生成式AI发展迅猛,但如何全面评估其性能一直是个难题。各种模型层出不穷,效果也是越来越惊艳。但是,问题来了,怎么评价这些文生图模型的效果呢?
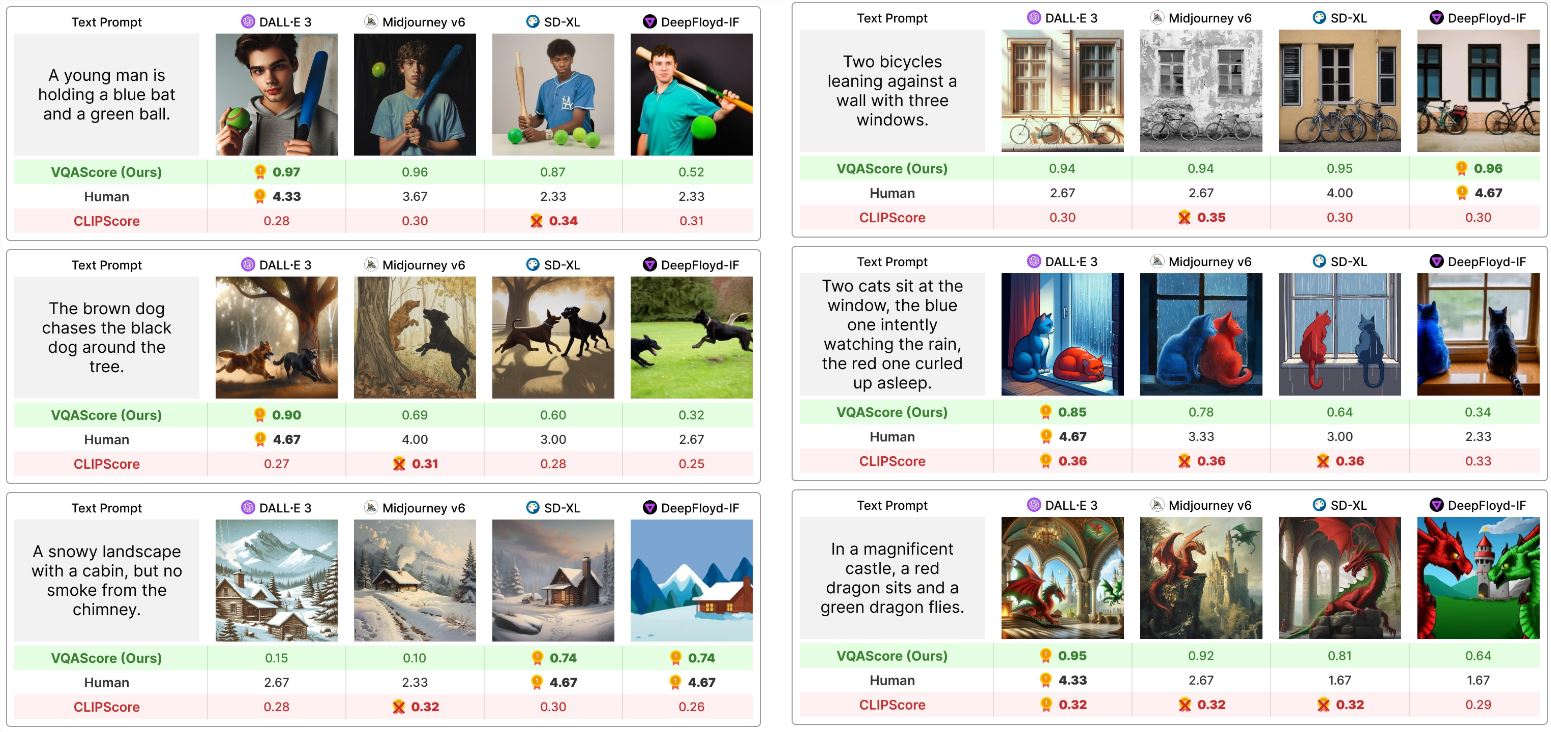
传统的评价方法,要么是靠人眼看,主观性太强;要么是用一些简单的指标,比如CLIPScore,但这些指标往往无法捕捉到复杂文本提示中的细节,比如对象之间的关系、逻辑推理等等。这就导致很多文生图模型的评测结果不准确,甚至会出现一些搞笑的情况,明明生成的图片驴唇不对马嘴,得分却还挺高。
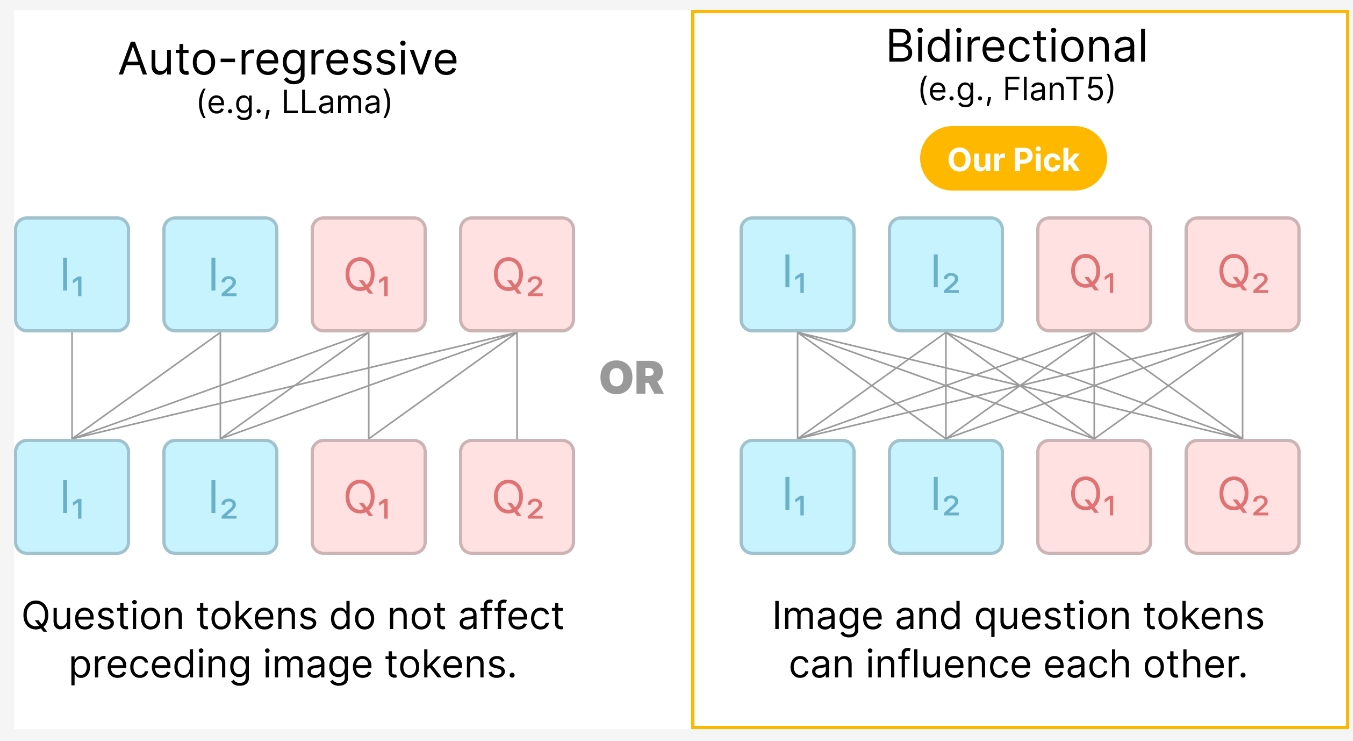
为了解决这个问题,卡耐基梅隆大学和Meta的研究人员最近联手推出了一套新的文生图评测方案——VQAScore。这个方案的核心思想,就是用视觉问答(VQA)模型来给文生图模型打分。
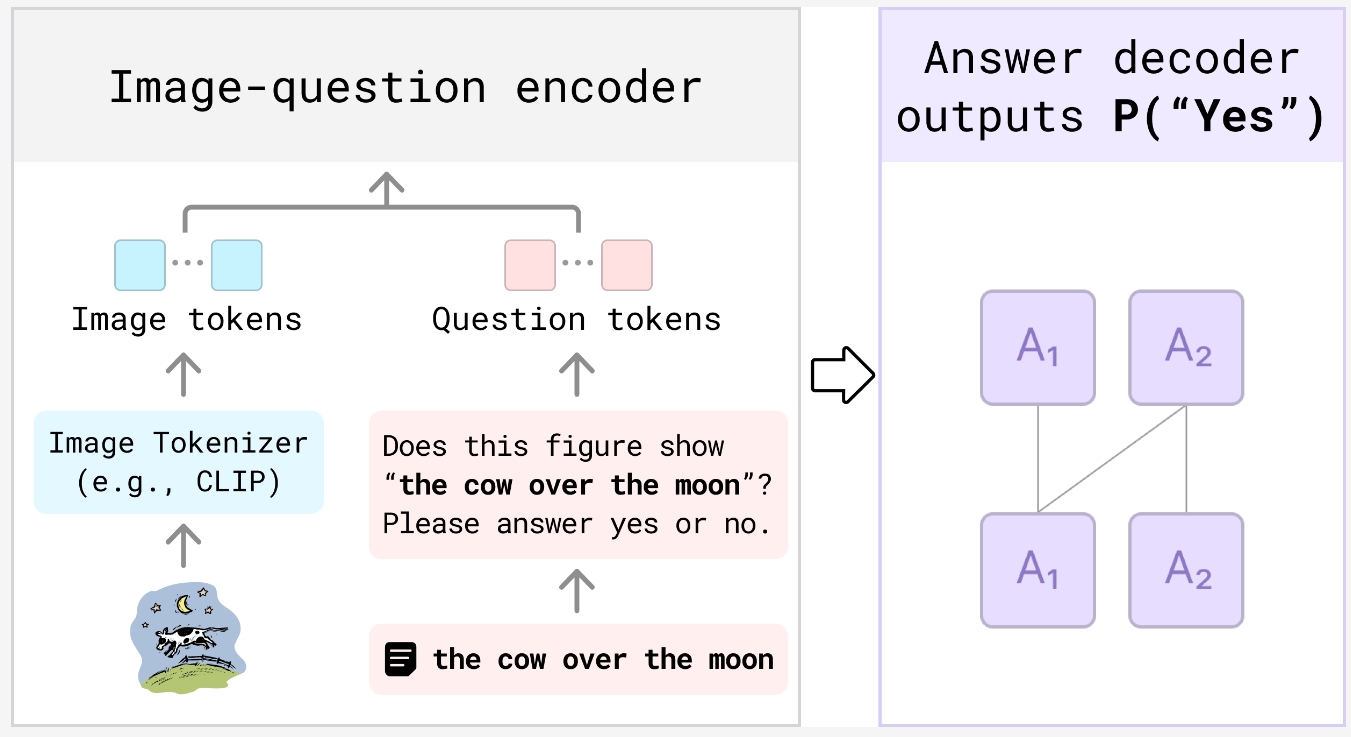
具体来说,VQAScore会先把文本提示转换成一个简单的问题,比如“这张图里有没有一只猫在追一只老鼠?”,然后把生成的图片和这个问题一起丢给VQA模型。VQA模型会根据图片内容判断问题的答案是“是”还是“否”,VQAScore就根据VQA模型判断“是”的概率来给文生图模型打分。
这个方法看起来简单,但效果却出奇的好。研究人员用VQAScore在8个不同的文生图评测基准上进行了测试,结果发现,VQAScore的准确性和可靠性都远超传统的评测方法,甚至可以与那些使用GPT-4V等超大模型的方案相媲美。
更厉害的是,VQAScore不仅可以用来评测文生图,还可以用来评测文生视频和文生3D模型。这是因为VQAScore的核心是VQA模型,而VQA模型本身就可以处理各种类型的视觉内容。

为了进一步推动文生图领域的进步,研究人员还创建了一个新的文生图评测基准——GenAI-Bench。这个基准包含了1600个复杂的文本提示,涵盖了各种视觉语言推理能力,比如比较、计数、逻辑推理等等。研究人员还收集了超过15000个人工标注,用来评估不同文生图模型的效果。
总的来说,VQAScore和GenAI-Bench的出现,为文生图领域带来了新的活力。VQAScore提供了一种更加准确可靠的评测方法,可以帮助研究人员更好地评估不同模型的优缺点。GenAI-Bench则提供了一个更加全面和具有挑战性的评测基准,可以推动文生图模型朝着更加智能和人性化的方向发展。
当然,VQAScore也有一些局限性。目前VQAScore主要依赖于开源的VQA模型,而这些模型的性能还不如GPT-4V等闭源模型。未来,随着VQA模型的不断进步,VQAScore的性能也会进一步提升。
项目地址:https://linzhiqiu.github.io/papers/vqascore/