Meta FAIR、加州大学伯克利分校和纽约大学的研究人员联合推出了一种全新技术,名为思维偏好优化(TPO)。这项创新旨在提升大语言模型(LLM)在处理指令时的回答质量。与传统模型只关注最终答案不同,TPO 允许模型在给出最终回答之前,先进行内部思考和反思,从而生成更准确和连贯的回答。
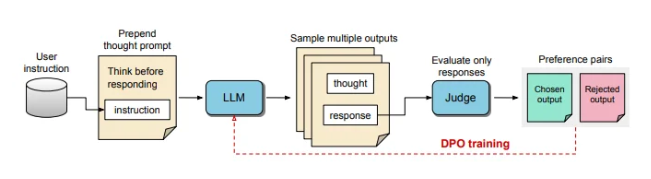
TPO 技术的核心是改进后的连锁思维(CoT)推理方法。这种方法在训练过程中鼓励模型 “思考一下再回答”,帮助它们在提供最终答案之前,构建更有条理的内在思维过程。传统的 CoT 提示有时会导致准确性降低,而且由于缺乏明确的思考步骤,训练起来相当棘手。而 TPO 通过让模型在不暴露中间步骤给用户的情况下,优化和简化它们的思维过程,成功克服了这些挑战。
在 TPO 的训练过程中,首先提示大语言模型生成多种思路,然后再整理出最终回答。随后,这些输出结果会被一个 “评判者” 模型进行评估,以挑选出表现最好的和最差的回答。这些评估结果被用作直接偏好优化(DPO)的 “选择” 和 “拒绝” 对,以此来不断提升模型的响应质量。
通过调整训练提示,TPO 鼓励模型在回答之前进行内部思考。这一过程引导模型优化其回答,使其更加清晰和相关。最终,评估工作由一个基于 LLM 的评判模型来完成,该模型仅对最终答案进行评分,从而独立于隐藏的思考步骤,帮助模型提升回答质量。TPO 还利用直接偏好优化,创建包含隐藏思维的优选和拒绝回答对,经过多轮训练,进一步精细化模型的内部过程。
在对 AlpacaEval 和 Arena-Hard 的基准测试中,TPO 方法的表现优于传统的响应基线,并且比 “思维提示” 的 Llama-3-8B-Instruct 模型更为出色。这一方法的迭代训练优化了思维生成能力,使其最终超越了多个基线模型。值得一提的是,TPO 不仅适用于逻辑和数学任务,还在创意领域如市场营销和健康等指令跟随任务中大展拳脚。
AI 和机器人专家 Karan Verma 在社交平台 X 上分享了他对 “思考型 LLM” 这一概念的看法,表示对此感到非常兴奋,期待这项创新在医疗应用中的潜力,能为患者带来更好的治疗效果。
这种结构化的内在思维过程,使得模型能够更有效地处理复杂的指令,进一步拓展其在需要多层次推理和细致理解的领域的应用,而无需人类提供特定的思维数据。这项研究表明,TPO 有可能使大语言模型在多样化的上下文中更加灵活和高效,适用于那些对响应生成的灵活性和深度有较高要求的领域。