近日,Meta AI 的研究团队与加州大学伯克利分校及纽约大学的研究人员合作,推出了一种名为思维偏好优化(Thought Preference Optimization, TPO)的方法,旨在提升经过指令微调的大型语言模型(LLM)的回应质量。
与传统模型仅关注最终答案不同,TPO 方法允许模型在生成回应前进行内部思考,从而产生更加准确和连贯的回答。
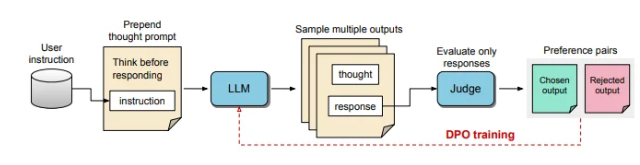
这种新技术结合了改进版的思维链(Chain-of-Thought, CoT)推理方法。在训练过程中,该方法鼓励模型在回应前先进行 “思考”,帮助其构建更为系统的内部思维过程。以往的直接 CoT 提示有时会降低准确性,并且由于缺乏明确的思维步骤,训练过程较为困难。TPO 通过允许模型优化和精简其思维过程,克服了这些局限性,并且在用户面前并不展示中间思维步骤。
在 TPO 的流程中,首先提示大型语言模型生成多个思维过程,然后在形成最终回应之前,对这些输出进行抽样和评估。随后,一个评估模型将对输出进行评分,确定最优和最差的回应。通过将这些输出作为选择和拒绝对进行直接偏好优化(Direct Preference Optimization, DPO),这一迭代训练方法增强了模型生成更相关、高质量回应的能力,从而提高了整体效果。
在这个方法中,训练提示经过调整,鼓励模型在回应前进行内部思考。经过评估的最终回应由一个基于 LLM 的评估模型进行评分,这使得模型能在不考虑隐性思维步骤的情况下,仅依据回应的有效性来提升质量。此外,TPO 利用直接偏好优化创建包含隐性思维的偏好与拒绝回应对,经过多次训练循环来进一步细化模型的内部过程。
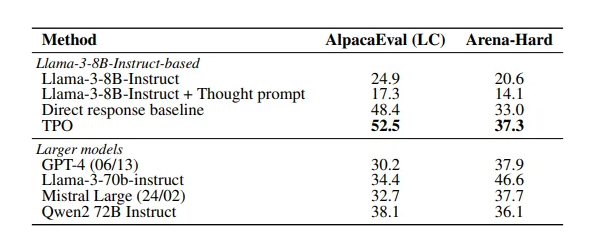
研究结果显示,TPO 方法在多项基准测试中表现优异,超越了多种现有模型。这一方法不仅适用于逻辑和数学任务,也在创意领域如市场营销和健康等指令跟随任务中展现了潜力。
论文:https://arxiv.org/pdf/2410.10630
划重点:
🧠 TPO 技术提升了大型语言模型在生成回应前的思考能力,确保回应更加准确。
📈 通过改进的思维链推理,模型能够优化和精简其内部思维过程,提升回应质量。
💡 TPO 适用于多种领域,不仅限于逻辑和数学任务,还能应用于创意和健康等领域。