近日,来自多家中国机构的研究团队成功创建了 “Infinity-MM” 数据集,这是目前最大规模的公开多模态 AI 数据集之一,同时训练出了一款性能卓越的小型新模型 ——Aquila-VL-2B。
该数据集主要包含四大类数据:1000万条图像描述、2440万条一般视觉指令数据、600万条精选高质量指令数据,以及300万条由 GPT-4和其他 AI 模型生成的数据。
在生成方面,研究团队利用现有的开源 AI 模型。首先,RAM++ 模型分析图像并提取重要信息,随后生成相关问题和答案。此外,团队还构建了一种特殊的分类系统,确保生成数据的质量和多样性。
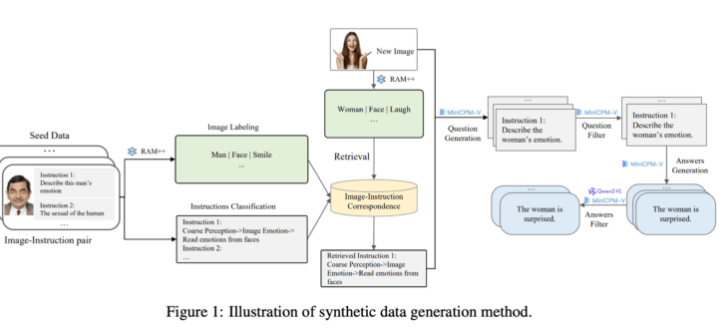
这一合成数据生成方法采用了多层次的处理方式,结合了 RAM++ 和 MiniCPM-V 模型,通过图像识别、指令分类和响应生成,为 AI 系统提供了精准的训练数据。
Aquila-VL-2B 模型基于 LLaVA-OneVision 架构,使用 Qwen-2.5作为语言模型,并采用 SigLIP 进行图像处理。模型的训练分为四个阶段,逐步提高复杂性。在第一阶段,模型学习了基本的图像 - 文本关联;后续阶段则包含一般视觉任务、具体指令的执行,以及最终整合合成生成的数据。的图像分辨率也在训练逐渐提升。
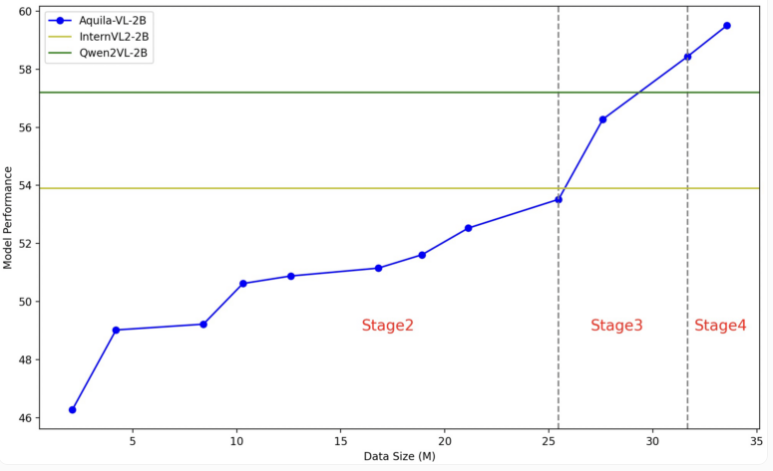
测试中,Aquila-VL-2B 凭借仅有20亿参数的体量,在多模态的 MMStar 基测试中以54.9% 的得分下最佳成绩。此外,在数学任务中,该模型表现尤为突出,在 MathVista 测试得分达59%,远超同类系统。
在通用图像理解的测试中,Aquila-VL-2B 同样表现优异,HallusionBench 得分为43%,MMBench 得分为75.2%。研究人员表示,合成生成数据的加入显著提升了模型的表现,若不使用这些额外数据,模型的平均表现将下降2.4%。
此次研究团队决定将数据集和模型向研究社区开放,训练过程主要使用 Nvidia A100GPU 及中国本土芯片。Aquila-VL-2B 的成功推出,标志着开放源代码模型在 AI 研究中逐渐迎头赶上传统闭源系统的趋势,尤其是在利用合成训练数据方面展现出良好的前景。
Infinity-MM论文入口:https://arxiv.org/abs/2410.18558
Aquila-VL-2B项目入口:https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
划重点:
🌐 数据集 “Infinity-MM” 包含1000万条图像描述和2440万条视觉指令数据。
💡 新模型 Aquila-VL-2B 在多个基准测试中表现优异,打破了同类模型的记录。
📈 合成数据的使用显著提升了模型性能,研究团队决定向社区开放数据集和模型。