大模型(LLM)如GPT、Llama等在人工智能领域掀起了一场革命,但如何高效地训练这些庞大的模型并使其符合人类价值观仍然是一个难题。
强化学习与人类反馈(RLHF)作为一种重要的LLM训练方法,近年来得到广泛应用,但传统的RLHF框架在灵活性、效率和可扩展性方面存在局限性。
为解决这些问题,字节跳动豆包大模型团队开源了名为HybridFlow的RLHF框架,为LLM训练带来了新的可能性。
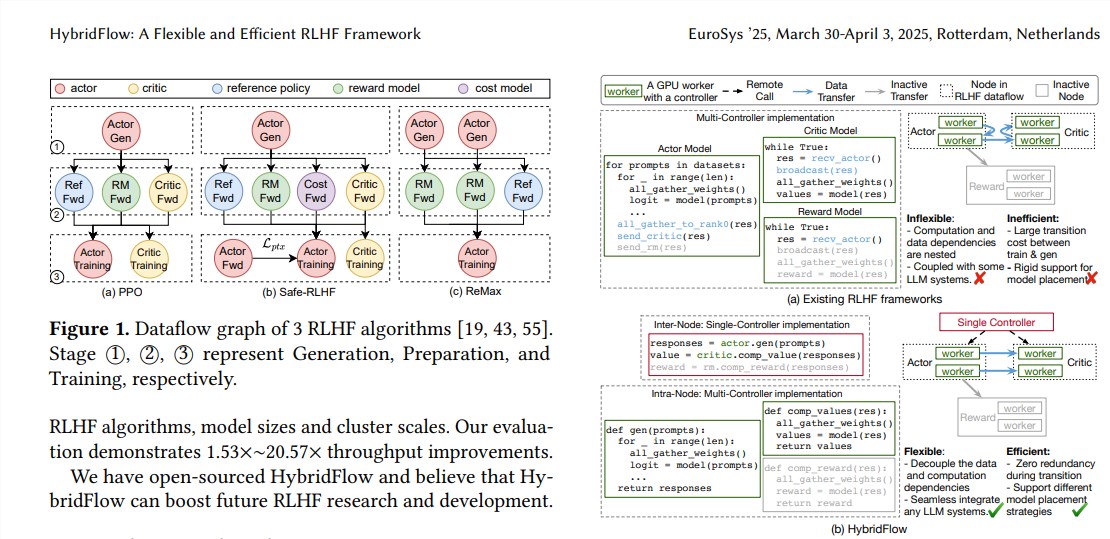
RLHF通常包含三个阶段:
首先,actor模型根据输入的提示生成文本;然后,critic模型、reference模型和reward模型对生成的文本进行评估,并计算出相应的价值、参考概率和奖励值;
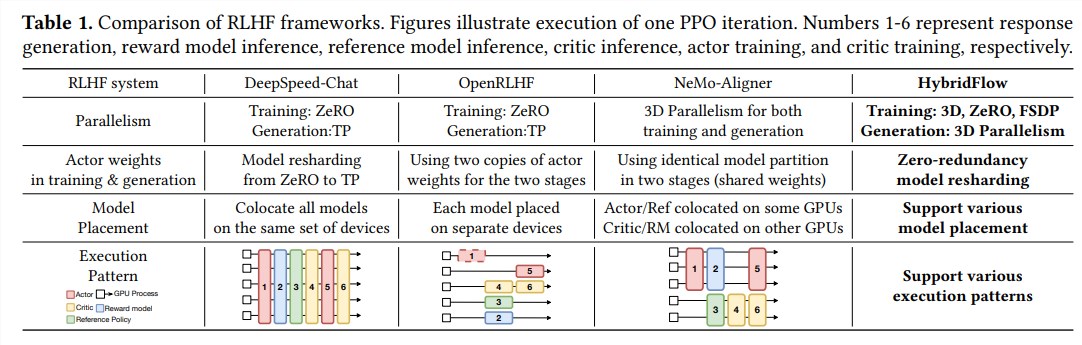
最后,利用这些评估结果对actor模型进行训练,使其生成更符合人类偏好的文本。传统的RLHF框架通常采用单一控制器来管理整个数据流,但这对于需要分布式计算的LLM来说效率低下。
HybridFlow框架创新性地结合了单控制器和多控制器模式,并通过分层的API设计将复杂的计算和数据依赖关系解耦,从而实现RLHF数据流的灵活表示和高效执行。
HybridFlow的优势主要体现在以下三个方面:
灵活支持多种RLHF算法和模型: HybridFlow提供了模块化的API,用户可以轻松地实现和扩展各种RLHF算法,例如PPO、ReMax和Safe-RLHF等。
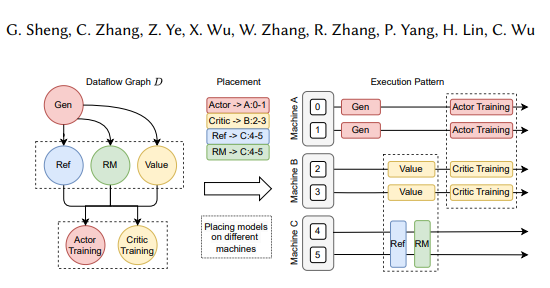
高效的模型权重重组:3D-HybridEngine组件支持actor模型在训练和生成阶段高效地进行模型权重重组,最大限度地减少内存冗余和通信开销。
自动化的模型部署和并行策略选择: Auto Mapping组件可以根据模型负载和数据依赖关系自动将模型映射到不同的设备,并选择最佳的并行策略,从而简化模型部署流程并提升训练效率。
实验结果表明,HybridFlow在运行各种RLHF算法时,吞吐量提升显著,最高可达20.57倍。HybridFlow的开源将为RLHF研究和开发提供强大的工具,推动未来LLM技术的发展。
论文地址:https://arxiv.org/pdf/2409.19256