近日,AMD 发布了其最新的 Strix Point APU 系列,强调该系列在 AI 大语言模型(LLM)应用中的出色表现,远超英特的 Lunar Lake 系列处理器。AI 工作负载需求的不断增长,硬件的竞争愈发激烈。为了应对市场,AMD 推出了为移动平台设计的 AI 处理器,旨在更高的性能更低的延迟。
AMD 表示,ix Point 系列的 Ryzen AI300处理器在处理 AI LLM 任务时,能够显著提高每秒处理的 Tokens 数量,相较于英特尔的 Core Ultra 258V,Ryzen AI9375的性能提升达到了27%。虽然 Core Ultra7V 并不是 L Lake 系列中最快型号,但其核心和线程数量接近于更高端的 Lunar Lake 处理器,显示出 AMD 产品在此领域的竞争力。
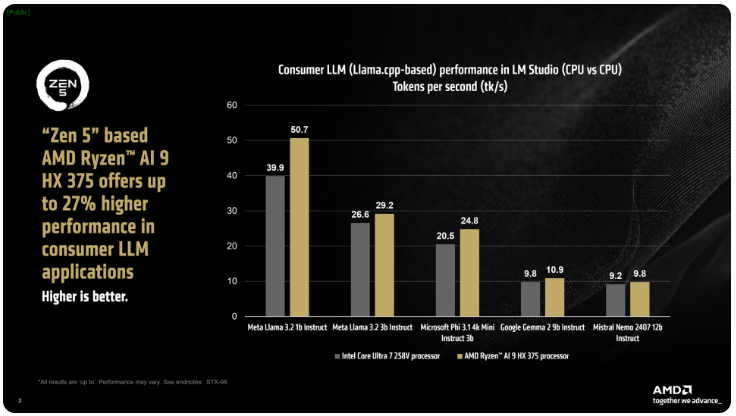
AMD 的 LM Studio 工具一款面向消费者的应用,基 llama.cpp 框架,旨在简化大语言模型的使用。该框架优化了 x86CPU 的性能,虽然不需要 GPU 就能运行 LLM,但使用 GPU 可以进一步加速处理速度。根据测试,Ryzen AI9HX375在 Meta Llama3.21b Instruct 模型中,能够实现35倍更低延迟,每秒处理达到50.7个 Tokens 比之下,Core Ultra7258V 仅为39.9个 Tokens。
不仅如此,Strix Point APU 还配备强大的基于 RDNA3.5构的 Radeon 集成显卡,通过 ulkan API 将任务卸载到 iGPU 上,进一步提升 LLM 的性能。利用变更图形内存(VGM)技术,Ryzen AI300处理器可优化内存分配,提高能效,最终实现达60% 的性能提升。
在对比测试中,AMD 在 Intel AI Playground 平台上使用相同设置,发现 Ryzen AI9HX375在 Microsoft Phi3.1上比 Core Ultra7258V 快87%,而在 Mistral7b Instruct0.3模型中快13%。尽管如此,若与 Lunar Lake 系列中的旗舰产品 Core Ultra9288V 进行比较,结果将更加有趣。目前,AMD 正专注于通过 LM Studio 使大语言模型的使用变得更加普及,旨在让更多非技术用户也能轻松上手。
划重点:
🌟 AMD Strix Point APUs 在 AI LLM 应用中比英特尔 Lunar Lake 提升了27% 的性能。
⚡ Ryzen AI9HX375在 Meta Llama3.2模型中表现3.5倍更低的延迟。
🚀 LM Studio 工具旨在使大语言模型的使用变得更简单,适合非技术用户。