在AI视觉领域,目标定位一直是个老大难问题。传统的算法就像个“近视眼”,只能粗略地用“框框”圈出目标,却看不清里面的细节。这就好比你跟朋友描述一个人,只说了个大概身高体型,朋友能找到人才怪!
为了解决这个问题,一群来自伊利诺伊理工大学、思科研究院和中佛罗里达大学的大佬们,开发了一套名为SegVG的全新视觉定位框架,号称要让AI从此告别“近视眼”!
SegVG的核心秘诀就是:“像素级”细节!传统的算法只用边界框信息训练AI,相当于只给AI看个模糊的影子。而SegVG则是把边界框信息转换成分割信号,相当于给AI戴上了“高清眼镜”,让AI能看清目标的每一个像素!
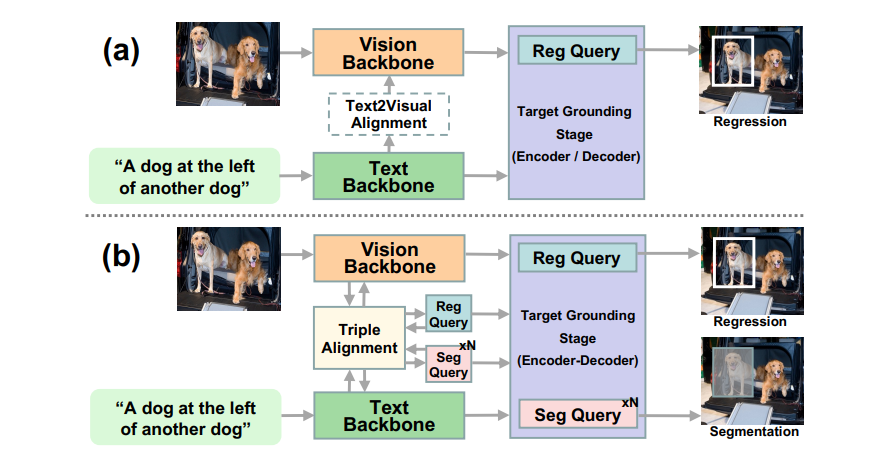
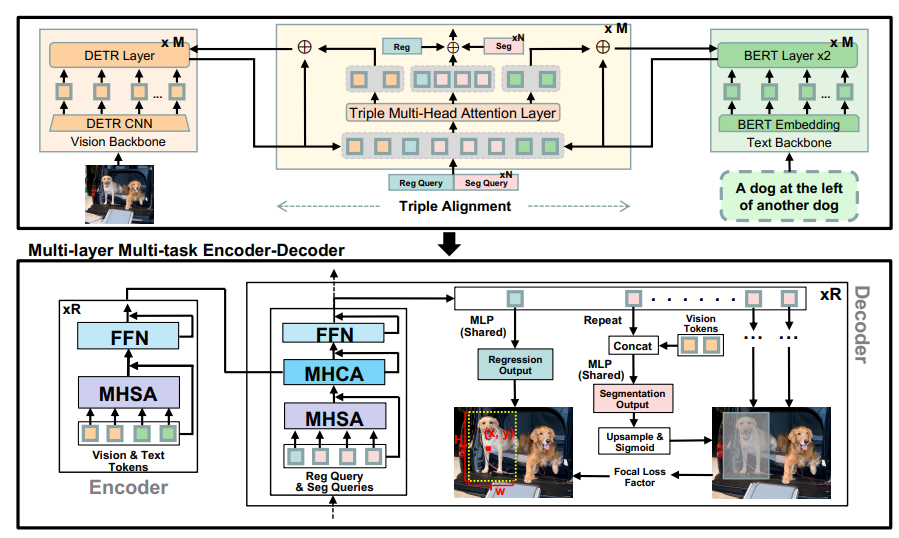
具体来说,SegVG采用了一种“多层多任务编码器-解码器”。这个名字听起来很复杂,其实你可以把它理解成一个超级精密的“显微镜”,里面包含用于回归的查询和多个用于分割的查询。 简单来说,就是用不同的“镜头”分别进行边界框回归和分割任务,反复观察目标,提取更精细的信息。
更厉害的是,SegVG还引入了“三元对齐模块”,相当于给AI配备了“翻译器”,专门解决模型预训练参数和查询嵌入之间“语言不通”的问题。 通过三元注意力机制,这个“翻译器”可以把查询、文本和视觉特征“翻译”到同一个频道,让AI更好地理解目标信息。
SegVG的效果到底如何呢?大佬们在五个常用的数据集上做了实验,结果发现SegVG的表现吊打了一众传统算法! 尤其是在RefCOCO+和RefCOCOg这两个出了名的“难题”数据集上,SegVG更是取得了突破性的成绩!
除了精准定位,SegVG还能输出模型预测的置信度得分。 简单来说,就是AI会告诉你它对自己的判断有多大的把握。这在实际应用中非常重要,比如你想用AI来识别医学影像,如果AI的置信度不高,你就需要人工复核,避免误诊。
SegVG的开源,对于整个AI视觉领域来说都是一个重大利好! 相信未来会有越来越多的开发者和研究人员加入SegVG的阵营,共同推动AI视觉技术的发展。
论文地址:https://arxiv.org/pdf/2407.03200
代码链接:https://github.com/WeitaiKang/SegVG/tree/main