大型语言模型如 GPT-4o 和 GPT-4o-mini 的出现,推动了自然语言处理领域的重大进步。这些模型能够生成高质量的响应,进行文档重写,以及提升各类应用的生产力。然而,这些模型面临的一个主要挑战就是响应生成的延迟。在更新博客或优化代码的过程中,这种延迟可能会严重影响用户体验,尤其是在需要多次迭代的场景下,如文档修改或代码重构,用户往往会感到沮丧。

为了应对这一挑战,OpenAI 推出了 “预测输出(Predicted Outputs )” 功能,这一功能显著减少了 GPT-4o 和 GPT-4o-mini 的延迟,通过提供参考字符串来加快处理速度。这项创新的核心在于能够预测出可能的内容,并将其作为模型的起始点,从而跳过已经明确的部分。
通过减少计算量,这种推测解码方法可以将响应时间缩短多达五倍,使 GPT-4o 更适合用于实时任务,例如文档更新、代码编辑和其他需要反复生成文本的活动。这一提升特别有利于开发者、内容创作者以及需要快速更新和减少停机时间的专业人士。
“预测输出” 功能背后的机制是推测解码,这种巧妙的方法允许模型跳过已知或可以预期的内容。
想象一下,如果你在更新一个文档,只有少量编辑需要进行。传统的 GPT 模型会逐字生成文本,并在每个阶段评估每个可能的标记,这可能会非常耗时。然而,借助推测解码,如果可以基于提供的参考字符串预测文本的一部分,模型便可以跳过这些部分,直接进入需要计算的部分。
这一机制显著降低了延迟,使得在之前的响应上快速迭代成为可能。此外,预测输出功能在实时文档协作、快速代码重构或即时文章更新等快速周转的场景中尤其有效。这一功能的引入确保了用户与 GPT-4o 的互动不仅更加高效,也减轻了基础设施的负担,从而降低了成本。
OpenAI 的测试结果显示,GPT-4o 在延迟敏感任务上的表现有了显著提升,常见应用场景中的响应速度提高了多达五倍。通过降低延迟,预测输出不仅节省了时间,也使得 GPT-4o 和 GPT-4o-mini 对更广泛的用户群体更加可及,包括专业开发者、作家和教育工作者。
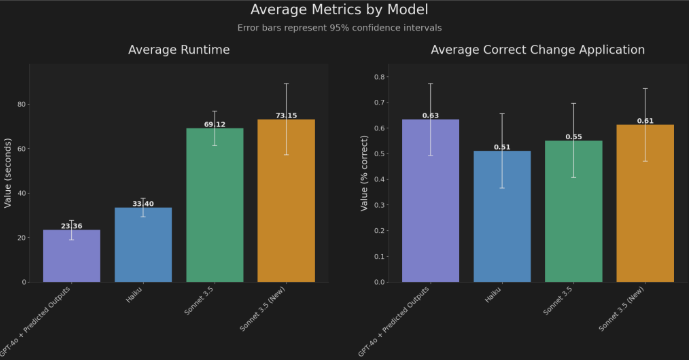
OpenAI 推出的 “预测输出” 功能,标志着在解决语言模型延迟这一重大限制上迈出了重要一步。通过采用推测解码,这一功能在文档编辑、内容迭代和代码重构等任务上显著加快了速度。响应时间的降低为用户体验带来了变革,使得 GPT-4o 在实际应用中依然处于领先地位。
官方功能介绍入口:https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outputs
划重点:
🚀 预测输出功能通过提供参考字符串显著降低了响应延迟,提升了处理速度。
⚡ 该功能使得用户在文档编辑和代码重构等任务中,响应时间提高了多达五倍。
💻 预测输出功能的引入为开发者和内容创作者提供了更高效的工作流程,减轻了基础设施负担。