大型语言模型(LLM)的崛起为人工智能应用带来了革命性的变化,然而,它们在处理表格数据方面却存在着明显的不足。 浙江大学计算创新研究院的研究团队针对这一问题,推出了一款名为 TableGPT2的全新模型,它能够直接且高效地整合和处理表格数据,为商业智能(BI)和其他数据驱动型应用开辟了新的可能性。
TableGPT2的核心创新在于其独特的表格编码器,该编码器专门设计用于捕获表格的结构信息和单元格内容信息,从而增强模型处理现实应用中常见的模糊查询、缺失列名和不规则表格的能力。 TableGPT2基于 Qwen2.5架构,并经过了大规模的预训练和微调,涉及超过59.38万个表格和236万个高质量的查询-表格-输出元组,这是先前研究中前所未有的表格相关数据规模。
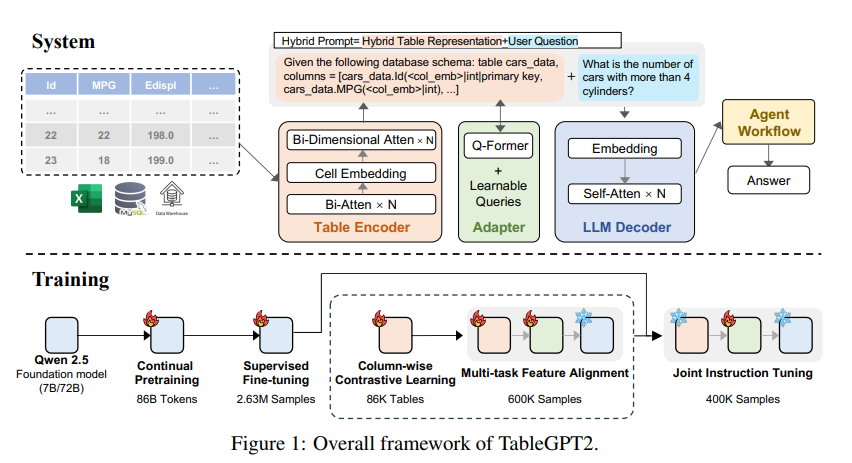
为了提升 TableGPT2的编码和推理能力,研究人员对其进行了持续预训练(CPT),其中80% 的数据是精心注释的代码,以确保其具备强大的编码能力。 此外,他们还收集了大量的推理数据和包含特定领域知识的教科书,以增强模型的推理能力。 最终的 CPT 数据包含860亿个经过严格筛选的词符,这为 TableGPT2处理复杂的 BI 任务和其他相关任务提供了必要的编码和推理能力。
为了解决 TableGPT2在适应特定 BI 任务和场景方面的局限性,研究人员对其进行了监督微调(SFT)。 他们构建了一个涵盖各种关键和现实场景的数据集,包括多轮对话、复杂推理、工具使用和高度业务化的查询。 该数据集结合了人工标注和专家驱动的自动标注流程,确保了数据的质量和相关性。 SFT 过程共使用了236万个样本,进一步完善了模型,使其能够满足 BI 和其他涉及表格的环境的特定需求。
TableGPT2还创新性地引入了语义表格编码器,该编码器将整个表格作为输入,为每一列生成一组紧凑的嵌入向量。 这种架构针对表格数据的独特属性进行了定制,通过双向注意力机制和分层特征提取过程,有效地捕捉了行和列之间的关系。 此外,还采用了列式对比学习方法,鼓励模型学习有意义的、结构感知的表格语义表示。
为了将 TableGPT2与企业级数据分析工具无缝集成,研究人员还设计了代理工作流运行时框架。 该框架包含三个核心组件:运行时提示工程、安全代码沙箱和代理评估模块,共同增强了代理的能力和可靠性。 工作流通过模块化步骤(输入规范化、代理执行和工具调用)支持复杂的数据分析任务,这些步骤协同工作以管理和监控代理的性能。 通过整合用于高效上下文检索的检索增强生成(RAG)和用于安全执行的代码沙箱,该框架确保 TableGPT2在实际问题中提供准确、上下文相关的见解。
研究人员在各种广泛使用的表格和通用基准测试中对 TableGPT2进行了广泛的评估,结果表明,TableGPT2在表格理解、处理和推理方面表现出色,70亿参数模型的平均性能提升了35.20%,720亿参数模型的平均性能提升了49.32%,同时保持了强大的通用性能。 为了进行公平的评估,他们仅将 TableGPT2与开源的基准中性模型(如 Qwen 和 DeepSeek)进行比较,确保了模型在各种任务上的均衡、多功能性能,而不会过度拟合任何单个基准测试。 他们还引入并部分发布了一个新的基准测试——RealTabBench,该基准测试强调非常规表格、匿名字段和复杂查询,更符合现实场景。
尽管 TableGPT2在实验中取得了最先进的性能,但在将 LLM 部署到现实世界的 BI 环境中仍然存在挑战。 研究人员指出,未来的研究方向包括:
特定领域编码:使 LLM 能够快速适应企业特定的领域特定语言(DSL)或伪代码,以更好地满足企业数据基础设施的特定需求。
多代理设计:探索如何有效地将多个 LLM 集成到一个统一的系统中,以处理现实应用的复杂性。
多功能表格处理:改进模型处理不规则表格的能力,例如 Excel 和 Pages 中常见的合并单元格和不一致的结构,以更好地处理现实世界中各种形式的表格数据。
TableGPT2的推出标志着 LLM 在处理表格数据方面取得了重大进展,为商业智能和其他数据驱动型应用带来了新的可能性。 相信随着研究的不断深入,TableGPT2将在未来的数据分析领域发挥越来越重要的作用。
论文地址:https://arxiv.org/pdf/2411.02059v1
