在人工智能迅速发展的时代,大型模型的智能化水平不断提升,但随之而来的推理系统效率挑战也越来越明显。如何应对高推理负载、降低推理成本、缩短响应时间,已成为业界共同面对的重要问题。
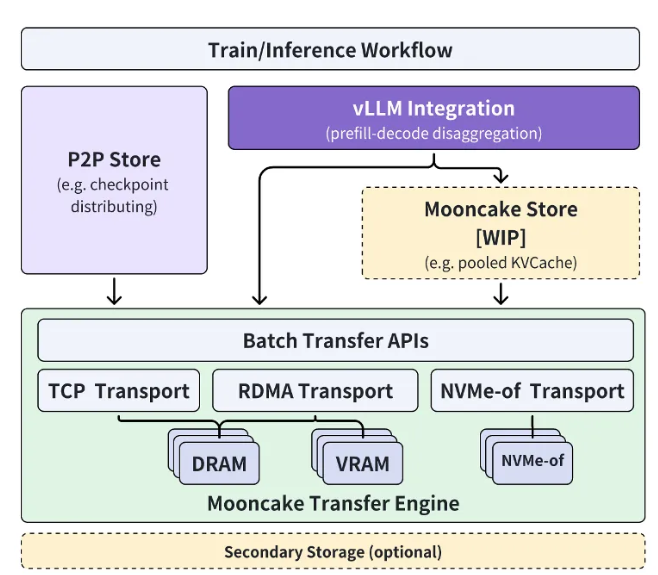
Kimi 公司联合清华大学的 MADSys 实验室,推出了基于 KVCache 的 Mooncake 推理系统设计方案,该方案于2024年6月正式发布。
Mooncake 推理系统通过创新的 PD 分离架构和以存换算为中心的理念,显著提升了推理的吞吐能力,吸引了广泛的行业关注。为了进一步推动这一技术框架的应用与普及,Kimi 与清华大学 MADSys 实验室联合多家企业,如9#AISoft、阿里云、华为存储等,推出了开源项目 Mooncake。11月28日,Mooncake 的技术框架在 GitHub 平台正式上线。
Mooncake 开源项目围绕超大规模 KVCache 缓存池展开,致力于通过分阶段的方式逐步开源高性能的 KVCache 多级缓存 Mooncake Store。同时,该项目将兼容多种推理引擎和底层存储、传输资源。
目前,传输引擎 Transfer Engine 的部分已经在 GitHub 上全球开源。Mooncake 项目的终极目标是为大模型时代构建一个新型高性能内存语义存储的标准接口,并提供相关的参考实现方案。
Kimi 公司的工程副总裁许欣然表示:“通过与清华大学 MADSys 实验室的紧密合作,我们共同打造了分离式的大模型推理架构 Mooncake,实现了推理资源的极致优化。
Mooncake 不仅提升了用户体验,还降低了成本,为处理长文本和高并发需求提供了有效解决方案。” 他期待更多企业和研究机构加入 Mooncake 项目,共同探索更高效的模型推理系统架构,让 AI 助手等基于大模型技术的产品能够惠及更广泛的人群。
项目入口:https://github.com/kvcache-ai/Mooncake
划重点:
🌟 Kimi 与清华大学联合发布 Mooncake 推理系统,提升 AI 推理效率。
🔧 Mooncake 项目已在 GitHub 上开源,旨在构建高性能内存语义存储标准接口。
🤝 期待更多企业和研究机构参与,共同推动 AI 技术进步。