最近,社交媒体平台 Bluesky 面临了一次重大的数据抓取事件。一位机器学习图书管理员丹尼尔・范斯特林(Daniel van Strien)从 Bluesky 的 API 接口上抓取了超过一百万条公开的用户帖子,并将这些数据上传至 AI 公司 Hugging Face。

该数据集包含了用户的去中心化标识符(DID)以及一系列可以搜索特定用户内容的功能。范斯特林表示,这个数据集的主要目的是用于语言模型和自然语言处理的开发,此外还包括社交媒体趋势分析、内容审核及发布模式的研究。
这项数据抓取行动引发了广泛关注,因为 Bluesky 的用户并未同意将其内容用于此类用途。虽然平台并没有明确禁止这种行为,但它的火灾 API 提供了一个 “聚合的、按时间顺序排列的公共数据流”,包括帖子、点赞、关注、账号变更等信息。因此,Bluesky 的内容在理论上是对第三方开发者开放的。
对此,Bluesky 的一位代表表示:“Bluesky 是一个开放和公共的社交网络,就像互联网上的其他网站一样。
虽然 robots.txt 文件并不能总是阻止外部公司抓取这些网站,但情况是类似的。我们希望能够找到一种方式,让 Bluesky 用户可以向外部组织 / 开发者传达他们是否同意使用其数据,并希望外部组织尊重用户的同意,我们正在积极讨论如何实现这一目标。”
这起事件引起了用户的担忧,特别是许多用户是因竞争平台 X 的新 AI 训练政策而转投 Bluesky 的。值得注意的是,在该报道发布后不久,范斯特林从 Hugging Face 上删除了这个数据集。
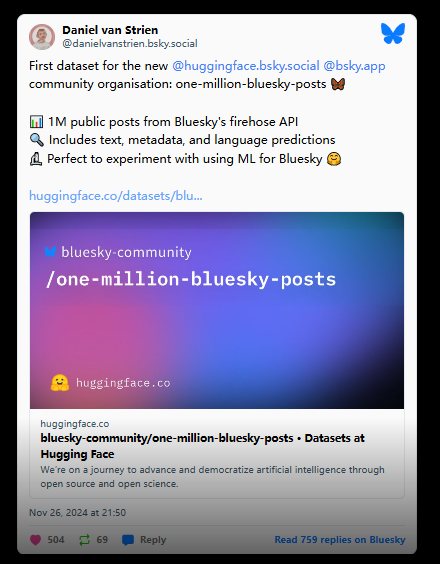
他在 Bluesky 上表示:“我已从该仓库中删除 Bluesky 数据。虽然我想支持该平台的工具开发,但我意识到这种做法违反了数据收集中的透明度和同意原则。对此,我深感抱歉。”
划重点:
🌐1. 一位机器学习专家抓取了一百万条 Bluesky 的公开帖子,并上传至 AI 公司 Hugging Face,目的是用于机器学习研究。
🔍2. Bluesky 的用户未曾同意使用其数据,平台也并未明确禁止此类数据抓取行为。
🚫3. 数据抓取事件引发用户担忧,范斯特林已将相关数据从 Hugging Face 删除,并对此表示歉意。