美国初创公司 Useful Sensors 推出了一款名为 Moonshine 的开源语音识别模型。Moonshine 的设计旨在更高效地处理音频数据,相比于 OpenAI 的 Whisper,它在计算资源的使用上更为经济,处理速度快五倍。这一新模型专为在资源有限的硬件上实现实时应用而打造,具有灵活的架构。
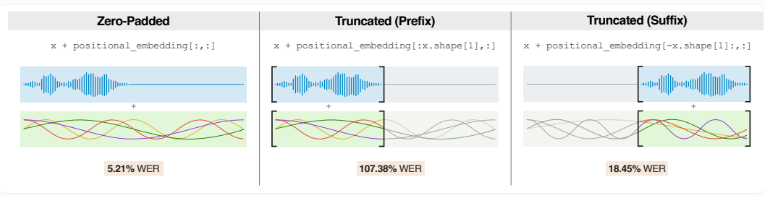
与 Whisper 将音频分为固定的30秒片段处理不同,Moonshine 根据实际音频长度调整处理时间。这使得它在处理较短音频片段时表现出色,减少了由于零填充而产生的处理开销。
Moonshine 有两个版本:小型的 Tiny 版本参数量为2710万,大型的 Base 版本则为6150万。而相比之下,OpenAI 的同类模型参数量更大,Whisper tiny.en 为3780万,base.en 为7260万。
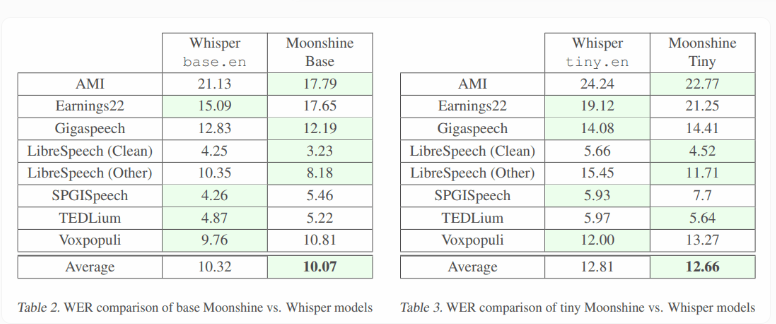
测试结果显示,Moonshine 的 Tiny 模型在准确性上与 Whisper 相当,同时消耗的计算资源更少。在各种音频水平和背景噪声的情况下,Moonshine 的两个版本在词错误率(WER)上都低于 Whisper,显示出较强的性能。
研究团队指出,Moonshine 在处理极短音频片(少于一秒)时仍有提升空间。这些短音频在训练数据中占比较小,增加这类音频片段的训练可能会提升模型的表现。
此外,Moonshine 的离线能力开辟了新的应用场景,之前由于硬件限制而无法实现的应用现在变得可行。与需要较高功耗的 Whisper 不同,Moonshine 适合在智能手机和小型设备(如树莓派)上运行。Useful Sensors 正在利用 Moonshine 开发其英西翻译器 Torre。
Moonshine 的代码已经在 GitHub 上发布,用户需要注意,像 Whisper 这样的 AI 转录系统可能会出现错误。一些研究表明,Whisper 在生成内容时有1.4% 的概率会出现虚假信息,特别是对于有语言障碍的人群,错误率更高。
项目入口:https://github.com/usefulsensors/moonshine
划重点:
🌟 Moonshine 是一款开源语音识别模型,其处理速度比 OpenAI 的 Whisper 快五倍。
🔍 该模型能够根据音频长度调整处理时间,特别适合短音频片段。
🖥️ Moonshine 支持离线运行,适合资源有限的硬件设备使用。