际数学奥林匹克金牌的数学天才,也需要耗费数小时甚至数天才能解决一道题目。
令人震惊的是,当前最先进的AI模型在这个基准测试中的表现令人失望:没有任何模型能够解决超过2%的题目。这个结果如同一记当头棒喝,狠狠地抽了AI的"脸"。
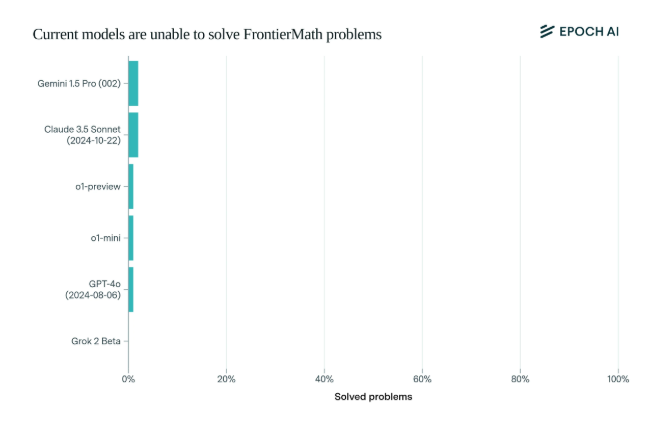
FrontierMath的独特之处在于其严苛的评测机制。传统的数学测试基准如MATH和GSM8K已经被AI"刷爆",而这个新基准通过全新、未发表的问题和自动化验证系统,有效避免了数据污染,真正考验AI的数学推理能力。
备受关注的OpenAI、Anthropic、Google DeepMind等顶级AI公司的旗舰模型在这个测试中集体"翻车"。这背后折射出一个深刻的技术哲学:对于计算机而言,看似复杂的数学问题可能轻而易举,而人类觉得简单的任务却可能令AI束手无策。
正如Andrej Karpathy所言,这正印证了莫拉维克悖论:人类与机器在智能任务上的难易程度常常是反直觉的。这个基准测试不仅是对AI能力的严格审视,更是推动人工智能向更高维度进化的催化剂。
对于数学界和AI研究者来说,FrontierMath就像是一座未被征服的珠穆朗玛峰。它不仅仅测试知识和技巧,更考验洞察力和创造性思维。未来,谁能率先攀登这座智能的高峰,谁就将载入人工智能发展的史册。